- Table of Contents
-
- 07-Layer 3 - IP Routing Configuration Guide
- 00-Preface
- 01-IP Routing Basics
- 02-Static Routing Configuration
- 03-RIP Configuration
- 04-OSPF Configuration
- 05-IS-IS Configuration
- 06-BGP Configuration
- 07-Policy-Based Routing Configuration
- 08-Guard Route Configuration
- 09-IPv6 Static Routing Configuration
- 10-RIPng Configuration
- 11-OSPFv3 Configuration
- 12-IPv6 IS-IS Configuration
- 13-IPv6 BGP Configuration
- 14-IPv6 Policy-Based Routing Configuration
- 15-Routing Policy Configuration
- 16-Tunnel End Packets Policy Routing Configuration
- Related Documents
-
| Title | Size | Download |
|---|---|---|
| 06-BGP Configuration | 862.69 KB |
Contents
Settlements for problems in large-scale BGP networks
Configuring BGP basic functions
Specifying the source interface for TCP connections
Controlling route distribution and reception
Configuring BGP route summarization
Advertising a default route to a peer or peer group
Configuring BGP route distribution/reception filtering policies
Enabling BGP and IGP route synchronization
Limiting prefixes received from a peer or peer group
Ignoring the ORIGINATOR_ID attribute of BGP routes
Configuring BGP route dampening
Controlling BGP path selection
Specifying a preferred value for routes received
Configuring preferences for BGP routes
Configure the default local preference
Configuring the next hop attribute
Configuring the AS-PATH attribute
Tuning and optimizing BGP networks
Configuring the BGP keepalive interval and holdtime
Configuring the interval for sending the same update
Allowing establishment of EBGP connection to an indirectly connected peer or peer group
Enabling the BGP ORF capability
Enabling 4-byte AS number suppression
Enabling quick reestablishment of direct EBGP session
Enabling MD5 authentication for TCP connections
Configuring BGP load balancing
Forbidding session establishment with a peer or peer group
Configuring a large scale BGP network
Configuring a BGP route reflector
Configuring a BGP confederation
Enabling Guard route redistribution
Enabling logging of session state changes
Displaying and maintaining BGP
BGP and IGP synchronization configuration
BGP load balancing configuration
BGP route reflector configuration
BGP confederation configuration
BGP path selection configuration
BGP peer relationship not established
Overview
Border Gateway Protocol (BGP) is an exterior gateway protocol (EGP). It is called internal BGP (IBGP) when it runs within an autonomous system (AS) and called external BGP (EBGP) when it runs between ASs.
The current version in use is BGP-4 (RFC 4271).
|
|
NOTE: BGP refers to BGP-4 in this document. |
BGP has the following characteristics:
· Focuses on the control of route propagation and the selection of optimal routes rather than route discovery and calculation, which makes BGP different from interior gateway protocols (IGPs) such as Open Shortest Path First (OSPF) and Routing Information Protocol (RIP).
· Uses TCP to enhance reliability.
· Measures the distance of a route by using a list of ASs that the route must travel through to reach the destination. Therefore, BGP is also called a path-vector protocol.
· Supports classless inter-domain routing (CIDR).
· Reduces bandwidth consumption by advertising only incremental updates, suited to advertise a great amount of routing information on the Internet.
· Eliminates routing loops by adding AS path information to BGP route updates.
· Uses policies to implement flexible route filtering and selection.
· Has good scalability.
BGP speaker and BGP peer
A router running BGP is a BGP speaker. A BGP speaker establishes peer relationships with other BGP speakers to exchange routing information over TCP connections.
BGP peers fall into the following types:
· IBGP peers—Reside in the same AS as the local router.
· EBGP peers—Reside in different ASs from the local router.
BGP message types
BGP has the following types of messages:
· Open—After a TCP connection is established, the first message sent by each side is an Open message for peer relationship establishment.
· Update—The update messages are used to exchange routing information between peers. Each update message can advertise a group of feasible routes with identical attributes, and carry multiple withdrawn routes.
· Keepalive—Keepalive messages are sent between peers to maintain connectivity.
· Route-refresh—A Route-refresh message is sent to a peer to request the specified address family routing information to be resent.
· Notification—A Notification message is sent when an error is detected. The BGP connection is closed immediately after sending it.
BGP path attributes
BGP path attributes are a group of parameters carried in update messages. They give detailed route attributes information that can be used for route filtering and selection.
· ORIGIN
The ORIGIN attribute defines the origin of routing information (how a route became a BGP route). This attribute has the following types:
¡ IGP—Has the highest priority. Routes generated in the local AS have the IGP attribute.
¡ EGP—Has the second highest priority. Routes obtained via EGP have the EGP attribute.
¡ INCOMPLETE—Has the lowest priority. The source of routes with this attribute is unknown. The routes redistributed from other routing protocols have the INCOMPLETE attribute.
· AS_PATH
The AS_PATH attribute identifies the ASs through which a route has passed to reach the destination. When a route is advertised from the local AS to another AS, each passed AS number is added into the AS_PATH attribute, so the receiver can determine ASs to route the message back.
The AS_PATH attribute has the following two types:
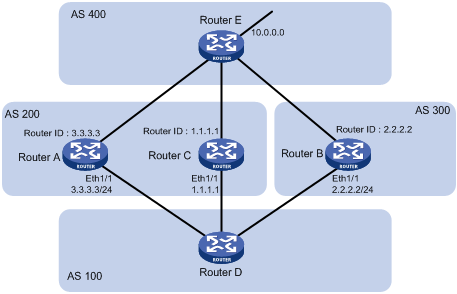
¡ AS_SEQUENCE—Arranges AS numbers in sequence. As shown in Figure 1, the number of the AS closest to the receiver’s AS is leftmost.
¡ AS_SET—Requires no sequence when arranging AS numbers.
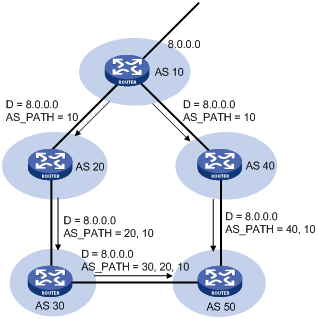
The AS_PATH attribute can be used to implement the following functions:
¡ Avoid routing loops—A BGP router does not receive routes containing the local AS number to avoid routing loops.
¡ Performs route selection—BGP gives priority to the route with the shortest AS_PATH length if other factors are the same. As shown in Figure 1, the BGP router in AS50 gives priority to the route passing AS40 for sending data to the destination 8.0.0.0. In some applications, you can apply a routing policy to control BGP route selection by modifying the AS_PATH length.
¡ Implements route filtering—By configuring an AS path filtering list, you can filter routes based on AS numbers contained in the AS_PATH attribute.
|
|
NOTE: For more information about routing policy and AS path filtering list, see the chapter “Configuring routing policy.” |
· NEXT_HOP
The NEXT_HOP attribute may not be the IP address of a directly connected router. It involves the following types of values, as shown in Figure 2.
¡ When advertising a self-originated route to all BGP peers, a BGP speaker sets the NEXT_HOP for the route to the address of its sending interface.
¡ When sending a received route to an EBGP peer, a BGP speaker sets the NEXT_HOP for the route to the address of the sending interface.
¡ When sending a route received from an EBGP peer to an IBGP peer, a BGP speaker does not modify the NEXT_HOP attribute. If load balancing is configured, the NEXT_HOP attribute of the equal-cost routes will be modified. For load balancing information, see “BGP load balancing.“
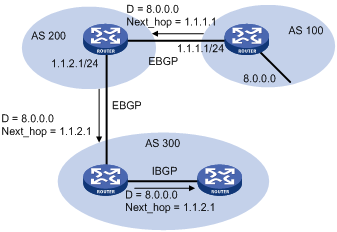
· MED (Multi-Exit-Discriminator)
The MED attribute is exchanged between two neighboring ASs, each of which does not advertise the attribute to any other AS.
Similar to metrics used by IGP, MED is used to determine the best route for traffic going into an AS. When a BGP router obtains multiple routes to the same destination but with different next hops from different EBGP peers, it considers the route with the smallest MED value the best route given that other conditions are the same. As shown in Figure 3, traffic from AS10 to AS20 travels through Router B that is selected according to MED.

In general, BGP compares MEDs of routes received from the same AS only. You can also use the compare-different-as-med command to force BGP to compare MED values of routes received from different ASs.
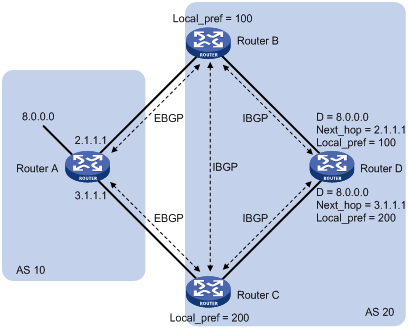
· LOCAL_PREF
The LOCAL_PREF attribute is exchanged between IBGP peers only, and is not advertised to any other AS. It indicates the priority of a BGP router.
LOCAL_PREF is used to determine the best route for traffic leaving the local AS. When a BGP router obtains from several IBGP peers multiple routes to the same destination but with different next hops, it considers the route with the highest LOCAL_PREF value as the best route. As shown in Figure 4, traffic from AS20 to AS10 travels through Router C that is selected according to LOCAL_PREF.
· COMMUNITY
The COMMUNITY attribute identifies the community of BGP routes. A BGP community is a group of routes with the same characteristics. It has no geographical boundaries. Routes of different ASs can belong to the same community.
A route can carry one or more COMMUNITY attribute values (each of which is represented by a four-byte integer). The receiving router processes the route (for example, determining whether to advertise the route and the scope for advertising the route) based on the COMMUNITY attribute values rather than complex filtering rules (for example, ACLs). This simplifies routing policy usage and facilitates management and maintenance.
Well-known community attributes involve the following:
¡ Internet—By default, all routes belong to the Internet community. Routes with this attribute can be advertised to all BGP peers.
¡ No_Export—After received, routes with this attribute cannot be advertised out the local AS or out the local confederation, but can be advertised to other sub ASs in the confederation. For confederation information, see “Settlements for problems in large-scale BGP networks.”
¡ No_Advertise—After received, routes with this attribute cannot be advertised to other BGP peers.
¡ No_Export_Subconfed—After received, routes with this attribute cannot be advertised out the local AS or other sub ASs in the local confederation.
You can define community lists based on the BGP community attribute to filter BGP routes.
· Extended community attribute
To satisfy increasing user demands, BGP defines a new attribute—extended community attribute. The extended community attribute has the following advantages over the community attribute:
¡ The extended community attribute has an eight-byte length.
¡ The extended community attribute supports various types.
You can select an extended community attribute type as needed to implement route filtering and control. This simplifies configuration and management.
The device supports the Route-Target for VPN and Source of Origin (SOO) attributes. For more information, see MPLS Configuration Guide.
BGP route selection
BGP discards routes with unreachable NEXT_HOPs. If multiple routes to the same destination are available, BGP selects the best route in the following sequence:
1. Select the route with the highest Preferred_value.
2. Select the route with the highest LOCAL_PREF.
3. Select the summary route.
4. Select the route with the shortest AS_PATH.
5. Select the IGP, EGP, or INCOMPLETE route in turn.
6. Select the route with the lowest MED value.
7. Select the route learned from EBGP, confederation, or IBGP in turn.
8. Select the route with the smallest next hop metric.
9. Select the route with the shortest CLUSTER_LIST.
10. Select the route with the smallest ORIGINATOR_ID.
11. Select the route advertised by the router with the smallest router ID.
12. Select the route advertised by the peer with the lowest IP address.
|
|
NOTE: · CLUSTER_IDs of route reflectors form a CLUSTER_LIST. If a route reflector receives a route that contains its own CLUSTER ID in the CLUSTER_LIST, the router discards the route to avoid routing loops. · If load balancing is configured, the system selects available routes to implement load balancing. |
BGP route advertisement rules
The current BGP implementation supports the following route advertisement rules:
· When multiple feasible routes to a destination exist, the BGP speaker advertises only the best route to its peers.
· A BGP speaker advertises only routes that it uses.
· A BGP speaker advertises routes learned through EBGP to all BGP peers, including both EBGP and IBGP peers.
· A BGP speaker advertises routes learned through IBGP to EBGP peers, rather than IBGP peers.
· After a BGP speaker establishes a session with a newly connected BGP peer, it advertises all routes to the peer according to the advertisement rules. After that, the BGP speaker advertises only route updates to the peer.
BGP load balancing
BGP implements load balancing by using route recursion and modifying route selection rules.
· Implement BGP load balancing by using route recursion.
The next hop of a BGP route may not be directly connected. One of the reasons is next hops in routing information exchanged between IBGP peers are not modified. The BGP router must find the directly connected next hop via IGP. The matching route with the direct next hop is called the “recursive route.” The process of finding a recursive route is route recursion.
The system supports BGP load balancing based on route recursion. If multiple recursive routes to the same destination are load balanced (suppose three direct next hop addresses), BGP generates the same number of next hops to forward packets. BGP load balancing based on route recursion is always enabled by the system rather than configured by using commands.
· Implement BGP load balancing by modifying route selection rules.
BGP differs from IGP in the implementation of load balancing in the following ways:
¡ IGP routing protocols, such as RIP and OSPF, compute metrics of routes, and then implement load balancing over routes with the same metric and to the same destination. The route selection criterion is metric.
¡ BGP has no route computation algorithm, so it cannot implement load balancing according to metrics of routes. However, BGP has abundant route selection rules, through which, it selects available routes for load balancing and adds load balancing to route selection rules.
BGP implements load balancing only on routes that have the same AS_PATH, ORIGIN, LOCAL_PREF and MED, rather than using the route selection rules as described in “BGP route selection.”
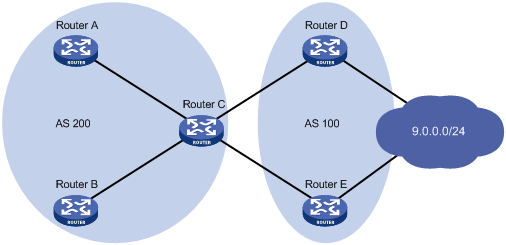
In Figure 5, Router A and Router B are IBGP peers of Router C; Router D and Router E both advertise a route 9.0.0.0 to Router C. If load balancing is configured on Router C, and the two routes have the same AS_PATH attribute, ORIGIN attribute, LOCAL_PREF, and MED, Router C installs both the two routes to its routing table for load balancing. After that, Router C forwards to Router A and Router B the route that has AS_PATH unchanged but has NEXT_HOP changed to Router C; other attributes are those of the best route.
|
|
NOTE: BGP load balancing is applicable between EBGP peers, between IBGP peers, and between confederations. |
Settlements for problems in large-scale BGP networks
A large-scale BGP network has a great number of BGP peers and large routing table size. To facilitate management and improve route distribution efficiency, you can use the following methods:
· Route summarization
Route summarization can reduce the BGP routing table size, and allow BGP routers to advertise only summary routes rather than more specific routes.
The system supports both manual and automatic route summarization. Manual route summarization allows you to determine the attribute of a summary route and whether to advertise the specific routes.
· Route dampening
BGP route dampening solves the issue of route instability such as route flaps—a route comes up and disappears in the routing table frequently.
When a route flap occurs, the routing protocol sends an update to its neighbor, and then the neighbor recalculates routes and modifies the routing table. Frequent route flaps consume large bandwidth and CPU resources, which could affect network operations.
In most cases, BGP is used in complex networks, where route changes are more frequent. To solve the problem caused by route flaps, BGP route dampening is used to suppress unstable routes.
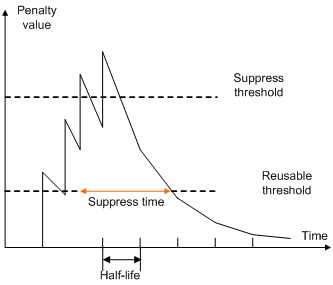
BGP route dampening uses a penalty value to judge the stability of a route. The bigger the value, the less stable the route. Each time a route flap occurs, BGP adds a penalty value (1000, which is a fixed number and cannot be changed) to the route. When the penalty value of the route exceeds the suppress value, the route is suppressed from being added into the BGP routing table or being advertised to other BGP peers.
The penalty value of the suppressed route will decrease to half of the suppress value after a period of time. This period is called “Half-life.” When the value decreases to the reusable threshold value, the route is added into the BGP routing table and advertised to other BGP peers.
