- 产品与解决方案
- 行业解决方案
- 服务
- 支持
- 合作伙伴
- 新华三人才研学中心
- 关于我们













手册下载
H3C SNA Center故障处理手册-E12xx-5W200-整本手册.pdf (660.15 KB)
H3C SNA Center
故障处理手册
资料版本:5W200-20200413
Copyright © 2020 新华三技术有限公司 版权所有,保留一切权利。
非经本公司书面许可,任何单位和个人不得擅自摘抄、复制本文档内容的部分或全部,并不得以任何形式传播。
除新华三技术有限公司的商标外,本手册中出现的其它公司的商标、产品标识及商品名称,由各自权利人拥有。
本文档中的信息可能变动,恕不另行通知。
本文档介绍SNA Center常见故障的诊断及处理措施。
当出现故障时,请尽可能全面、详细地记录现场信息(包括但不限于以下内容),收集信息越全面、越详细,越有利于故障的快速定位。
· 记录您所使用的SNA Installer、SNA Center版本和组件版本。
· 记录具体的故障现象、故障时间、配置信息。
· 记录完整的网络拓扑,包括组网图、端口连接关系、故障位置。
· 记录现场采取的故障处理措施及实施后的现象效果。
请通过如下步骤收集SNA Center操作日志、系统日志和诊断日志,以收集诊断日志为例,具体操作如下:
(1) 在浏览器(如Chrome)中输入SNA Center的GUI的登录地址(格式为:http://sna_center_ip_address:10080/portal或https://sna_center_ip_address:10443/portal),回车后打开SNA Center的GUI登录界面。输入用户名和密码后,单击<登录>按钮进入SNA Center的GUI首页。
(2) 在SNA Center首页,单击[系统]页签,单击设置区域,进入系统设置页面。
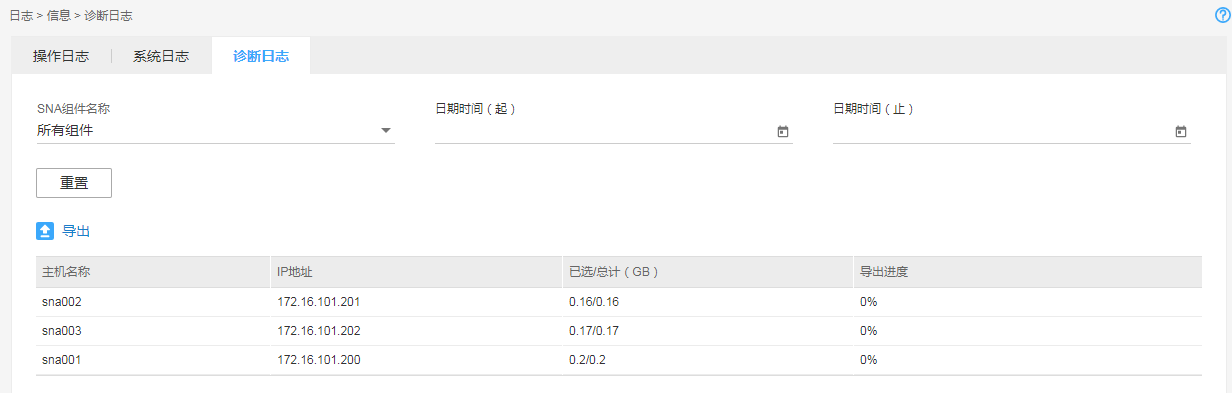
(3) 单击[日志 > 信息 > 诊断日志]菜单项,进入诊断日志页面。如图1-1所示。选择组件名称和起止时间,单击<导出>按钮,在弹出的对话框中,单击<确定>按钮,将指定组件在指定时间段内打印的诊断日志导出到本地。若不选择组件名称和起止时间,默认打印所有的诊断日志。
当故障无法自行解决时,请准备好设备运行信息、故障现象等材料,发送给H3C技术支持人员进行故障定位分析。
用户支持邮箱:service@h3c.com
技术支持热线电话:400-810-0504(手机、固话均可拨打)
在PC上使用HDM方式为服务器安装系统,同时开启多个KVM客户端工具,且多个服务器均挂载同一个ISO镜像文件进行安装,导致系统安装失败。
故障原因可能为:多个KVM客户端工具均挂载同一个ISO镜像文件,同时读取存在资源上的竞争,不同的操作系统有不同的互斥处理,可能会导致某个KVM在指定时间内无法完成读取任务,导致安装失败。建议不要同时使用多个KVM客户端挂载同一个ISO镜像文件。
故障处理步骤如下:
(1) 在安装失败的服务器上重新挂载ISO镜像文件进行安装。如多台服务器系统安装失败,请依次在失败的服务器上安装ISO镜像。
(2) 如果上述操作完成后故障仍