Figure 6 BGP route dampening
· Peer group
You can organize BGP peers with the same attributes into a group to simplify their configurations.
When a peer joins the peer group, the peer obtains the same configuration as the peer group. If the configuration of the peer group is changed, the configuration of group members is changed.
· Community
When you define a routing policy, to facilitate configuration and maintenance, you can use the community list and extended community list as filters, instead of IP prefix list, ACL, or AS_PATH. For more information, see “BGP path attributes.”
· Route reflector
IBGP peers must be fully meshed to maintain connectivity. If n routers exist in an AS, the number of IBGP connections is n(n-1)/2. If a large number of IBGP peers exist, large amounts of network and CPU resources are consumed.
Using route reflectors can solve this issue. In an AS, a router acts as a route reflector, and other routers act as clients connecting to the route reflector. The route reflector forwards the routing information received from a client to other clients. In this way, all clients can receive routing information from one another without establishing BGP sessions.
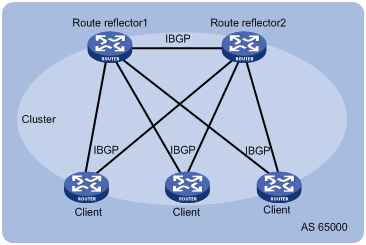
A router that is neither a route reflector nor a client is a non-client, which, as shown in Figure 6, must establish BGP sessions to the route reflector and other non-clients.
Figure 7 Network diagram for a route reflector

The route reflector and clients form a cluster. Typically a cluster has one route reflector. The ID of the route reflector is the Cluster_ID. You can configure more than one route reflector in a cluster to improve network reliability and prevent a single point of failure, as shown in Figure 7. The configured route reflectors must have the same Cluster_ID in order to avoid routing loops.
Figure 8 Network diagram for route reflectors
When the BGP routers in an AS are fully meshed, route reflection is unnecessary because it consumes more bandwidth resources. You can use related commands to disable route reflection instead of modifying network configuration or changing network topology.
|
|
NOTE: After route reflection is disabled between clients, routes can still be reflected between a client and a non-client. |
· Confederation
Confederation is another method to manage growing IBGP connections in an AS. It splits an AS into multiple sub ASs. In each sub AS, IBGP peers are fully meshed, and as shown in Figure 8, intra-confederation EBGP connections are established between sub ASs.
Figure 9 Confederation network diagram
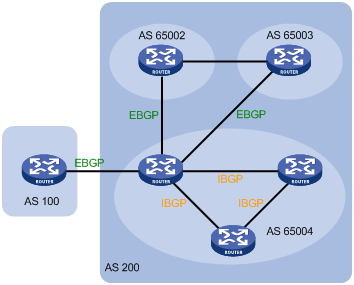
A non-confederation BGP speaker is not required to know sub ASs in the confederation. It considers the confederation as one AS, and the confederation ID as the AS number. In the above figure, AS 200 is the confederation ID.
Confederation has a deficiency. When you change an AS into a confederation, you must reconfigure your routers, and the topology will be changed.
In large-scale BGP networks, both route reflector and confederation can be used.
MP-BGP
Overview
BGP-4 transmits IPv4 unicast routes, but does not transmit routing information of other network layer protocols, such as IPv6.
To support more network layer protocols, IETF extended BGP-4 by introducing Multiprotocol Extensions for BGP-4 (MP-BGP). MP-BGP can transmit routing information of various network layer protocols, for example, IPv4 multicasts, IPv6 unicasts, IPv6 multicasts, and VPNv4 routes.
Routers supporting MP-BGP can communicate with routers not supporting MP-BGP.
MP-BGP extended attributes
Prefixes and next hops are key routing information of network layer protocols. In BGP-4, each update message can carry prefixes of feasible routes in the Network Layer Reachability Information (NLRI) field, prefixes of unfeasible routes in the withdrawn routes field, and next hops in the NEXT_HOP attribute. The NLRI field, withdrawn routes field, and NEXT_HOP attribute cannot be extended to carry information of multiple network layer protocols.
To support multiple network layer protocols, MP-BGP defines the following path attributes:
· MP_REACH_NLRI—Multiprotocol Reachable NLRI, for carrying prefixes of feasible routes and next hops for multiple network layer protocols. Such routes can then be advertised.
· MP_UNREACH_NLRI—Multiprotocol Unreachable NLRI, for carrying prefixes of unfeasible routes for multiple network layer protocols. Such routes can then be withdrawn.
MP-BGP uses these attributes to advertise feasible and unfeasible routes of different network layer protocols. BGP speakers not supporting MP-BGP ignore updates containing these attributes and do not forward them to its peers.
The system supports multiple MP-BGP extensions, including VPN extension, IPv6 extension, and multicast extension.
|
|
NOTE: · For information about the VPN extension application, see MPLS Configuration Guide. · For information about the IPv6 extension application, see the chapter “Configuring IPv6 BGP.” · For information about the multicast extension application, see IP Multicast Configuration Guide. |
Address family
MP-BGP uses address families and subsequent address families to differentiate network layer protocols of routes contained in the MP_REACH_NLRI and MP_UNREACH_NLRI attributes. For example, an Address Family Identifier (AFI) of 2 and Subsequent Address Family Identifier (SAFI) of 1 indicates IPv6 unicast routing information carried in the MP_REACH_NLRI attribute. For address family values, see RFC 1700.
Protocols and standards
· RFC 1700, ASSIGNED NUMBERS
· RFC 1771, A Border Gateway Protocol 4 (BGP-4)
· RFC 2858, Multiprotocol Extensions for BGP-4
· RFC 3392, Capabilities Advertisement with BGP-4
· RFC 2918, Route Refresh Capability for BGP-4
· RFC 2439, BGP Route Flap Damping
· RFC 1997, BGP Communities Attribute
· RFC 2796, BGP Route Reflection
· RFC 3065, Autonomous System Confederations for BGP
· RFC 4271, A Border Gateway Protocol 4 (BGP-4)
· RFC 4360, BGP Extended Communities Attribute
· RFC 4724, Graceful Restart Mechanism for BGP
· RFC 4760, Multiprotocol Extensions for BGP-4
· RFC 5291, Outbound Route Filtering Capability for BGP-4
· RFC 5292, Address-Prefix-Based Outbound Route Filter for BGP-4
BGP configuration task list
In a basic BGP network, you only need to perform the following configurations:
· Enable BGP.
· Configure BGP peers or peer groups.
· Control BGP route generation.
To control BGP route distribution and path selection, you must perform other configurations.
Complete the following tasks to configure BGP:
|
Task |
Remarks |
|
|
Required. |
||
|
Required. H3C recommends that you perform the “Configuring a BGP peer group” task in a large scale BGP network to facilitate your configuration. |
||
|
Optional. |
||
|
Required. Use at least one approach. |
||
|
Optional. |
||
|
Configuring BGP route distribution/reception filtering policies |
||
|
Optional. |
||
|
Optional. |
||
|
Optional. |
||
|
Optional. |
||
|
Optional. |
||
|
Optional. |
||
|
Optional. |
||
|
Optional. |
||
|
Allowing establishment of EBGP connection to an indirectly connected peer or peer group |
Optional. |
|
|
Optional. |
||
|
Optional. |
||
|
Optional. |
||
|
Optional. |
||
|
Optional. |
||
|
Optional. |
||
|
Optional. |
||
|
Optional. |
||
|
Optional. |
||
|
Optional. |
||
|
Optional. |
||
|
Optional. |
||
|
Optional. |
||
|
Optional. |
||
|
Optional. |
||
|
|
NOTE: If you perform configurations on a peer group and peers of the peer group, the last configuration takes effect. |
Configuring BGP basic functions
Enabling BGP
A router ID is the unique identifier of a BGP router in an AS.
· To ensure the uniqueness of a router ID and enhance network reliability, you can specify in BGP view the IP address of a local loopback interface as the router ID.
· If no router ID is specified in BGP view, the global router ID is used.
· If the global router ID is used and then the interface that owns the router ID is removed, the device will select a new router ID.
· If the router ID is specified in BGP view and then the interface that owns the router ID is removed, the device does not select a new router ID; using the undo router-id command in BGP view can make the router select a new router ID.
To enable BGP:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Configure a global router ID. |
router id router-id |
Optional. Not configured by default. If no global router ID is configured, the highest loopback interface IP address—if any—is used as the router ID. If no loopback interface IP address is available, the highest physical interface IP address is used, regardless of the interface status. |
|
3. Enable BGP and enter BGP view. |
bgp as-number |
Not enabled by default. |
|
4. Specify a router ID |
router-id router-id |
Optional. By default, the global router ID is used. |
|
|
NOTE: A router can reside in only one AS, so the router can run only one BGP process. |
Configuring a BGP peer
To configure a BGP peer:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter BGP view or BGP-VPN instance view. |
·
Enter BGP view: ·
Enter BGP-VPN instance view: |
Use either approach. |
|
3. Create a BGP peer and specify its AS number. |
peer ip-address as-number as-number |
By default, no BGP peer is created. |
|
4. Enable the default use of IPv4 unicast address family for the peers that are established using the peer as-number command. |
default ipv4-unicast |
Optional. Enabled by default. This command is not supported in BGP-VPN instance view. |
|
5. Enable a peer. |
peer ip-address enable |
Optional. Enabled by default. |
|
6. Configure a description for a peer. |
peer ip-address description description-text |
Optional. By default, no description is configured for a peer. |
Configuring a BGP peer group
A peer group is a group of peers with the same route selection policy.
In a large-scale network, many peers can use the same route selection policy. You can configure a peer group and add these peers into this group. In this way, peers can share the same policy as the peer group. When the policy of the group is modified, the modification also applies to peers in it, simplifying configuration.
A peer group is an IBGP peer group if peers in it belong to the local AS, and is an EBGP peer group if peers in it belong to different ASs.
|
|
NOTE: If a peer group has peers added, you cannot remove its AS number by using the undo form of the command, and you cannot change its AS number. |
Configuring an IBGP peer group
After you create an IBGP peer group and then add a peer into it, the system creates the peer in BGP view and specifies the local AS number for the peer.
To configure an IBGP peer group:
|
To do… |
Use the command… |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter BGP view or BGP-VPN instance view. |
·
Enter BGP view: · Enter BGP-VPN instance view: |
Use either approach. |
|
3. Create an IBGP peer group. |
group group-name [ internal ] |
N/A |
|
4. Add a peer into the IBGP peer group. |
peer ip-address group group-name [ as-number as-number ] |
By default, no peer exists in the peer group. To use the as-number as-number option, you must specify the local AS number. |
|
5. Enable a peer. |
peer ip-address enable |
Optional. Enabled by default. |
|
6. Configure a description for a peer group. |
peer group-name description description-text |
Optional. By default, no description is configured for the peer group. |
Configuring an EBGP peer group
If peers in an EBGP group belong to the same external AS, the EBGP peer group is a pure EBGP peer group; if not, it is a mixed EBGP peer group.
Use one of the following approaches to configure an EBGP peer group:
· Create the EBGP peer group, specify its AS number, and add peers into it. All the added peers share the same AS number.
· Create the EBGP peer group, specify an AS number for a peer, and add the peer into the peer group.
· Create the EBGP peer group and add a peer into it with an AS number specified.
To configure an EBGP peer group by using the first approach:
|
To do… |
Use the command… |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter BGP view or BGP-VPN instance view. |
·
Enter BGP view: · Enter BGP-VPN instance
view: |
Use either approach. |
|
3. Create an EBGP peer group. |
group group-name external |
By default, no EBGP peer group is created. |
|
4. Specify the AS number for the group. |
peer group-name as-number as-number |
By default, no AS number is specified. |
|
5. Add a peer into the EBGP peer group. |
peer ip-address group group-name [ as-number as-number ] |
By default, no peer exists in the peer group. To use the as-number as-number option, you must specify the AS number configured by the peer group-name as-number as-number command. |
|
6. Enable a peer. |
peer ip-address enable |
Optional. Enabled by default. |
|
7. Configure a description for a peer group. |
peer group-name description description-text |
Optional. By default, no description is configured for the peer group. |
|
|
NOTE: · You can specify an AS number for a peer before adding it into the peer group. The AS number must be the same as that of the peer group. · All of the added peers have the same AS number as that of the peer group. |
To configure an EBGP peer group by using the second approach:
|
To do… |
Use the command… |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter BGP view or BGP-VPN instance view. |
·
Enter BGP view: · Enter BGP-VPN instance view: |
Use either approach. |
|
3. Create an EBGP peer group. |
group group-name external |
N/A |
|
4. Create a BGP peer and specify its AS number. |
peer ip-address as-number as-number |
N/A |
|
5. Add a peer into the EBGP peer group. |
peer ip-address group group-name [ as-number as-number ] |
To use the as-number as-number option, you must specify the AS number configured by the peer ip-address as-number as-number command. |
|
6. Enable the default use of IPv4 unicast address family for the peers that are established using the peer as-number command. |
default ipv4-unicast |
Optional. Enabled by default. This command is not supported in BGP-VPN instance view. |
|
7. Enable a peer. |
peer ip-address enable |
Optional. Enabled by default. |
|
8. Configure a description for a peer group. |
peer group-name description description-text |
Optional. By default, no description is configured for the peer group. |
|
|
NOTE: Peers added in the group can have different AS numbers. |
To configure an EBGP peer group by using the third approach:
|
To do… |
Use the command… |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter BGP view or BGP-VPN instance view. |
·
Enter BGP view: · Enter BGP-VPN instance
view: |
Use either approach. |
|
3. Create an EBGP peer group. |
group group-name external |
N/A |
|
4. Add a peer into the EBGP peer group. |
peer ip-address group group-name as-number as-number |
N/A |
|
5. Enable a peer. |
peer ip-address enable |
Optional. Enabled by default. |
|
6. Configure a description for a peer group. |
peer group-name description description-text |
Optional. By default, no description is configured for the peer group. |
|
|
NOTE: Peers added in the group can have different AS numbers. |
Specifying the source interface for TCP connections
BGP uses TCP as the transport layer protocol. By default, BGP uses the output interface of the optimal route to a peer or peer group as the source interface for establishing TCP connections to the peer or peer group. The primary IP address of the output interface is used for establishing TCP connections. You can specify the source interface (primary IP address) for TCP connections in the following scenarios:
· If the peer’s IP address belongs to an interface indirectly connected to the local router, you must specify that interface as the source interface for TCP connections on the peer. For example, interface A on the local end is directly connected to interface B on the peer. When you execute the peer x.x.x.x as-number as-number command on the local end to specify the BGP peer, and x.x.x.x is not the IP address of interface B, you must use the peer connect-interface command on the peer to specify the interface whose IP address is x.x.x.x as the source interface for establishing a TCP connection.
· If a BGP router has multiple links to a peer, and the source interface fails, BGP has to reestablish TCP connections, causing network oscillation. To enhance stability of TCP connections, H3C recommends that you use a loopback interface as the source interface.
· To establish multiple BGP sessions between two routers, you must specify the source interface for establishing TCP connections to each peer on the local router; otherwise, the local BGP router may fail to establish TCP connections to a peer when using the outbound interface of the best route to the peer as the source interface.
To specify the source interface for TCP connections:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter BGP view or BGP-VPN instance view. |
·
Enter BGP view: ·
Enter BGP-VPN instance view: |
Use either approach. |
|
3. Specify the source interface for establishing TCP connections to a peer or peer group. |
peer { group-name | ip-address } connect-interface interface-type interface-number |
By default, BGP uses the outbound interface of the best route to the BGP peer or peer group as the source interface for establishing a TCP connection to the peer or peer group. |
Controlling route generation
Generating BGP routes can be done in the following ways:
· Configure BGP to advertise local networks.
· Configure BGP to redistribute IGP routes.
Configuration prerequisites
Create and configure a routing policy. For more information, see the chapter “Configuring routing policy.”
Injecting a local network
This task allows you to inject a network in the local routing table to the BGP routing table, so that BGP can advertise the network to BGP peers. The origin attribute of routes advertised in this way is IGP. You can also reference a routing policy to flexibly control route advertisement.
To inject a local network:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter BGP view or BGP-VPN instance view. |
·
Enter BGP view: ·
Enter BGP-VPN instance view: |
Use either approach. |
|
3. Inject a local network to the BGP routing table. |
network ip-address [ mask | mask-length ] route-policy route-policy-name |
Optional. Not injected by default. |
|
|
NOTE: The network to be injected must be available and active in the local IP routing table. |
Redistributing IGP routes
BGP does not find routes by itself. Rather, it redistributes routing information in the local AS from IGPs. During route redistribution, you can configure BGP to filter routing information from specific routing protocols.
By default, BGP does not redistribute default IGP routes. You can use the default-route imported command to redistribute default IGP routes into the BGP routing table.
The origin attribute of routes redistributed from IGPs is INCOMPLETE.
To configure BGP to redistribute IGP routes:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter BGP view or BGP-VPN instance view. |
·
Enter BGP view: ·
Enter BGP-VPN instance view: |
Use either approach. |
|
3. Enable route redistribution from IGP into BGP. |
import-route protocol [ { process-id | all-processes } [ allow-direct | med med-value | route-policy route-policy-name ] * ] |
Not enabled by default. The allow-direct keyword is available only when the specified routing protocol is OSPF. |
|
4. Enable default route redistribution into BGP. |
default-route imported |
Not enabled by default. |
|
|
NOTE: Only active routes can be redistributed. You can use the display ip routing-table protocol command to display route state information. For more information about the display ip routing-table protocol command, see Layer 3—IP Routing Command Reference. |
Controlling route distribution and reception
Configuring BGP route summarization
To reduce the number of routes to be redistributed and the routing table size on medium and large BGP networks, configure route summarization on BGP routers. BGP supports the following summarization modes: automatic and manual. Manual summary routes have a higher priority than automatic ones.
Configuring automatic route summarization
After automatic route summarization is configured, BGP summarizes redistributed IGP subnets to advertise only natural networks. Routes injected with the network command cannot be summarized.
To configure automatic route summarization:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter BGP view or BGP-VPN instance view. |
·
Enter BGP view: ·
Enter BGP-VPN instance view: |
Use either approach. |
|
3. Configure automatic route summarization. |
summary automatic |
Not configured by default. |
Configuring manual route summarization
By configuring manual route summarization, you can summarize both redistributed routes and routes injected using the network command and determine the mask length for a summary route as needed.
To configure BGP manual route summarization:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter BGP view or BGP-VPN instance view. |
·
Enter BGP view: ·
Enter BGP-VPN instance view: |
Use either approach. |
|
3. Configure manual route summarization. |
aggregate ip-address { mask | mask-length } [ as-set | attribute-policy route-policy-name | detail-suppressed | origin-policy route-policy-name | suppress-policy route-policy-name ]* |
Not configured by default. |
Advertising a default route to a peer or peer group
After this task is configured, the BGP router sends a default route with the next hop being itself to the specified peer or peer group.
To advertise a default route to a peer or peer group:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter BGP view or BGP-VPN instance view. |
·
Enter BGP view: ·
Enter BGP-VPN instance view: |
Use either approach. |
|
3. Advertise a default route to a peer or peer group. |
peer { group-name | ip-address } default-route-advertise [ route-policy route-policy-name ] |
Not advertised by default. |
Configuring BGP route distribution/reception filtering policies
Configuration prerequisites
You must configure the following filters as needed:
· ACL
· IP prefix list
· Routing policy
· AS-path ACL
For how to configure an ACL, see ACL and QoS Configuration Guide.
For how to configure an IP prefix list, routing policy, and AS-path ACL, see the chapter “Configuring routing policy.”
Configuring BGP route distribution filtering policies
You can use the following methods to configure BGP route distribution filtering policies:
· Use ACL or IP prefix list to filter routing information advertised to all peers.
· Use routing policy, ACL, AS-path ACL, or IP prefix list to filter routing information advertised to the specified peer or peer group.
You can configure a filtering policy as needed. If several filtering policies are configured, they are applied in the following sequence:
1. filter-policy export
2. peer filter-policy export
3. peer as-path-acl export
4. peer ip-prefix export
5. peer route-policy export
Only routes passing the first policy can go to the next, and only routes passing all the configured policies can be advertised.
To configure BGP route distribution filtering policies:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter BGP view or BGP-VPN instance view. |
·
Enter BGP view: ·
Enter BGP-VPN instance view: |
Use either approach. |
|
3. Configure BGP route distribution filtering policies. |
·
Configure the filtering of redistributed
routes advertised to all peers: ·
Reference a routing policy to filter advertisements
to a peer or peer group: ·
Reference an ACL to filter advertisements to a
peer or peer group: ·
Reference an AS path ACL to filter routing
information sent to a peer or peer group: ·
Reference an IP prefix list to filter routing
information sent to a peer or peer group: |
Configure at least one approach. Not configured by default. |
Configuring BGP route reception filtering policies
You can use the following methods to configure BGP route reception filtering policies:
· Use ACL or IP prefix list to filter routing information received by all peers.
· Use routing policy, ACL, AS-path ACL, or IP prefix list to filter routing information received by the specified peer or peer group.
If several filtering policies are configured, they are applied in the following sequence:
1. filter-policy import
2. peer filter-policy import
3. peer as-path-acl import
4. peer ip-prefix import
5. peer route-policy import
Only routes passing all the configured policies can be received.
To configure BGP route reception filtering policies:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter BGP view or BGP-VPN instance view. |
·
Enter BGP view: ·
Enter BGP-VPN instance view: |
Use either approach. |
|
3. Configure BGP route reception filtering policies. |
·
Filter incoming routes from all peers with an
ACL or IP prefix list: ·
Reference a routing policy to filter routing information
from a peer or peer group: ·
Reference an ACL to filter routing information
from a peer or peer group: ·
Reference an AS path ACL to filter routing
information from a peer or peer group: ·
Reference an IP prefix list to filter routing
information from a peer or peer group: |
Configure at least one approach. By default, no route reception filtering is configured. |
Enabling BGP and IGP route synchronization
Routing information synchronization between IBGP and IGP avoids giving wrong directions to routers outside of the local AS.
By default, upon receiving an IBGP route, a BGP router checks the route’s next hop. If the next hop is reachable, the BGP router advertises the route to EBGP peers. If a non-BGP router works in an AS, it can discard a packet due to an unreachable destination. As shown in Figure 10, Router E has learned a route of 8.0.0.0/8 from Router D via BGP. Router E then sends a packet to 8.0.0.0/8 through Router D, which finds from its routing table that Router B is the next hop (configured using the peer next-hop-local command). Because Router D has learned the route to Router B via IGP, Router D forwards the packet to Router C through route recursion. Router C does not know the route 8.0.0.0/8, so it discards the packet.
Figure 10 IBGP and IGP synchronization
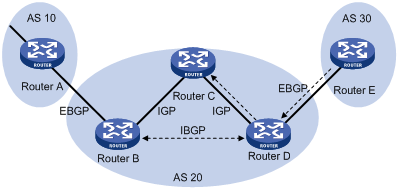
For this example, if synchronization is enabled, and the route 8.0.0.0/24 received from Router B is available in its IGP routing table, Router D advertises the IBGP route when the following conditions are satisfied:
· The next hop of the route is reachable.
· An active route with the same destination network segment is available in the IGP routing table (use the display ip routing-table protocol command to check the IGP route state).
You can disable the synchronization feature in the following situations:
· The local AS is not a transitive AS (AS20 is a transitive AS in the above figure).
· Routers in the local AS are IBGP fully meshed.
To enable BGP and IGP synchronization:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter BGP view. |
bgp as-number |
N/A |
|
3. Enable synchronization between BGP and IGP. |
synchronization |
Not enabled by default |
Limiting prefixes received from a peer or peer group
This task helps avoid attacks that send a large number of BGP routes to the router.
If the number of routes received from a peer or peer group exceeds the specified value, the router can take the following actions based on your configuration:
· Tear down the BGP session to the peer or peer group.
· Display an alarm message, instead of tearing down the BGP session to the peer or peer group.
· Tear down and then reestablishes the BGP session to the peer or peer group.
You can specify the threshold value for the router to display an alarm message. When the ratio of the number of received routes to the maximum number exceeds the percentage value, the router displays an alarm message.
To configure the maximum number of prefixes allowed to be received from a peer or peer group:
|
Step |
Command |
Remarks |
|
|
1. Enter system view. |
system-view |
N/A |
|
|
2. Enter BGP view or BGP-VPN instance view. |
·
Enter BGP view: ·
Enter BGP-VPN instance view: |
Use either approach. |
|
|
3. Specify the maximum number of routes that a router can receive from a peer or peer group. |
peer { group-name | ip-address } route-limit prefix-number [ { alert-only | reconnect reconnect-time } | percentage-value ] * |
By default, the number of routes that a router can receive from a peer or peer group is not limited. |
|
Ignoring the ORIGINATOR_ID attribute of BGP routes
In general, BGP saves the ORIGINATOR ID attribute of BGP routes received from the router reflector to make sure that those routes will not be advertised back to the route reflector. But BGP may need to advertise BGP-VPN routes with different Route Distinguisher (RD) attributes back to the route reflector. To satisfy this requirement, use the peer ignore-originated command to ignore the ORIGINATOR_ID attribute of BGP routes received from the route reflector.
To ignore the ORIGINATOR_ID attribute of BGP routes:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter BGP view or BGP-VPN instance view. |
·
Enter BGP view: ·
Enter BGP-VPN instance view: |
Use either approach. |
|
3. Ignore the ORIGINATOR_ID attribute of BGP routes received from the route reflector. |
peer { group-name | ip-address } ignore-originatorid |
By default, BGP saves the ORIGINATOR ID attribute of received BGP routes. |
|
|
NOTE: · Before you execute the peer ignore-originatorid command, make sure that no routing loop exits among route reflectors in the network. · The peer ignore-originatorid also enables BGP to ignore the CLUSTER_LIST attribute of BGP routes. · For more information about RD, see MPLS Configuration Guide. |
Configuring BGP route dampening
By configuring BGP route dampening, you can suppress unstable routes from being added to the local routing table or from being advertised to BGP peers.
To configure BGP route dampening:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter BGP view or BGP-VPN instance view. |
·
Enter BGP view: ·
Enter BGP-VPN instance view: |
Use either approach. |
|
3. Configure BGP route dampening. |
dampening [ half-life-reachable half-life-unreachable reuse suppress ceiling | route-policy route-policy-name ] * |
Not configured by default. |
Controlling BGP path selection
By configuring BGP path attributes, you can control BGP path selection.
Specifying a preferred value for routes received
This task allows you to modify the preferred value of a route to control BGP path selection.
Among multiple routes that have the same destination/mask and are learned from different peers, the one with the greatest preferred value is selected as the route to the destination.
To specify a preferred value for routes from a peer or peer group:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter BGP view or BGP-VPN instance view. |
·
Enter BGP view: ·
Enter BGP-VPN instance view: |
Use either approach. |
|
3. Specify a preferred value for routes received from a peer or peer group. |
peer { group-name | ip-address } preferred-value value |
Optional. The preferred value is 0 by default. |
Configuring preferences for BGP routes
A router may run multiple routing protocols with each having a preference. If they find the same route, the route found by the routing protocol with the highest preference is selected.
You can use the preference command to modify preferences for external, internal, and local BGP routes.
By default, the preference of an EBGP route is lower than a local route. If a device has an EBGP route and a local route to reach a destination, the device does not select the EBGP route. You can use the network shortcut command to configure an EBGP route as a shortcut route that has the same preference as a local route. The EBGP route is then more likely to become the optimal route.
To configure preferences for BGP routes:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter BGP view or BGP-VPN instance view. |
·
Enter BGP view: ·
Enter BGP-VPN instance view: |
Use either approach. |
|
3. Configure preferences for external, internal, local BGP routes. |
preference { external-preference internal-preference local-preference | route-policy route-policy-name } |
Optional. The default preferences of external, internal, and local BGP routes are 255, 255, and 130, respectively. |
|
4. Increase the preference of a received EBGP route. |
network ip-address [ mask | mask-length ] short-cut |
Optional. By default, an EBGP route received has a preference of 255. |
Configure the default local preference
The local preference is used to determine the best route for traffic leaving the local AS. When a BGP router obtains from several IBGP peers multiple routes to the same destination but with different next hops, it considers the route with the highest local preference as the best route.
This task allows you to specify the default local preference for routes sent to IBGP peers.
To specify the default local preference:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter BGP view or BGP-VPN instance view. |
·
(Approach 1) Enter BGP
view: ·
(Approach 2) Enter BGP-VPN instance view: |
Use either approach. |
|
3. Configure the default local preference. |
default local-preference value |
Optional. 100 by default. |
Configuring the MED attribute
MED is used to determine the best route for traffic going into an AS. When a BGP router obtains from EBGP peers multiple routes to the same destination but with different next hops, it considers the route with the smallest MED value as the best route if other conditions are the same.
Configuring the default MED value
To configure the default MED value:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter BGP view or BGP-VPN instance view. |
·
Enter BGP view: ·
Enter BGP-VPN instance view: |
Use either approach. |
|
3. Configure the default MED value. |
default med med-value |
Optional. 0 by default. |
Enabling the comparison of MED of routes from different ASs
To enable the comparison of MED of routes from different ASs:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter BGP view or BGP-VPN instance view. |
·
Enter BGP view: ·
Enter BGP-VPN instance view: |
Use either approach. |
|
3. Enable the comparison of MED of routes from different Ass. |
compare-different-as-med |
Not enabled by default. |
Enabling the comparison of MEDs for routes on a per-AS basis
Route learning sequence may affect optimal route selection.
Figure 11 Route selection based on MED
As shown in Figure 11, Router D learns network 10.0.0.0 from both Router A and Router B. Because Router B has a smaller router ID, the route learned from it is optimal.
Network NextHop MED LocPrf PrefVal Path/Ogn
*>i 10.0.0.0 2.2.2.2 50 0 300e
* i 3.3.3.3 50 0 200e
When Router D learns network 10.0.0.0 from Router C, it compares the route with the optimal route in its routing table. Because Router C and Router B reside in different ASs, BGP will not compare the MEDs of the two routes. Router C has a smaller router ID than Router B, the route from Router C becomes optimal.
Network NextHop MED LocPrf PrefVal Path/Ogn
*>i 10.0.0.0 1.1.1.1 60 0 200e
* i 10.0.0.0 2.2.2.2 50 0 300e
* i 3.3.3.3 50 0 200e
However, Router C and Router A reside in the same AS, and Router C has a greater MED, so network 10.0.0.0 learned from Router C cannot be optimal.
You can configure the bestroute compare-med command on Router D. After that, Router D puts routes received from the same AS into a group. Router D then selects the route with the lowest MED from the same group, and compares routes from different groups. This mechanism avoids the above-mentioned problem. The following output is the BGP routing table on Router D after the comparison of MED of routes from each AS is enabled. Network 10.0.0.0 learned from Router B is the optimal route.
Network NextHop MED LocPrf PrefVal Path/Ogn
*>i 10.0.0.0 2.2.2.2 50 0 300e
* i 3.3.3.3 50 0 200e
* i 1.1.1.1 60 0 200e
BGP load balancing cannot be implemented because load balanced routes must have the same AS-path attribute.
To enable the comparison of MED of routes from each AS:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter BGP view or BGP-VPN instance view. |
·
Enter BGP view: ·
Enter BGP-VPN instance view: |
Use either approach. |
|
3. Enable the comparison of MEDs for routes on a per-AS basis. |
bestroute compare-med |
Optional. Not enabled by default. |
Enabling the comparison of MED of routes from confederation peers
To enable the comparison of MED of routes from confederation peers:
|
Step |
Command |
Remarks |
|
1. Enter system view |
system-view |
N/A |
|
2. Enter BGP view or BGP-VPN instance view. |
·
(Approach 1) Enter BGP
view: ·
(Approach 2) Enter BGP-VPN instance view: |
Use either approach. |
|
3. Enable the comparison of MED of routes from confederation peers. |
bestroute med-confederation |
Optional. Not enabled by default. |
|
|
NOTE: The MED attributes of routes from confederation peers are not compared if their AS-path attributes contain AS numbers that do not belong to the confederation, such as these three routes: AS-path attributes of them are 65006 65009, 65007 65009, and 65008 65009, and MED values of them are 2, 3, and 1. Because the third route contains an AS number that does not belong to the confederation, the first route becomes the optimal route. |
Configuring the next hop attribute
By default, when advertising routes to an IBGP peer or peer group, a BGP router does not set itself as the next hop. However, to ensure a BGP peer can find the correct next hop in some cases, you need to configure the router as the next hop for routes sent to the peer.
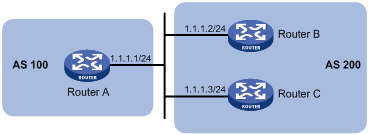
For example, as shown in Figure 12, Router A and Router B establish an EBGP neighbor relationship, and Router B and Router C establish an IBGP neighbor relationship. When Router B advertises a network learned from Router A to Router C, if Router C has no route to IP address 1.1.1.1/24, you need to configure Router B to set itself as the next hop (3.1.1.1/24) for the route to be sent to Router C.
Figure 12 Next hop attribute configuration

If a BGP router has two peers on a common broadcast network, it does not set itself as the next hop for routes sent to an EBGP peer by default. As shown in Figure 13, Router A and Router B establish an EBGP neighbor relationship, and Router B and Router C establish an IBGP neighbor relationship. They are on the same broadcast network 1.1.1.0/24. When Router B sends EBGP routes to Router A, it does not set itself as the next hop by default. However, you can configure Router B to set it as the next hop (1.1.1.2/24) for routes sent to Router A by using the peer next-hop-local command as needed.
Figure 13 Next hop attribute configuration
To configure the next hop attribute:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter BGP view or BGP-VPN instance view. |
·
Enter BGP view: ·
Enter BGP-VPN instance view: |
Use either approach. |
|
3. Specify the router as the next hop of routes sent to a peer or peer group. |
peer { group-name | ip-address } next-hop-local |
Optional. By default, the router sets it as the next hop for routes sent to an EBGP peer or peer group, but does not set it as the next hop for routes sent to an IBGP peer or peer group. |
|
|
NOTE: If you have configured BGP load balancing on a BGP router, the router will set itself as the next hop for routes sent to an IBGP peer or peer group regardless of whether the peer next-hop-local command is configured. |
Configuring the AS-PATH attribute
Permitting local AS number to appear in routes from a peer or peer group
In general, BGP checks whether the AS_PATH attribute of a route from a peer contains the local AS number. If so, it discards the route to avoid routing loops.
However, in certain network environments (a Hub&Spoke network in MPLS L3VPN, for example), the AS_PATH attribute of a route from a peer must be allowed to contain the local AS number; otherwise, the route cannot be advertised correctly.
To permit local AS number to appear in routes from a peer or peer group and specify the appearance times.
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter BGP view or BGP-VPN instance view. |
·
Enter BGP view: ·
Enter BGP-VPN instance view: |
Use either approach. |
|
3. Permit local AS number to appear in routes from a peer or peer group and specify the appearance times. |
peer { group-name | ip-address } allow-as-loop [ number ] |
By default, the local AS number is not allowed to appear in routes from a peer or peer group. |
Disabling BGP from considering AS_PATH during best route selection
To disable BGP from considering AS_PATH during best route selection:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter BGP view. |
bgp as-number |
N/A |
|
3. Disable BGP from considering AS_PATH during best route selection. |
bestroute as-path-neglect |
By default, BGP considers AS_PATH during best route selection. |
Specifying a fake AS number for a peer or peer group
When Router A in AS 2 is moved to AS 3, you can configure Router A to specify a fake AS number of 2 for created connections to EBGP peers or peer groups. In this way, these EBGP peers still think Router A is in AS 2 and need not change their configurations. This feature ensures uninterrupted BGP services.
To specify a fake AS number for a peer or peer group:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter BGP view or BGP-VPN instance view. |
·
Enter BGP view: ·
Enter BGP-VPN instance view: |
Use either approach. |
|
3. Specify a fake AS number for a peer or peer group |
peer { group-name | ip-address } fake-as as-number |
Optional. Not specified by default. |
|
|
NOTE: This command is only applicable to an EBGP peer or peer group. |
Configuring AS number substitution
In MPLS L3VPN, if EBGP is used between PE and CE, sites in different geographical areas must have different AS numbers assigned to ensure correct route advertisement. If CEs in different geographical areas use the same AS number, you must configure the relevant PE to replace the AS number of the CE as its own AS number. This feature is used for route advertisement only.
Figure 14 AS number substitution configuration
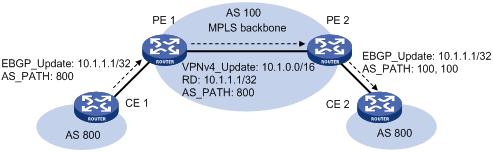
As shown in the above figure, CE 1 and CE 2 use the same AS number of 800. If AS number substitution for CE 2 is configured on PE 2, and PE 2 receives a BGP update sent from CE 1, PE 2 replaces AS number 800 as its own AS number 100. Similar configuration must also be made on PE 1.
To configure AS number substitution for a peer or peer group:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter BGP view or BGP-VPN instance view. |
·
(Approach 1) Enter BGP
view: ·
(Approach 2) Enter BGP-VPN instance view: |
Use either approach. |
|
3. Replace the AS number of a peer or peer group in the AS_PATH attribute as the local AS number. |
peer { group-name | ip-address } substitute-as |
Not configured by default. |
|
|
CAUTION: Improper AS number substitution configuration may cause route loops; use this command with caution. |
Removing private AS numbers from updates to a peer or peer group
Private AS numbers are typically used in test networks, and need not be transmitted in public networks. The range of private AS numbers is from 64512 to 65535.
To remove private AS numbers from updates to a peer or peer group:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter BGP view or BGP-VPN instance view. |
·
Enter BGP view: ·
Enter BGP-VPN instance view: |
Use either approach. |
|
3. Configure BGP to remove private AS numbers from the AS_PATH attribute of updates to a peer or peer group. |
peer { group-name | ip-address } public-as-only |
By default, BGP updates carry private AS numbers. |
Ignoring the first AS number of EBGP route updates
Typically, BGP checks the AS_PATH attribute of a route update received from a peer. If the first AS number is not that of the BGP peer, the BGP router discards the route update.
For some network applications, a BGP router does not add its own AS number to the AS_PATH attribute. In this case, you must configure the ignore-first-as command on the EBGP peer to ignore the first AS number of EBGP route updates.
To ignore the first AS number of EBGP route updates:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter BGP view or BGP-VPN instance view. |
bgp as-number |
N/A |
|
3. Configure BGP to ignore the first AS number of EBGP route updates. |
ignore-first-as |
By default, BGP checks the first AS number of EBGP route updates. |
Tuning and optimizing BGP networks
Configuring the BGP keepalive interval and holdtime
After establishing a BGP session, two routers send keepalive messages at the specified keepalive interval to each other to keep the session.
If a router receives no keepalive or update message from the peer within the holdtime, it tears down the session.
You can configure the keepalive interval and holdtime globally or for a specific peer or peer group. The intervals configured for the specified peer or peer group takes higher priority. The actual keepalive interval and holdtime depend on the following cases:
· If the holdtime settings on the local and peer routers are different, the smaller one is used.
· If the configured keepalive interval is 0 and the negotiated holdtime is not 0, the actual keepalive interval equals one-third of the holdtime.
· If the configured keepalive interval is not 0, the actual keepalive interval is the smaller one between one third of the holdtime and the keepalive interval.
To configure BGP keepalive interval and holdtime:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter BGP view or BGP-VPN instance view. |
·
Enter BGP view: ·
Enter BGP-VPN instance view: |
Use either approach. |
|
3. Configure the global keepalive interval and holdtime. |
timer keepalive keepalive hold holdtime |
Optional. By default, the keepalive interval is 60 seconds, and holdtime is 180 seconds. |
|
4. Configure the keepalive interval and holdtime for a peer or peer group. |
peer { group-name | ip-address } timer keepalive keepalive hold holdtime |
|
|
NOTE: · The maximum keepalive interval should be one third of the holdtime and no less than one second. The holdtime is no less than three seconds unless it is set to 0. · The intervals set with the peer timer command are preferred to those set with the timer command. · If the router has established a BGP session with a peer, you must reset the BGP session to validate the new set timers. · The timer command takes effect for only new BGP sessions. · After you set new intervals with the peer timer command, the existing BGP session is closed at once, and a new session to the peer is negotiated by using the configured holdtime. |
Configuring the interval for sending the same update
A BGP router sends an update message to its peers when a route is changed. If the route changes frequently, the BGP router sends a large number of updates for the route, which can cause route flaps. This task allows you to configure the interval for sending the same update to a peer or peer group, avoiding frequent update sending and route flaps.
To configure the interval for sending the same update to a peer or peer group:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter BGP view or BGP-VPN instance view. |
·
Enter BGP view: ·
Enter BGP-VPN instance view: |
N/A |
|
3. Configure the interval for sending the same update to a peer or peer group. |
peer { group-name | ip-address } route-update-interval interval |
Optional. By default, the intervals for sending the same update to an IBGP peer and an EBGP peer are 15 seconds and 30 seconds, respectively. |
Allowing establishment of EBGP connection to an indirectly connected peer or peer group
Direct physical links must be available between EBGP peers. If not, use the peer ebgp-max-hop command to establish a TCP connection over multiple hops between two peers.
To allow establishment of EBGP session to an indirectly connected peer or peer group:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter BGP view. |
bgp as-number |
N/A |
|
3. Allow the establishment of EBGP connection to an indirectly connected peer or peer group, and specify the maximum hop count. |
peer { group-name | ip-address } ebgp-max-hop [ hop-count ] |
By default, the EBGP connection to an indirectly connected peer or peer group is not allowed to be established. |
|
|
NOTE: · The peer ebgp-max-hop command needs not be configured if the two EBGP peers are directly connected. · If you both reference a routing policy and use the peer { group-name | ip-address } preferred-value value command to set a preferred value for routes from a peer, the routing policy sets a specified non-zero preferred value for routes matching it. Other routes not matching the routing policy uses the value set with the command. If the preferred value specified in the routing policy is zero, the routes matching it will also use the value set with the command. For how to use a routing policy to set a preferred value, see the command peer { group-name | ip-address } route-policy route-policy-name { export | import } in this document. |
Enabling the BGP ORF capability
The BGP Outbound Route Filtering (ORF) feature allows a BGP speaker to send its BGP peer a set of ORFs through route-refresh messages. The peer then applies the ORFs—in addition to its local routing policies (if any)—to filter updates to the BGP speaker, reducing the number of exchanged Update messages and saving network resources.
After you enable the BGP ORF capability, the local BGP router negotiates the ORF capability with the BGP peer through Open messages (determines whether to carry ORF information in messages, and if yes, whether to carry non-standard ORF information in the packets). After completing the negotiation process and establishing the BGP session, the BGP router and its BGP peer can exchange ORF information through specific route-refresh messages.
For the parameters configured on both sides for ORF capability negotiation, see Table 1.
To enable the BGP ORF capability:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter BGP view or BGP-VPN instance view. |
·
Enter BGP view: ·
Enter BGP-VPN instance view: |
Use either approach. |
|
3. Enable BGP route refresh for a peer or peer group. |
peer { group-name | ip-address } capability-advertise route-refresh |
Enabled by default. |
|
4. Enable the non-standard ORF capability for a BGP peer or peer group. |
peer { group-name | ip-address } capability-advertise orf non-standard |
Optional. By default, standard BGP ORF capability defined in RFC 5291 and RFC 5292 is supported. If the peer supports only non-standard ORF, you need to configure this command. |
|
5. Enable the ORF capability for a BGP peer or peer group. |
peer { group-name | ip-address } capability-advertise orf ip-prefix { both | receive | send } |
Disabled by default. |
Table 1 Description of the both, send, and receive parameters and the negotiation result
|
Local parameter |
Peer parameter |
Negotiation result |
|
send |
receive |
The local end can only send ORF information, and the peer end can only receive ORF information. |
|
both |
||
|
receive |
send |
The local end can only receive ORF information, and the peer end can only send ORF information. |
|
both |
||
|
both |
both |
Both the local and peer ends can send and receive ORF information. |
Enabling 4-byte AS number suppression
When a device that supports 4-byte AS numbers sends an Open message for session establishment, the Optional parameters field of the message indicates that the AS number occupies four bytes—in the range of 1 to 4294967295. If the peer device does not support 4-byte AS numbers (for examples, it supports only 2-byte AS numbers), the session cannot be established.
After you enable the 4-byte AS number suppression function, the peer device can then process the Open message even though it does not support 4-byte AS numbers, and the BGP session can be established.
To enable 4-byte AS number suppression:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter BGP view or BGP-VPN instance view. |
·
Enter BGP view: ·
Enter BGP-VPN instance view: |
Use either approach. |
|
3. Enable 4-byte AS number suppression. |
peer { group-name | ip-address } capability-advertise suppress-4-byte-as |
Disabled by default. |
|
|
NOTE: If the peer device supports 4-byte AS numbers, do not enable the 4-byte AS number suppression function; otherwise, the BGP peer relationship cannot be established. |
Enabling quick reestablishment of direct EBGP session
When the link to a directly connected EBGP peer is down, the router, with quick EBGP session reestablishment enabled, will tear down the session to the peer, and then reestablish a session immediately. If the function is not enabled, the router does not tear down the session until the holdtime times out. A route flap will not affect the EBGP session state when the quick EBGP session reestablishment is disabled.
To enable quick reestablishment of direct EBGP session:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
Command |
|
2. Enter BGP view or BGP-VPN instance view. |
·
Enter BGP view: ·
Enter BGP-VPN instance view: |
Use either approach. |
|
3. Enable quick reestablishment of direct EBGP session. |
ebgp-interface-sensitive |
Optional. Not enabled by default. |
Enabling MD5 authentication for TCP connections
You can enable MD5 authentication to enhance security in the following ways:
· Perform MD5 authentication when establishing TCP connections. Only the two parties that have the same password configured can establish TCP connections.
· Perform MD5 calculation on TCP packets to avoid modification to the encapsulated BGP packets.
To enable MD5 authentication for TCP connections:
|
Step |
Command |
Remarks |
|
1. Enter system viewN/A |
system-view |
Command |
|
2. Enter BGP view or BGP-VPN instance view. |
·
Enter BGP view: ·
Enter BGP-VPN instance view: |
Use either approach. |
|
3. Enable MD5 authentication for BGP peers. |
peer { group-name | ip-address } password { cipher | simple } password |
Optional. Not enabled by default. |
Configuring BGP load balancing
If multiple BGP routes that have the same AS_PATH, ORIGIN, LOCAL_PREF, and MED attributes to a destination exist, you can use the balance command to configure the maximum number of BGP routes for load balancing to improve link utilization.
To configure BGP load balancing:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
Command |
|
2. Enter BGP view or BGP-VPN instance view. |
·
Enter BGP view: ·
Enter BGP-VPN instance view: |
Use either approach. |
|
3. Configure the maximum number of BGP routes for load balancing. |
balance number |
By default, load balancing is not enabled. |
Forbidding session establishment with a peer or peer group
This task allows you to temporarily tear down the BGP session to a specific peer or peer group. To recover the session, execute the undo peer ignore command. In this way, you can implement network upgrade and maintenance without deleting and then configuring the peer or peer group.
To forbid session establishment with a peer or peer group:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter BGP view or BGP-VPN instance view. |
·
(Approach 1) Enter BGP
view: ·
(Approach 2) Enter BGP-VPN instance view: |
Use either approach. |
|
3. Forbid session establishment with a peer or peer group. |
peer { group-name | ip-address } ignore |
Optional. Not forbidden by default. |
Configuring BGP soft-reset
After modifying the route selection policy, you must reset BGP sessions to make the new policy take effect and advertise new routes. The router then filters routing information by using the new policy.
The soft-reset feature allows you to refresh the BGP routing table and apply the new route selection policy without tearing down BGP sessions.
The following soft-reset methods are available:
· Automatic soft-reset—After a policy is modified, the router advertises a Route-refresh message to the peers, which then resend their routing information to the router. After receiving the routing information, the router filters the routing information by using the new policy.
This method requires that both the local router and the peer support route refresh.
· Manual soft-reset—Use the peer keep-all-routes command to save all route updates from the peer. After modifying the route selection policy, use the refresh bgp command to filter routing information by using the new policy.
This method uses more memory resources to save routes, and does not require that the local router and the peer support route refresh.
Configuring automatic soft-reset
After route refresh is enabled for peers and a policy is modified, the router advertises a route-refresh message to the peers, which then resend their routing information to the router. After receiving the routing information, the router performs dynamic route update by using the new policy.
To enable BGP route refresh for a peer or peer group:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter BGP view or BGP-VPN instance view. |
·
Enter BGP view: ·
Enter BGP-VPN instance view: |
Use either approach. |
|
3. Enable BGP route refresh for a peer or peer group. |
peer { group-name | ip-address } capability-advertise route-refresh |
Optional. Enabled by default. |
Configuring manual soft-reset
If a BGP peer does not support route-refresh, you must save updates from the peer on the local router by using the peer keep-all-routes command, and use the refresh bgp command to refresh the BGP routing table.
Following these steps to save all route updates from a peer or peer group:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter BGP view or BGP-VPN instance view. |
·
Enter BGP view: ·
Enter BGP-VPN instance view: |
Use either approach. |
|
3. Disable BGP route-refresh for a peer or peer group. |
·
Disable BGP route-refresh: ·
Disable multi-protocol
extension capability: |
Use either approach. By default, BGP route-refresh and multi-protocol extension capability is enabled for a peer or peer group. The peer capability-advertise conventional command is not supported in BGP-VPN instance view. |
|
4. Save all route updates from a peer or peer group. |
peer { group-name | ip-address } keep-all-routes |
Not saved by default. |
|
5. Return to user view. |
return |
N/A |
|
6. Perform manual soft-reset on BGP sessions. |
refresh bgp { all | ip-address | group group-name | external | internal } { export | import } |
N/A |
|
|
NOTE: · Use the peer keep-all-routes command to save all route updates from a peer or peer group, regardless of whether the routes have passed the configured routing policy. When you soft-restes the BGP connections, use this information to regenerate BGP routes. · Using this function can refresh the BGP routing table without tearing down BGP sessions and apply a newly configured routing policy. · To perform BGP soft reset, all routers in the network must support route-refresh. If a router not supporting route-refresh exists in the network, you must configure the peer keep-all-routes command to save all route updates before performing soft reset. · If the BGP peer does not support route-refresh and the peer keep-all-routes command is not configured on the local end, you must decide whether to manually disconnect the session with the peer to learn routes again according to the impact of the new policy. |
Configuring a large scale BGP network
In a large-scale BGP network, configuration and maintenance may become difficult due to large numbers of BGP peers. To facilitate configuration, you can configure peer group, community, route reflector, or confederation as needed. For how to configure a peer group, see “Configuring a BGP peer group.”
Configuration prerequisites
Peering nodes are accessible to each other at the network layer.
Configuring BGP community
By default, a router does not send the community or extended community attribute to its peers or peer groups. When the router receives a route carrying the community or extended community attribute, it removes the attribute before advertising the route to its peers or peer groups.
This task allows you to enable a router to advertise the community or extended community attribute to its peers, so that you can implement route filtering and control. By using this configuration together with a routing policy, you can add and modify the community or extended community attribute of a route. For more information about routing policy, see the chapter “Configuring routing policy.”
To configure BGP community:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter BGP view or BGP-VPN instance view. |
·
Enter BGP view: ·
Enter BGP-VPN instance view: |
Use either approach. |
|
3. Advertise the community attribute or extended community attribute to a peer or peer group. |
·
Advertise the community attribute to a peer or
peer group: ·
Advertise the extended community attribute to
a peer or peer group: |
Use either approach. Not configured by default. |
|
4. Apply a routing policy to routes advertised to a peer or peer group. |
peer { group-name | ip-address } route-policy route-policy-name export |
Not configured by default. |
Configuring a BGP route reflector
If an AS has many BGP routers, you can configure them as a cluster and configure one of them as a route reflector and others as clients to reduce IBGP connections.
To enhance network reliability and prevent single point of failure, specify multiple route reflectors for a cluster. The route reflectors in the cluster must have the same cluster ID to avoid routing loops.
To configure a BGP route reflector:
|
Step |
Command |
Remarks |
|
1. Enter system view |
system-view |
N/A |
|
2. Enter BGP view or BGP-VPN instance view. |
·
Enter BGP view: ·
Enter BGP-VPN instance view: |
Use either approach. |
|
3. Configure the router as a route reflector and specify a peer or peer group as its client. |
peer { group-name | ip-address } reflect-client |
Not configured by default. The peer reflect-client command can be configured in both BGP view and BGP-VPNv4 subaddress family view. In BGP view, the command enables the router to reflect routes of the public network; in BGP-VPNv4 subaddress family view, the command enables the router to reflect routes of the private network. (You can enter BGP-VPNv4 subaddress family view by executing the ipv4-family vpnv4 command in BGP view. For more information about the ipv4-family vpnv4 command, see MPLS Command Reference.) |
|
4. Enable route reflection between clients. |
reflect between-clients |
Optional. Enabled by default. |
|
5. Configure the cluster ID of the route reflector. |
reflector cluster-id cluster-id |
Optional. By default, a route reflector uses its router ID as the cluster ID. |
|
|
CAUTION: In general, it is not required to make clients of a route reflector fully meshed. The route reflector forwards routing information between clients. If clients are fully meshed, disable route reflection between clients to reduce routing costs. |
Configuring a BGP confederation
Configuring a BGP confederation is another way for reducing IBGP connections in an AS.
A confederation contains sub ASs. In each sub AS, IBGP peers are fully meshed. Between sub ASs, EBGP connections are established.
If routers not compliant with RFC 3065 exist in the confederation, use the confederation nonstandard command to make the local router compatible with these routers.
Configuring a BGP confederation
After you split an AS into multiple sub ASs, you can configure a router in a sub AS in the following way:
1. Enable BGP and specify the AS number of the router. For more information, see “Enabling BGP.”
2. Specify the confederation ID. From an outsider’s perspective, the sub ASs of the confederation is a single AS, which is identified by the confederation ID.
3. If the router needs to establish EBGP connections to other sub ASs, you must specify the peering sub ASs in the confederation.
A confederation contains a maximum of 32 sub ASs. The AS number of a sub AS is effective only in the confederation.
To configure a BGP confederation:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter BGP view. |
bgp as-number |
N/A |
|
3. Configure a confederation ID. |
confederation id as-number |
Not configured by default |
|
4. Specify peering sub ASs in the confederation. |
confederation peer-as as-number-list |
Not configured by default |
Configuring confederation compatibility
If some other routers in the confederation do not comply with RFC 3065, you must enable confederation compatibility to allow the router to work with those routers.
|
Step |
Command |
Remarks |
|
1. Enter system view |
system-view |
N/A |
|
2. Enter BGP view. |
bgp as-number |
N/A |
|
3. Enable compatibility with routers not compliant with RFC 3065 in the confederation. |
confederation nonstandard |
Optional Not enabled by default |
Configuring BGP GR
Graceful Restart (GR) ensures the continuity of packet forwarding when BGP restarts or an active/standby switchover occurs:
· GR Restarter—Graceful restarting router. It must be GR capable.
· GR Helper—A neighbor of the GR Restarter. It helps the GR Restarter to complete the GR process.
Following is a GR process:
1. A BGP GR Restarter and Helper exchange Open messages with GR capability. If both parties have the GR capability, the session established between them is GR capable.
2. When an active/standby switchover occurs on the GR Restarter, the GR Restarter does not remove existing route entries; it still uses these routes for packet forwarding. The GR Helper marks all routes learned from the GR Restarter as stale, instead of deleting them; it still uses these routes for packet forwarding. During the GR process, packet forwarding is not interrupted.
3. After the active/standby switchover is completed, the GR Restarter reestablishes a GR session with the GR Helper. If no BGP session is established within the interval set with the graceful-restart timer restart command, the GR Helper removes the stale routes.
4. If a BGP session is established, routing information is exchanged between them for the GR Restarter to retrieve route entries, and for the GR Helper to recover stale routes. You can control the routing information exchange interval by configuring the graceful-restart timer wait-for-rib command. If routing information exchange is not completed within the time, the GR Restarter does not receive new routes; instead, it updates its routing table and forwarding table with the BGP routes already learned to complete BGP routing convergence. The GR Helper then removes the state routes.
|
|
NOTE: A device can act as a GR Restarter and GR Helper at the same time. |
Perform the following configuration on the GR Restarter and GR Helper, respectively.
To configure BGP GR:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enable BGP, and enter its view. |
bgp as-number |
N/A |
|
3. Enable GR Capability for BGP. |
graceful-restart |
Disabled by default |
|
4. Configure the maximum time allowed for the peer to reestablish a BGP session. |
graceful-restart timer restart timer |
Optional 150 seconds by default |
|
5. Configure the maximum time to wait for the End-of-RIB marker. |
graceful-restart timer wait-for-rib timer |
Optional 180 seconds by default |
|
|
NOTE: · GR Restarter sends the maximum time allowed for the peer to reestablish a BGP session to the GR Helper in an Open message. When the GR Helper detects that the session to the GR Restarter is down, it waits until the time advertised by the GR Restarter expires for a new session to be established. · In general, the maximum time allowed for the peer to reestablish a BGP session must be less than the Holdtime carried in the Open message. · The End-Of-RIB (End of Routing-Information-Base) indicates the end of route updates. · The maximum time to wait for the End-of-RIB marker configured on the local end is not advertised to the peer; the setting is used to control the time on the local end to receive updates from the peer end. |
Enabling Guard route redistribution
Guard routes use NULL 0 as the outbound interface.
You can enable Guard route redistribution into BGP on a Guard device, After that, when a Guard route is configured on the Guard device, the Guard route is redistributed into the BGP route table and advertised to a BGP peer. In this way, traffic that is received by the BGP peer and destined to the destination of the Guard route is diverted to the Guard device, which then handles the traffic as configured. For detailed Guard route information and configuration, see the chapter “Configuring Guard route.”
To enable Guard route redistribution into BGP:
|
Step |
Command |
Remarks |
|
|
1. Enter system view. |
system-view |
N/A |
|
|
2. Enter BGP view. |
bgp as-number |
N/A |
|
|
3. Enable Guard route redistribution into BGP. |
import-route guard [ med med-value | route-policy route-policy-name ] * |
Disabled by default |
|
|
|
NOTE: · A Guard route configured on a router is neither installed into the FIB nor used by the router to forward IP packets. · Guard routes redistributed into the BGP route table have an ORIGIN attribute of incomplete. |
Enabling trap
After trap is enabled for BGP, BGP generates Level-4 traps to report important events. The generated traps are sent to the information center of the device. The output rules of the traps—whether to output the traps and the output direction—are determined according to the information center configuration. (For information center configuration, see Network Management and Monitoring Configuration Guide.)
To enable trap:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enable trap for BGP. |
snmp-agent trap enable bgp |
Optional Enabled by default |
Enabling logging of session state changes
This task allows you to enable BGP to log session establishment and disconnection events. You can use the display bgp ipv4 peer log-info command to view the log information.
To enable the logging of session state changes:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter BGP view. |
bgp as-number |
N/A |
|
3. Enable the logging of session state changes globally. |
log-peer-change |
Optional Enabled by default |
|
4. Enter BGP-VPN instance view. |
ipv4-family vpn-instance vpn-instance-name |
Optional |
|
5. Enable the logging of session state changes for a peer or peer group. |
peer { group-name | ip-address } log-change |
Optional Enabled by default |
Configuring BFD for BGP
BGP maintains neighbor relationships based on the keepalive timer and holdtime timer, which are set in seconds. BGP defines that the holdtime interval must be at least three times the keepalive interval. This mechanism makes link failure detection rather slow; once a failure occurs on a high-speed link, a large quantity of packets will be dropped. BFD is introduced to solve this problem. It detects links between neighbors quickly to reduce convergence time upon link failures.
To enable BFD for a BGP peer:
|
Step |
Command |
Remarks |
|
1. Enter system view. |
system-view |
N/A |
|
2. Enter BGP view or BGP-VPN instance view. |
·
Enter BGP view: ·
Enter BGP-VPN instance view: |
Use either approach. |
|
3. Enable BFD for the specified BGP peer. |
peer ip-address bfd |
By default, no BGP peer is enabled. |
Displaying and maintaining BGP
Displaying BGP
Resetting BGP session
|
Task |
Command |
Remarks |
|
Reset the specified BGP session. |
reset bgp { as-number | ip-address | all | external | group group-name | internal } |
Available in user view |
|
Reset all IPv4 unicast BGP sessions. |
reset bgp ipv4 all |
Clearing BGP information
|
Task |
Command |
Remarks |
|
Clear dampened BGP routing information and release suppressed routes. |
reset bgp dampening [ ip-address [ mask | mask-length ] ] |
Available in user view |
|
Clear route flap information. |
reset bgp flap-info [ ip-address [ mask-length | mask ] | as-path-acl as-path-acl-number | regexp as-path-regular-expression ] reset bgp peer-ip-address flap-info |
BGP configuration examples
|
|
NOTE: By default, Ethernet, VLAN, and aggregate interfaces are down. Before configuring these interfaces, bring them up by using the undo shutdown command. |
BGP basic configuration
Network requirements
In Figure 15, run EBGP between Switch A and Switch B, and run IBGP between Switch B and Switch C so that Switch C can access the network 8.1.1.0/24 connected to Switch A.
Configuration procedure
1. Configure IP addresses for interfaces. (Details not shown)
2. Configure IBGP:
¡ To prevent route flapping caused by port state changes, this example uses loopback interfaces to establish IBGP connections.
¡ Because loopback interfaces are virtual interfaces, use the peer connect-interface command to specify the loopback interface as the source interface for establishing BGP connections.
¡ Enable OSPF in AS 65009 to make sure that Switch B can communicate with Switch C through loopback interfaces.
# Configure Switch B.
<SwitchB> system-view
[SwitchB] bgp 65009
[SwitchB-bgp] router-id 2.2.2.2
[SwitchB-bgp] peer 3.3.3.3 as-number 65009
[SwitchB-bgp] peer 3.3.3.3 connect-interface loopback 0
[SwitchB-bgp] quit
[SwitchB] ospf 1
[SwitchB-ospf-1] area 0
[SwitchB-ospf-1-area-0.0.0.0] network 2.2.2.2 0.0.0.0
[SwitchB-ospf-1-area-0.0.0.0] network 9.1.1.1 0.0.0.255
[SwitchB-ospf-1-area-0.0.0.0] quit
[SwitchB-ospf-1] quit
# Configure Switch C.
<SwitchC> system-view
[SwitchC] bgp 65009
[SwitchC-bgp] router-id 3.3.3.3
[SwitchC-bgp] peer 2.2.2.2 as-number 65009
[SwitchC-bgp] peer 2.2.2.2 connect-interface loopback 0
[SwitchC-bgp] quit
[SwitchC] ospf 1
[SwitchC-ospf-1] area 0
[SwitchC-ospf-1-area-0.0.0.0] network 3.3.3.3 0.0.0.0
[SwitchC-ospf-1-area-0.0.0.0] network 9.1.1.0 0.0.0.255
[SwitchC-ospf-1-area-0.0.0.0] quit
[SwitchC-ospf-1] quit
[SwitchC] display bgp peer
BGP local router ID : 3.3.3.3
Local AS number : 65009
Total number of peers : 1 Peers in established state : 1
Peer AS MsgRcvd MsgSent OutQ PrefRcv Up/Down State
2.2.2.2 65009 2 2 0 0 00:00:13 Established
The output information shows that Switch C has established an IBGP peer relationship with Switch B.
3. Configure EBGP:
¡ The EBGP peers, Switch A and Switch B (usually belong to different carriers), are located in different ASs. Typically, their loopback interfaces are not reachable to each other, so directly connected interfaces are used for establishing BGP sessions.
¡ To enable Switch C to access the network 8.1.1.0/24 connected directly to Switch A, inject network 8.1.1.0/24 to the BGP routing table of Switch A.
# Configure Switch A.
<SwitchA> system-view
[SwitchA] bgp 65008
[SwitchA-bgp] router-id 1.1.1.1
[SwitchA-bgp] peer 3.1.1.1 as-number 65009
[SwitchA-bgp] network 8.1.1.1 24
[SwitchA-bgp] quit
# Configure Switch B.
[SwitchB] bgp 65009
[SwitchB-bgp] peer 3.1.1.2 as-number 65008
[SwitchB-bgp] quit
# Display BGP peer information on Switch B.
[SwitchB] display bgp peer
BGP local router ID : 2.2.2.2
Local AS number : 65009
Total number of peers : 2 Peers in established state : 2
Peer AS MsgRcvd MsgSent OutQ PrefRcv Up/Down State
3.3.3.3 65009 4 4 0 0 00:02:49 Established
3.1.1.2 65008 2 2 0 0 00:00:05 Established
The output shows that Switch B has established an IBGP peer relationship with Switch C and an EBGP peer relationship with Switch A.
# Display the BGP routing table on Switch A.
[SwitchA] display bgp routing-table
Total Number of Routes: 1
BGP Local router ID is 1.1.1.1
Status codes: * - valid, ^ - VPNv4 best, > - best, d - damped,
h - history, i - internal, s - suppressed, S - Stale
Origin : i - IGP, e - EGP, ? - incomplete
Network NextHop MED LocPrf PrefVal Path/Ogn
*> 8.1.1.0/24 0.0.0.0 0 0 i
# Display the BGP routing table on Switch B.
[SwitchB] display bgp routing-table
Total Number of Routes: 1
BGP Local router ID is 2.2.2.2
Status codes: * - valid, ^ - VPNv4 best, > - best, d - damped,
h - history, i - internal, s - suppressed, S - Stale
Origin : i - IGP, e - EGP, ? - incomplete
Network NextHop MED LocPrf PrefVal Path/Ogn
*> 8.1.1.0/24 3.1.1.2 0 0 65008i
# Display the BGP routing table on Switch C.
[SwitchC] display bgp routing-table
Total Number of Routes: 1
BGP Local router ID is 3.3.3.3
Status codes: * - valid, ^ - VPNv4 best, > - best, d - damped,
h - history, i - internal, s - suppressed, S - Stale
Origin : i - IGP, e - EGP, ? - incomplete
Network NextHop MED LocPrf PrefVal Path/Ogn
i 8.1.1.0/24 3.1.1.2 0 100 0 65008i
|
|
NOTE: The outputs show that Switch A has learned no route to AS65009, and Switch C has learned network 8.1.1.0, but the next hop 3.1.1.2 is unreachable, so the route is invalid. |
4. Redistribute direct routes:
Configure BGP to redistribute direct routes on Switch B, so that Switch A can obtain the route to 9.1.1.0/24 and Switch C can obtain the route to 3.1.1.0/24.
# Configure Switch B.
[SwitchB] bgp 65009
[SwitchB-bgp] import-route direct
# Display the BGP routing table on Switch A.
[SwitchA] display bgp routing-table
Total Number of Routes: 4
BGP Local router ID is 1.1.1.1
Status codes: * - valid, ^ - VPNv4 best, > - best, d - damped,
h - history, i - internal, s - suppressed, S - Stale
Origin : i - IGP, e - EGP, ? – incomplete
Network NextHop MED LocPrf PrefVal Path/Ogn
*> 2.2.2.2/32 3.1.1.1 0 0 65009?
* 3.1.1.0/24 3.1.1.1 0 0 65009?
*> 8.1.1.0/24 0.0.0.0 0 0 i
*> 9.1.1.0/24 3.1.1.1 0 0 65009?
Two routes, 2.2.2.2/32 and 9.1.1.0/24, have been added in Switch A’s routing table.
# Display the BGP routing table on Switch C.
[SwitchC] display bgp routing-table
Total Number of Routes: 4
BGP Local router ID is 3.3.3.3
Status codes: * - valid, ^ - VPNv4 best, > - best, d - damped,
h - history, i - internal, s - suppressed, S - Stale
Origin : i - IGP, e - EGP, ? - incomplete
Network NextHop MED LocPrf PrefVal Path/Ogn
i 2.2.2.2/32 2.2.2.2 0 100 0 ?
*>i 3.1.1.0/24 2.2.2.2 0 100 0 ?
*>i 8.1.1.0/24 3.1.1.2 0 100 0 65008i
* i 9.1.1.0/24 2.2.2.2 0 100 0 ?
The output shows that the route 8.1.1.0 becomes valid with the next hop as Switch A.
5. Verify the configuration:
# Ping 8.1.1.1 on Switch C.
[SwitchC] ping 8.1.1.1
PING 8.1.1.1: 56 data bytes, press CTRL_C to break
Reply from 8.1.1.1: bytes=56 Sequence=1 ttl=254 time=2 ms
Reply from 8.1.1.1: bytes=56 Sequence=2 ttl=254 time=2 ms
Reply from 8.1.1.1: bytes=56 Sequence=3 ttl=254 time=2 ms
Reply from 8.1.1.1: bytes=56 Sequence=4 ttl=254 time=2 ms
Reply from 8.1.1.1: bytes=56 Sequence=5 ttl=254 time=2 ms
--- 8.1.1.1 ping statistics ---
5 packet(s) transmitted
5 packet(s) received
0.00% packet loss
round-trip min/avg/max = 2/2/2 ms
BGP and IGP synchronization configuration
Network requirements
As shown in Figure 16, all devices of company A reside in AS 65008, and all devices of company B reside in AS 65009. AS 65008 and AS 65009 are connected through Switch A and Switch B. It is required that Switch A can access network 9.1.2.0/24 in AS 65009, and Switch C can access network 8.1.1.0/24 in AS 65008.
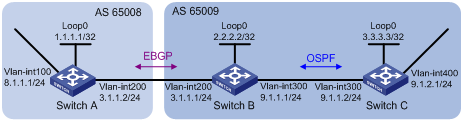
Configuration procedure
1. Configure IP addresses for interfaces. (Details not shown)
2. Configure OSPF:
Enable OSPF in AS 65009, so that Switch B can obtain the route to 9.1.2.0/24.
# Configure Switch B.
<SwitchB> system-view
[SwitchB] ospf 1
[SwitchB-ospf-1] area 0
[SwitchB-ospf-1-area-0.0.0.0] network 2.2.2.2 0.0.0.0
[SwitchB-ospf-1-area-0.0.0.0] network 9.1.1.0 0.0.0.255
[SwitchB-ospf-1-area-0.0.0.0] quit
[SwitchB-ospf-1] quit
# Configure Switch C.
<SwitchC> system-view
[SwitchC] ospf 1
[SwitchC-ospf-1] import-route direct
[SwitchC-ospf-1] area 0
[SwitchC-ospf-1-area-0.0.0.0] network 9.1.1.0 0.0.0.255
[SwitchC-ospf-1-area-0.0.0.0] quit
[SwitchC-ospf-1] quit
3. Configure the EBGP connection:
Configure the EBGP connection and inject network 8.1.1.0/24 to the BGP routing table of Switch A, so that Switch B can obtain the route to 8.1.1.0/24.
# Configure Switch A.
<SwitchA> system-view
[SwitchA] bgp 65008
[SwitchA-bgp] router-id 1.1.1.1
[SwitchA-bgp] peer 3.1.1.1 as-number 65009
[SwitchA-bgp] network 8.1.1.0 24
[SwitchA-bgp] quit
# Configure Switch B.
[SwitchB] bgp 65009
[SwitchB-bgp] router-id 2.2.2.2
[SwitchB-bgp] peer 3.1.1.2 as-number 65008
4. Configure BGP and IGP synchronization:
¡ Configure BGP to redistribute routes from OSPF on Switch B, so that Switch A can obtain the route to 9.1.2.0/24.
¡ Configure OSPF to redistribute routes from BGP on Switch B, so that Switch C can obtain the route to 8.1.1.0/24.
# Configure BGP to redistribute routes from OSPF on Switch B.
[SwitchB-bgp] import-route ospf 1
[SwitchB-bgp] quit
[SwitchB] ospf 1
[SwitchB-ospf-1] import-route bgp
[SwitchB-ospf-1] quit
# Display the BGP routing table on Switch A.
[SwitchA] display bgp routing-table
Total Number of Routes: 3
BGP Local router ID is 1.1.1.1
Status codes: * - valid, ^ - VPNv4 best, > - best, d - damped,
h - history, i - internal, s - suppressed, S - Stale
Origin : i - IGP, e - EGP, ? - incomplete
Network NextHop MED LocPrf PrefVal Path/Ogn
*> 3.3.3.3/32 3.1.1.1 1 0 65009?
*> 8.1.1.0/24 0.0.0.0 0 0 i
*> 9.1.2.0/24 3.1.1.1 1 0 65009?
# Display the routing table on Switch C.
[SwitchC] display ip routing-table
Routing Tables: Public
Destinations : 9 Routes : 9
Destination/Mask Proto Pre Cost NextHop Interface
2.2.2.2/32 OSPF 10 1 9.1.1.1 Vlan300
3.3.3.3/32 Direct 0 0 127.0.0.1 InLoop0
8.1.1.0/24 O_ASE 150 1 9.1.1.1 Vlan300
9.1.1.0/24 Direct 0 0 9.1.1.2 Vlan300
9.1.1.2/32 Direct 0 0 127.0.0.1 InLoop0
9.1.2.0/24 Direct 0 0 9.1.2.1 Vlan400
9.1.2.1/32 Direct 0 0 127.0.0.1 InLoop0
127.0.0.0/8 Direct 0 0 127.0.0.1 InLoop0
127.0.0.1/32 Direct 0 0 127.0.0.1 InLoop0
5. Verify the configuration:
# Use ping for verification.
[SwitchA] ping -a 8.1.1.1 9.1.2.1
PING 9.1.2.1: 56 data bytes, press CTRL_C to break
Reply from 9.1.2.1: bytes=56 Sequence=1 ttl=254 time=15 ms
Reply from 9.1.2.1: bytes=56 Sequence=2 ttl=254 time=31 ms
Reply from 9.1.2.1: bytes=56 Sequence=3 ttl=254 time=47 ms
Reply from 9.1.2.1: bytes=56 Sequence=4 ttl=254 time=46 ms
Reply from 9.1.2.1: bytes=56 Sequence=5 ttl=254 time=47 ms
--- 9.1.2.1 ping statistics ---
5 packet(s) transmitted
5 packet(s) received
0.00% packet loss
round-trip min/avg/max = 15/37/47 ms
[SwitchC] ping -a 9.1.2.1 8.1.1.1
PING 8.1.1.1: 56 data bytes, press CTRL_C to break
Reply from 8.1.1.1: bytes=56 Sequence=1 ttl=254 time=2 ms
Reply from 8.1.1.1: bytes=56 Sequence=2 ttl=254 time=2 ms
Reply from 8.1.1.1: bytes=56 Sequence=3 ttl=254 time=2 ms
Reply from 8.1.1.1: bytes=56 Sequence=4 ttl=254 time=2 ms
Reply from 8.1.1.1: bytes=56 Sequence=5 ttl=254 time=2 ms
--- 8.1.1.1 ping statistics ---
5 packet(s) transmitted
5 packet(s) received
0.00% packet loss
round-trip min/avg/max = 2/2/2 ms
BGP load balancing configuration
Network requirements
As shown in Figure 17, all the switches run BGP. Switch A resides in AS 65008, Switch B and Switch C in AS 65009. EBGP runs between Switch A and Switch B, Switch A and Switch C. IBGP runs between Switch B and Switch C. Configure two routes on Switch A for load balancing.
Configuration procedure
1. Configure IP addresses for interfaces. (Details not shown)
2. Configure BGP connections:
¡ On Switch A, establish EBGP connections with Switch B and Switch C, respectively; configure BGP to advertise network 8.1.1.0/24 to Switch B and Switch C, so that Switch B and Switch C can access the internal network connected to Switch A.
¡ On Switch B, establish an EBGP connection with Switch A and an IBGP connection with Switch C; configure BGP to advertise network 9.1.1.0/24 to Switch A, so that Switch A can access the intranet through Switch B; configure a static route to interface loopback 0 on Switch C (or use a routing protocol like OSPF) to establish the IBGP connection.
¡ On Switch C, establish an EBGP connection with Switch A and an IBGP connection with Switch B; configure BGP to advertise network 9.1.1.0/24 to Switch A, so that Switch A can access the intranet through Switch C; configure a static route to interface loopback 0 on Switch B (or use another protocol like OSPF) to establish the IBGP connection.
# Configure Switch A.
<SwitchA> system-view
[SwitchA] bgp 65008
[SwitchA-bgp] router-id 1.1.1.1
[SwitchA-bgp] peer 3.1.1.1 as-number 65009
[SwitchA-bgp] peer 3.1.2.1 as-number 65009
[SwitchA-bgp] network 8.1.1.1 24
[SwitchA-bgp] quit
# Configure Switch B.
<SwitchB> system-view
[SwitchB] bgp 65009
[SwitchB-bgp] router-id 2.2.2.2
[SwitchB-bgp] peer 3.1.1.2 as-number 65008
[SwitchB-bgp] peer 3.3.3.3 as-number 65009
[SwitchB-bgp] peer 3.3.3.3 connect-interface loopback 0
[SwitchB-bgp] network 9.1.1.0 255.255.255.0
[SwitchB-bgp] quit
[SwitchB] ip route-static 3.3.3.3 32 9.1.1.2
# Configure Switch C.
<SwitchC> system-view
[SwitchC] bgp 65009
[SwitchC-bgp] router-id 3.3.3.3
[SwitchC-bgp] peer 3.1.2.2 as-number 65008
[SwitchC-bgp] peer 2.2.2.2 as-number 65009
[SwitchC-bgp] peer 2.2.2.2 connect-interface loopback 0
[SwitchC-bgp] network 9.1.1.0 255.255.255.0
[SwitchC-bgp] quit
[SwitchC] ip route-static 2.2.2.2 32 9.1.1.1
# Display the BGP routing table on Switch A.
[SwitchA] display bgp routing-table
Total Number of Routes: 3
BGP Local router ID is 1.1.1.1
Status codes: * - valid, ^ - VPNv4 best, > - best, d - damped,
h - history, i - internal, s - suppressed, S - Stale
Origin : i - IGP, e - EGP, ? – incomplete
Network NextHop MED LocPrf PrefVal Path/Ogn
*> 8.1.1.0/24 0.0.0.0 0 0 i
*> 9.1.1.0/24 3.1.1.1 0 0 65009i
* 3.1.2.1 0 0 65009i
¡ The output shows two valid routes to destination 9.1.1.0/24: the route with next hop 3.1.1.1 is marked with a greater-than sign (>), indicating it is the best route (because the ID of Switch B is smaller); the route with next hop 3.1.2.1 is marked with only an asterisk (*), indicating it is a valid route, but not the best.
¡ By using the display ip routing-table command, you can find only one route to 9.1.1.0/24 with next hop 3.1.1.1 and outbound interface VLAN-interface 200.
3. Configure loading balancing.
Because Switch A has two routes to reach AS 65009, configuring load balancing over the two BGP routes on Switch A can improve link utilization.
# Configure Switch A.
[SwitchA] bgp 65008
[SwitchA-bgp] balance 2
[SwitchA-bgp] quit
4. Verify the configuration:
# Display the BGP routing table on Switch A.
[SwitchA] display bgp routing-table
Total Number of Routes: 3
BGP Local router ID is 1.1.1.1
Status codes: * - valid, ^ - VPNv4 best, > - best, d - damped,
h - history, i - internal, s - suppressed, S - Stale
Origin : i - IGP, e - EGP, ? - incomplete
Network NextHop MED LocPrf PrefVal Path/Ogn
*> 8.1.1.0/24 0.0.0.0 0 0 i
*> 9.1.1.0/24 3.1.1.1 0 0 65009i
*> 3.1.2.1 0 0 65009i
¡ The route 9.1.1.0/24 has two next hops, 3.1.1.1 and 3.1.2.1, both of which are marked with a greater-than sign (>), indicating they are the best routes.
¡ By using the display ip routing-table command, you can find two routes to 9.1.1.0/24: one with next hop 3.1.1.1 and outbound interface VLAN-interface 200, the other with next hop 3.1.2.1 and outbound interface VLAN-interface 300.
BGP community configuration
Network requirements
As shown in Figure 18, EBGP runs between Switch B and Switch A, and between Switch B and Switch C. Configure No_Export community attribute on Switch A to make routes from AS 10 not advertised by AS 20 to any other AS.
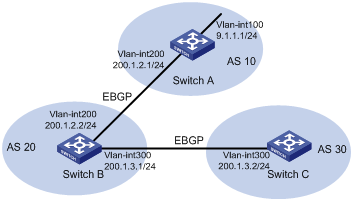
Configuration procedure
1. Configure IP addresses for interfaces. (Details not shown)
2. Configure EBGP:
# Configure Switch A.
<SwitchA> system-view
[SwitchA] bgp 10
[SwitchA-bgp] router-id 1.1.1.1
[SwitchA-bgp] peer 200.1.2.2 as-number 20
[SwitchA-bgp] network 9.1.1.0 255.255.255.0
[SwitchA-bgp] quit
# Configure Switch B.
<SwitchB> system-view
[SwitchB] bgp 20
[SwitchB-bgp] router-id 2.2.2.2
[SwitchB-bgp] peer 200.1.2.1 as-number 10
[SwitchB-bgp] peer 200.1.3.2 as-number 30
[SwitchB-bgp] quit
# Configure Switch C.
<SwitchC> system-view
[SwitchC] bgp 30
[SwitchC-bgp] router-id 3.3.3.3
[SwitchC-bgp] peer 200.1.3.1 as-number 20
[SwitchC-bgp] quit
# Display the BGP routing table on Switch B.
[SwitchB] display bgp routing-table 9.1.1.0
BGP local router ID : 2.2.2.2
Local AS number : 20
Paths: 1 available, 1 best
BGP routing table entry information of 9.1.1.0/24:
From : 200.1.2.1 (1.1.1.1)
Original nexthop: 200.1.2.1
AS-path : 10
Origin : igp
Attribute value : MED 0, pref-val 0, pre 255
State : valid, external, best,
Advertised to such 1 peers:
200.1.3.2
Switch B advertised routes to Switch C in AS30.
# Display the routing table on Switch C.
[SwitchC] display bgp routing-table
Total Number of Routes: 1
BGP Local router ID is 3.3.3.3
Status codes: * - valid, ^ - VPNv4 best, > - best, d - damped,
h - history, i - internal, s - suppressed, S - Stale
Origin : i - IGP, e - EGP, ? - incomplete
Network NextHop MED LocPrf PrefVal Path/Ogn
*> 9.1.1.0/24 200.1.3.1 0 0 20 10i
Switch C has learned route 9.1.1.0/24 from Switch B.
3. Configure BGP community:
# Configure a routing policy.
[SwitchA] route-policy comm_policy permit node 0
[SwitchA-route-policy] apply community no-export
[SwitchA-route-policy] quit
# Apply the routing policy.
[SwitchA] bgp 10
[SwitchA-bgp] peer 200.1.2.2 route-policy comm_policy export
[SwitchA-bgp] peer 200.1.2.2 advertise-community
# Display the routing table on Switch B.
[SwitchB] display bgp routing-table 9.1.1.0
BGP local router ID : 2.2.2.2
Local AS number : 20
Paths: 1 available, 1 best
BGP routing table entry information of 9.1.1.0/24:
From : 200.1.2.1 (1.1.1.1)
Original nexthop: 200.1.2.1
Community : No-Export
AS-path : 10
Origin : igp
Attribute value : MED 0, pref-val 0, pre 255
State : valid, external, best,
Not advertised to any peers yet
The route 9.1.1.0/24 is not available in the routing table of Switch C.
BGP route reflector configuration
Network requirements
In Figure 19, all switches run BGP.
· EBGP runs between Switch A and Switch B. IBGP runs between Switch C and Switch B, and between Switch C and Switch D.
· Switch C is a route reflector with clients Switch B and D.
· Switch D can learn route 1.0.0.0/8 from Switch C.
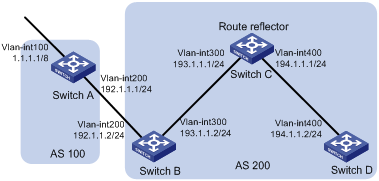
Configuration procedure
1. Configure IP addresses for interfaces. (Details not shown)
2. Configure BGP connections:
# Configure Switch A.
<SwitchA> system-view
[SwitchA] bgp 100
[SwitchA-bgp] router-id 1.1.1.1
[SwitchA-bgp] peer 192.1.1.2 as-number 200
# Inject network 1.0.0.0/8 to the BGP routing table.
[SwitchA-bgp] network 1.0.0.0
[SwitchA-bgp] quit
# Configure Switch B.
<SwitchB> system-view
[SwitchB] bgp 200
[SwitchB-bgp] router-id 2.2.2.2
[SwitchB-bgp] peer 192.1.1.1 as-number 100
[SwitchB-bgp] peer 193.1.1.1 as-number 200
[SwitchB-bgp] peer 193.1.1.1 next-hop-local
[SwitchB-bgp] quit
# Configure Switch C.
<SwitchC> system-view
[SwitchC] bgp 200
[SwitchC-bgp] router-id 3.3.3.3
[SwitchC-bgp] peer 193.1.1.2 as-number 200
[SwitchC-bgp] peer 194.1.1.2 as-number 200
[SwitchC-bgp] quit
# Configure Switch D.
<SwitchD> system-view
[SwitchD] bgp 200
[SwitchD-bgp] router-id 4.4.4.4
[SwitchD-bgp] peer 194.1.1.1 as-number 200
[SwitchD-bgp] quit
3. Configure the route reflector:
# Configure Switch C.
[SwitchC] bgp 200
[SwitchC-bgp] peer 193.1.1.2 reflect-client
[SwitchC-bgp] peer 194.1.1.2 reflect-client
[SwitchC-bgp] quit
4. Verify the configuration:
# Display the BGP routing table on Switch B.
[SwitchB] display bgp routing-table
Total Number of Routes: 1
BGP Local router ID is 200.1.2.2
Status codes: * - valid, ^ - VPNv4 best, > - best, d - damped,
h - history, i - internal, s - suppressed, S - Stale
Origin : i - IGP, e - EGP, ? - incomplete
Network NextHop MED LocPrf PrefVal Path/Ogn
*> 1.0.0.0 192.1.1.1 0 0 100i
# Display the BGP routing table on Switch D.
[SwitchD] display bgp routing-table
Total Number of Routes: 1
BGP Local router ID is 200.1.2.1
Status codes: * - valid, ^ - VPNv4 best, > - best, d - damped,
h - history, i - internal, s - suppressed, S - Stale
Origin : i - IGP, e - EGP, ? - incomplete
Network NextHop MED LocPrf PrefVal Path/Ogn
i 1.0.0.0 193.1.1.2 0 100 0 100i
Switch D has learned route 1.0.0.0/8 from Switch C.
BGP confederation configuration
Network requirements
As shown in Figure 20, to reduce IBGP connections in AS 200, split it into three sub-ASs: AS65001, AS65002, and AS65003. Switches in AS65001 are fully meshed.
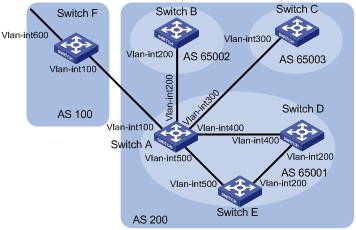
|
Device |
Interface |
IP address |
Device |
Interface |
IP address |
|
Switch A |
Vlan-int100 |
200.1.1.1/24 |
Switch D |
Vlan-int200 |
10.1.5.1/24 |
|
|
Vlan-int200 |
10.1.1.1/24 |
|
Vlan-int400 |
10.1.3.2/24 |
|
|
Vlan-int300 |
10.1.2.1/24 |
Switch E |
Vlan-int200 |
10.1.5.2/24 |
|
|
Vlan-int400 |
10.1.3.1/24 |
|
Vlan-int500 |
10.1.4.2/24 |
|
|
Vlan-int500 |
10.1.4.1/24 |
Switch F |
Vlan-int100 |
200.1.1.2/24 |
|
Switch B |
Vlan-int200 |
10.1.1.2/24 |
|
Vlan-int600 |
9.1.1.1/24 |
|
Switch C |
Vlan-int300 |
10.1.2.2/24 |
|
|
|
Configuration procedure
1. Configure IP addresses for interfaces. (Details not shown)
2. Configure BGP confederation:
# Configure Switch A.
<SwitchA> system-view
[SwitchA] bgp 65001
[SwitchA-bgp] router-id 1.1.1.1
[SwitchA-bgp] confederation id 200
[SwitchA-bgp] confederation peer-as 65002 65003
[SwitchA-bgp] peer 10.1.1.2 as-number 65002
[SwitchA-bgp] peer 10.1.1.2 next-hop-local
[SwitchA-bgp] peer 10.1.2.2 as-number 65003
[SwitchA-bgp] peer 10.1.2.2 next-hop-local
[SwitchA-bgp] quit
# Configure Switch B.
<SwitchB> system-view
[SwitchB] bgp 65002
[SwitchB-bgp] router-id 2.2.2.2
[SwitchB-bgp] confederation id 200
[SwitchB-bgp] confederation peer-as 65001 65003
[SwitchB-bgp] peer 10.1.1.1 as-number 65001
[SwitchB-bgp] quit
# Configure Switch C.
<SwitchC> system-view
[SwitchC] bgp 65003
[SwitchC-bgp] router-id 3.3.3.3
[SwitchC-bgp] confederation id 200
[SwitchC-bgp] confederation peer-as 65001 65002
[SwitchC-bgp] peer 10.1.2.1 as-number 65001
[SwitchC-bgp] quit
3. Configure IBGP connections in AS65001:
# Configure Switch A.
[SwitchA] bgp 65001
[SwitchA-bgp] peer 10.1.3.2 as-number 65001
[SwitchA-bgp] peer 10.1.3.2 next-hop-local
[SwitchA-bgp] peer 10.1.4.2 as-number 65001
[SwitchA-bgp] peer 10.1.4.2 next-hop-local
[SwitchA-bgp] quit
# Configure Switch D.
<SwitchD> system-view
[SwitchD] bgp 65001
[SwitchD-bgp] router-id 4.4.4.4
[SwitchD-bgp] confederation id 200
[SwitchD-bgp] peer 10.1.3.1 as-number 65001
[SwitchD-bgp] peer 10.1.5.2 as-number 65001
[SwitchD-bgp] quit
# Configure Switch E.
<SwitchE> system-view
[SwitchE] bgp 65001
[SwitchE-bgp] router-id 5.5.5.5
[SwitchE-bgp] confederation id 200
[SwitchE-bgp] peer 10.1.4.1 as-number 65001
[SwitchE-bgp] peer 10.1.5.1 as-number 65001
[SwitchE-bgp] quit
4. Configure the EBGP connection between AS100 and AS200:
# Configure Switch A.
[SwitchA] bgp 65001
[SwitchA-bgp] peer 200.1.1.2 as-number 100
[SwitchA-bgp] quit
# Configure Switch F.
<SwitchF> system-view
[SwitchF] bgp 100
[SwitchF-bgp] router-id 6.6.6.6
[SwitchF-bgp] peer 200.1.1.1 as-number 200
[SwitchF-bgp] network 9.1.1.0 255.255.255.0
[SwitchF-bgp] quit
5. Verify the configuration:
# Display the routing table on Switch B.
[SwitchB] display bgp routing-table
Total Number of Routes: 1
BGP Local router ID is 2.2.2.2
Status codes: * - valid, ^ - VPNv4 best, > - best, d - damped,
h - history, i - internal, s - suppressed, S - Stale
Origin : i - IGP, e - EGP, ? - incomplete
Network NextHop MED LocPrf PrefVal Path/Ogn
*>i 9.1.1.0/24 10.1.1.1 0 100 0 (65001) 100i
[SwitchB] display bgp routing-table 9.1.1.0
BGP local router ID : 2.2.2.2
Local AS number : 65002
Paths: 1 available, 1 best
BGP routing table entry information of 9.1.1.0/24:
From : 10.1.1.1 (1.1.1.1)
Relay Nexthop : 0.0.0.0
Original nexthop: 10.1.1.1
AS-path : (65001) 100
Origin : igp
Attribute value : MED 0, localpref 100, pref-val 0, pre 255
State : valid, external-confed, best,
Not advertised to any peers yet
# Display the BGP routing table on Switch D.
[SwitchD] display bgp routing-table
Total Number of Routes: 1
BGP Local router ID is 4.4.4.4
Status codes: * - valid, ^ - VPNv4 best, > - best, d - damped,
h - history, i - internal, s - suppressed, S - Stale
Origin : i - IGP, e - EGP, ? - incomplete
Network NextHop MED LocPrf PrefVal Path/Ogn
*>i 9.1.1.0/24 10.1.3.1 0 100 0 100i
[SwitchD] display bgp routing-table 9.1.1.0
BGP local router ID : 4.4.4.4
Local AS number : 65001
Paths: 1 available, 1 best
BGP routing table entry information of 9.1.1.0/24:
From : 10.1.3.1 (1.1.1.1)
Relay Nexthop : 0.0.0.0
Original nexthop: 10.1.3.1
AS-path : 100
Origin : igp
Attribute value : MED 0, localpref 100, pref-val 0, pre 255
State : valid, internal, best,
Not advertised to any peers yet
The output information indicates the following:
¡ Switch F can send route information to Switch B and Switch C through the confederation by establishing only an EBGP connection with Switch A.
¡ Switch B and Switch D are in the same confederation, but belong to different sub ASs. They obtain external route information from Switch A and generate the same BGP route entries; it seems like that they reside in the same AS although they have no direct connection in between.
BGP path selection configuration
Network requirements
· In Figure 21, all switches run BGP. EBGP runs between Switch A and Switch B, and between Switch A and Switch C. IBGP runs between Switch B and Switch D, and between Switch D and Switch C.
· OSPF is the IGP protocol in AS 200.
· Configure routing policies, making Switch D use the route 1.0.0.0/8 from Switch C as the optimal.
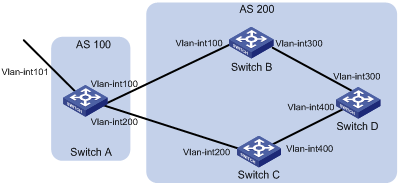
|
Device |
Interface |
IP address |
Device |
Interface |
IP address |
|
Switch A |
Vlan-int101 |
1.0.0.0/8 |
Switch D |
Vlan-int400 |
195.1.1.1/24 |
|
|
Vlan-int100 |
192.1.1.1/24 |
|
Vlan-int300 |
194.1.1.1/24 |
|
|
Vlan-int200 |
193.1.1.1/24 |
Switch C |
Vlan-int400 |
195.1.1.2/24 |
|
Switch B |
Vlan-int100 |
192.1.1.2/24 |
|
Vlan-int200 |
193.1.1.2/24 |
|
|
Vlan-int300 |
194.1.1.2/24 |
|
|
|
Configuration procedure
1. Configure IP addresses for interfaces. (Details not shown)
2. Configure OSPF on Switch B, C, and D:
# Configure Switch B.
<SwitchB> system-view
[SwitchB] ospf
[SwitchB-ospf] area 0
[SwitchB-ospf-1-area-0.0.0.0] network 192.1.1.0 0.0.0.255
[SwitchB-ospf-1-area-0.0.0.0] network 194.1.1.0 0.0.0.255
[SwitchB-ospf-1-area-0.0.0.0] quit
[SwitchB-ospf-1] quit
# Configure Switch C.
<SwitchC> system-view
[SwitchC] ospf
[SwitchC-ospf] area 0
[SwitchC-ospf-1-area-0.0.0.0] network 193.1.1.0 0.0.0.255
[SwitchC-ospf-1-area-0.0.0.0] network 195.1.1.0 0.0.0.255
[SwitchC-ospf-1-area-0.0.0.0] quit
[SwitchC-ospf-1] quit
# Configure Switch D.
<SwitchD> system-view
[SwitchD] ospf
[SwitchD-ospf] area 0
[SwitchD-ospf-1-area-0.0.0.0] network 194.1.1.0 0.0.0.255
[SwitchD-ospf-1-area-0.0.0.0] network 195.1.1.0 0.0.0.255
[SwitchD-ospf-1-area-0.0.0.0] quit
[SwitchD-ospf-1] quit
3. Configure BGP connections:
# Configure Switch A.
<SwitchA> system-view
[SwitchA] bgp 100
[SwitchA-bgp] peer 192.1.1.2 as-number 200
[SwitchA-bgp] peer 193.1.1.2 as-number 200
# Inject network 1.0.0.0/8 to the BGP routing table on Switch A.
[SwitchA-bgp] network 1.0.0.0 8
[SwitchA-bgp] quit
# Configure Switch B.
[SwitchB] bgp 200
[SwitchB-bgp] peer 192.1.1.1 as-number 100
[SwitchB-bgp] peer 194.1.1.1 as-number 200
[SwitchB-bgp] quit
# Configure Switch C.
[SwitchC] bgp 200
[SwitchC-bgp] peer 193.1.1.1 as-number 100
[SwitchC-bgp] peer 195.1.1.1 as-number 200
[SwitchC-bgp] quit
# Configure Switch D.
[SwitchD] bgp 200
[SwitchD-bgp] peer 194.1.1.2 as-number 200
[SwitchD-bgp] peer 195.1.1.2 as-number 200
[SwitchD-bgp] quit
4. Configure attributes for route 1.0.0.0/8, making Switch D give priority to the route learned from Switch C:
¡ Method I: Configure a higher MED value for the route 1.0.0.0/8 advertised from Switch A to peer 192.1.1.2.
# Define an ACL numbered 2000 to permit route 1.0.0.0/8.
[SwitchA] acl number 2000
[SwitchA-acl-basic-2000] rule permit source 1.0.0.0 0.255.255.255
[SwitchA-acl-basic-2000] quit
# Define two routing policies, apply_med_50, which sets the MED for route 1.0.0.0/8 to 50, and apply_med_100, which sets the MED for route 1.0.0.0/8 to 100.
[SwitchA] route-policy apply_med_50 permit node 10
[SwitchA-route-policy] if-match acl 2000
[SwitchA-route-policy] apply cost 50
[SwitchA-route-policy] quit
[SwitchA] route-policy apply_med_100 permit node 10
[SwitchA-route-policy] if-match acl 2000
[SwitchA-route-policy] apply cost 100
[SwitchA-route-policy] quit
# Apply routing policy apply_med_50 to the route advertised to peer 193.1.1.2 (Switch C), and apply_med_100 to the route advertised to peer 192.1.1.2 (Switch B).
[SwitchA] bgp 100
[SwitchA-bgp] peer 193.1.1.2 route-policy apply_med_50 export
[SwitchA-bgp] peer 192.1.1.2 route-policy apply_med_100 export
[SwitchA-bgp] quit
# Display the BGP routing table on Switch D.
[SwitchD] display bgp routing-table
Total Number of Routes: 2
BGP Local router ID is 194.1.1.1
Status codes: * - valid, ^ - VPNv4 best, > - best, d - damped,
h - history, i - internal, s - suppressed, S - Stale
Origin : i - IGP, e - EGP, ? - incomplete
Network NextHop MED LocPrf PrefVal Path/Ogn
*>i 1.0.0.0 193.1.1.1 50 100 0 100i
* i 192.1.1.1 100 100 0 100i
Route 1.0.0.0/8 is the optimal.
¡ Method II: Configure different local preferences on Switch B and C for route 1.0.0.0/8, making Switch D give priority to the route from Switch C.
# Define an ACL numbered 2000 on Router C, permitting route 1.0.0.0/8.
[SwitchC] acl number 2000
[SwitchC-acl-basic-2000] rule permit source 1.0.0.0 0.255.255.255
[SwitchC-acl-basic-2000] quit
# Configure a routing policy named localpref on Switch C, setting the local preference of route 1.0.0.0/8 to 200 (the default is 100).
[SwitchC] route-policy localpref permit node 10
[SwitchC-route-policy] if-match acl 2000
[SwitchC-route-policy] apply local-preference 200
[SwitchC-route-policy] quit
# Apply routing policy localpref to routes from peer 193.1.1.1.
[SwitchC] bgp 200
[SwitchC-bgp] peer 193.1.1.1 route-policy localpref import
[SwitchC-bgp] quit
# Display the routing table on Switch D.
[SwitchD] display bgp routing-table
Total Number of Routes: 2
BGP Local router ID is 194.1.1.1
Status codes: * - valid, ^ - VPNv4 best, > - best, d - damped,
h - history, i - internal, s - suppressed, S - Stale
Origin : i - IGP, e - EGP, ? - incomplete
Network NextHop MED LocPrf PrefVal Path/Ogn
*>i 1.0.0.0 193.1.1.1 0 200 0 100i
* i 192.1.1.1 0 100 0 100i
Route 1.0.0.0/8 from Switch D to Switch C is the optimal.
BGP GR configuration
Network requirements
In Figure 22 are all BGP switches. EBGP runs between Switch A and Switch B. IBGP runs between Switch B and Switch C. Enable GR capability for BGP so that the communication between Switch A and Switch C is not affected when an active/standby main board switchover occurs on Switch B.
Configuration procedure
1. Configure Switch A:
# Configure IP addresses for interfaces. (Details not shown)
# Configure the EBGP connection.
<SwitchA> system-view
[SwitchA] bgp 65008
[SwitchA-bgp] router-id 1.1.1.1
[SwitchA-bgp] peer 200.1.1.1 as-number 65009
# Inject network 8.0.0.0/8 to the BGP routing table.
[SwitchA-bgp] network 8.0.0.0
# Enable GR capability for BGP.
[SwitchA-bgp] graceful-restart
2. Configure Switch B:
# Configure IP addresses for interfaces. (Details not shown)
# Configure the EBGP connection.
<SwitchB> system-view
[SwitchB] bgp 65009
[SwitchB-bgp] router-id 2.2.2.2
[SwitchB-bgp] peer 200.1.1.2 as-number 65008
# Configure the IBGP connection.
[SwitchB-bgp] peer 9.1.1.2 as-number 65009
# Inject networks 200.1.1.0/24 and 9.1.1.0/24 to the BGP routing table.
[SwitchB-bgp] network 200.1.1.0 24
[SwitchB-bgp] network 9.1.1.0 24
# Enable GR capability for BGP.
[SwitchB-bgp] graceful-restart
3. Configure Switch C:
# Configure IP addresses for interfaces. (Details not shown)
# Configure the IBGP connection.
<SwitchC> system-view
[SwitchC] bgp 65009
[SwitchC-bgp] router-id 3.3.3.3
[SwitchC-bgp] peer 9.1.1.1 as-number 65009
# Enable GR capability for BGP.
[SwitchC-bgp] graceful-restart
4. Verify the configuration:
Ping Switch C on Switch A. Meanwhile, perform an active/standby main board switchover on Switch B. The ping operation is successful during the whole switchover process.
Configuring BFD for BGP
Network requirements
As shown in Figure 23,
· Configure OSPF as the IGP in AS 200.
· Establish two IBGP connections between Switch A and Switch C. When both links are working, Switch C adopts the link Switch A<—>Switch B<—>Switch C to exchange packets with network 1.1.1.0/24. Configure BFD over the link. Then if the link fails, BFD can quickly detect the failure and notify it to BGP. Then the link Switch A<—>Switch D<—>Switch C takes effect immediately.
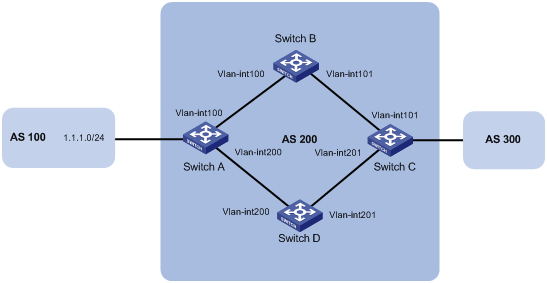
|
Device |
Interface |
IP address |
Device |
Interface |
IP address |
|
Switch A |
Vlan-int100 |
3.0.1.1/24 |
Switch C |
Vlan-int101 |
3.0.2.2/24 |
|
|
Vlan-int200 |
2.0.1.1/24 |
|
Vlan-int201 |
2.0.2.2/24 |
|
Switch B |
Vlan-int100 |
3.0.1.2/24 |
Switch D |
Vlan-int200 |
2.0.1.2/24 |
|
|
Vlan-int101 |
3.0.2.1/24 |
|
Vlan-int201 |
2.0.2.1/24 |
Configuration procedure
1. Configure IP addresses for interfaces. (Details not shown)
2. Configure OSPF to make sure that Switch A and Switch C are reachable to each other. (Details not shown)
3. Configure BGP on Switch A:
# Establish two IBGP connections between Switch A and Switch C.
<SwitchA> system-view
[SwitchA] bgp 200
[SwitchA-bgp] peer 3.0.2.2 as-number 200
[SwitchA-bgp] peer 2.0.2.2 as-number 200
[SwitchA-bgp] quit
# When the two links between Switch A and Switch C are both up, Switch C adopts the link Switch A<—>Switch B<—>Switch C to exchange packets with network 1.1.1.0/24. (Set a higher MED value for route 1.1.1.0/24 sent to peer 2.0.2.2 on Switch A.)
¡ Create ACL 2000 to permit 1.1.1.0/24 to pass.
[SwitchA] acl number 2000
[SwitchA-acl-basic-2000] rule permit source 1.1.1.0 0.0.0.255
[SwitchA-acl-basic-2000] quit
¡ Create two route policies, apply_med_50 and apply_med_100. Policy apply_med_50 sets the MED for route 1.1.1.0/24 to 50. Policy apply_med_100 sets that to 100.
[SwitchA] route-policy apply_med_50 permit node 10
[SwitchA-route-policy] if-match acl 2000
[SwitchA-route-policy] apply cost 50
[SwitchA-route-policy] quit
[SwitchA] route-policy apply_med_100 permit node 10
[SwitchA-route-policy] if-match acl 2000
[SwitchA-route-policy] apply cost 100
[SwitchA-route-policy] quit
¡ Apply routing policy apply_med_50 to routes outgoing to peer 3.0.2.2, and apply routing policy apply_med_100 to routes outgoing to peer 2.0.2.2.
[SwitchA] bgp 200
[SwitchA-bgp] peer 3.0.2.2 route-policy apply_med_50 export
[SwitchA-bgp] peer 2.0.2.2 route-policy apply_med_100 export
# Configure BFD over the link to peer 3.0.2.2 so that when the link Switch A<—>Switch B<—>Switch C fails, BFD can quickly detect the failure and notify it to BGP, and then the link Switch A<—>Switch D<—>Switch C takes effect immediately.
[SwitchA-bgp] peer 3.0.2.2 bfd
[SwitchA-bgp] quit
4. Configure BGP on Switch C:
<SwitchC> system-view
[SwitchC] bgp 200
[SwitchC-bgp] peer 3.0.1.1 as-number 200
[SwitchC-bgp] peer 3.0.1.1 bfd
[SwitchC-bgp] peer 2.0.1.1 as-number 200
[SwitchC-bgp] quit
5. Configure BFD parameters (you can use default BFD parameters instead).
# Configure Switch A:
[SwitchA] bfd session init-mode active
[SwitchA] interface vlan-interface 100
¡ Configure the minimum interval for transmitting BFD control packets as 500 milliseconds.
[SwitchA-Vlan-interface100] bfd min-transmit-interval 500
¡ Configure the minimum interval for receiving BFD control packets as 500 milliseconds.
[SwitchA-Vlan-interface100] bfd min-receive-interval 500
¡ Configure the detect multiplier as 7.
[SwitchA-Vlan-interface100] bfd detect-multiplier 7
[SwitchA-Vlan-interface100] quit
# Configure Switch C.
[SwitchC] bfd session init-mode active
[SwitchC] interface vlan-interface 101
[SwitchC-Vlan-interface101] bfd min-transmit-interval 500
[SwitchC-Vlan-interface101] bfd min-receive-interval 500
[SwitchC-Vlan-interface101] bfd detect-multiplier 7
[SwitchC-Vlan-interface101] return
6. Verify the configuration:
The following operations are made on Switch C. Operations on Switch A are similar and are not shown.
# Display detailed BFD session information.
<SwitchC> display bfd session verbose
Total Session Num: 1 Init Mode: Active
IP Session Working Under Ctrl Mode:
Local Discr: 17 Remote Discr: 13
Source IP: 3.0.2.2 Destination IP: 3.0.1.1
Session State: Up Interface: Vlan-interface101
Min Trans Inter: 500ms Act Trans Inter: 500ms
Min Recv Inter: 500ms Act Detect Inter: 3000ms
Recv Pkt Num: 57 Send Pkt Num: 53
Hold Time: 2200ms Connect Type: Indirect
Running Up for: 00:00:06 Auth mode: Simple
Protocol: BGP6
Diag Info: No Diagnostic
The output shows that a BFD session is established between Switch A’s VLAN-interface 100 and Switch C’s VLAN-interface 101 and that BFD runs properly.
# Display BGP peer information on Switch C, and you can see that Switch C has established two BGP neighborships with Switch A.
<SwitchC> display bgp peer
BGP local router ID : 1.1.1.1
Local AS number : 200
Total number of peers : 2 Peers in established state : 2
Peer AS MsgRcvd MsgSent OutQ PrefRcv Up/Down State
2.0.1.1 200 7 10 0 0 00:01:05 Established
3.0.1.1 200 7 10 0 0 00:01:34 Established
# Display route 1.1.1.0/24 on Switch C, and you can see that Switch A and Switch C communicate through Switch B.
<SwitchC> display ip routing-table 1.1.1.0 24 verbose
Routing Table : Public
Summary Count : 2
Destination: 1.1.1.0/24
Protocol: BGP Process ID: 0
Preference: 0 Cost: 50
NextHop: 3.0.1.1 Interface: Vlan-interface101
BkNextHop: 0.0.0.0 BkInterface:
RelyNextHop: 3.0.2.1 Neighbor : 3.0.1.1
Tunnel ID: 0x0 Label: NULL
State: Active Adv Age: 00h08m54s
Tag: 0
Destination: 1.1.1.0/24
Protocol: BGP Process ID: 0
Preference: 0 Cost: 100
NextHop: 2.0.1.1 Interface: Vlan-interface201
BkNextHop: 0.0.0.0 BkInterface:
RelyNextHop: 2.0.2.1 Neighbor : 2.0.1.1
Tunnel ID: 0x0 Label: NULL
State: Invalid Adv Age: 00h08m54s
Tag: 0
The output shows that Switch C has two routes to reach network 1.1.1.0/24: Switch C<—>Switch B<—>Switch A, which is the active route; Switch C<—>Switch D<—>Switch A, which is the backup route.
# Enable BFD debugging on Switch C.
<SwitchC> debugging bfd scm
<SwitchC> debugging bfd event
<SwitchC> debugging bgp bfd
<SwitchC> terminal monitor
<SwitchC> terminal debugging
# The following debugging information shows that: when the link between Switch A and Switch B fails, Switch C can quickly detect the link failure.
%Nov 5 11:42:24:172 2009 SwitchC BFD/5/BFD_CHANGE_FSM: Sess[3.0.2.2/3.0.1.1, 13/17,VLAN101,Ctrl], Sta: UP->DOWN, Diag: 1
%Nov 5 11:42:24:172 2009 SwitchC BGP/5/BGP_STATE_CHANGED: 3.0.1.1 state is changed from ESTABLISHED to IDLE.
*Nov 5 11:42:24:187 2009 SwitchC RM/6/RMDEBUG: BGP_BFD: Recv BFD DOWN msg, Src IP 3.0.2.2, Dst IP 3.0.1.1, Instance ID 0.
*Nov 5 11:42:24:187 2009 SwitchC RM/6/RMDEBUG: BGP_BFD: Reset BGP session 3.0.1.1 for BFD session down.
*Nov 5 11:42:24:187 2009 SwitchC RM/6/RMDEBUG: BGP_BFD: Send DELETE msg to BFD, Connection type DIRECT, Src IP 3.0.2.2, Dst IP 3.0.1.1, Instance ID 0.
# Display route 1.1.1.0/24 on Switch C, and you can see that Switch A and Switch C communicate through Switch D.
<SwitchC> display ip routing-table 1.1.1.0 24 verbose
Routing Table : Public
Summary Count : 1
Destination: 1.1.1.0/24
Protocol: BGP Process ID: 0
Preference: 0 Cost: 100
NextHop: 2.0.1.1 Interface: Vlan-interface201
BkNextHop: 0.0.0.0 BkInterface:
RelyNextHop: 2.0.2.1 Neighbor : 2.0.1.1
Tunnel ID: 0x0 Label: NULL
State: Active Adv Age: 00h09m54s
Tag: 0
The output shows that Switch C has one route Switch C<—>Switch D<—>Switch A to reach network 1.1.1.0/24.
Troubleshooting BGP
BGP peer relationship not established
Symptom
Display BGP peer information by using the display bgp peer command. The state of the connection to a peer cannot become established.
Analysis
To become BGP peers, any two routers must establish a TCP session using port 179 and exchange Open messages successfully.
Solution
1. Use the display current-configuration command to check that the peer’s AS number is correct.
2. Use the display bgp peer command to check that the peer’s IP address is correct.
3. If a loopback interface is used, check that the loopback interface is specified with the peer connect-interface command.
4. If the peer is a non-direct EBGP peer, check that the peer ebgp-max-hop command is configured.
5. Check that a valid route to the peer is available.
6. Use the ping command to check the connectivity to the peer.
7. Use the display tcp status command to check the TCP connection.
8. Check whether an ACL disabling TCP port 179 is configured.
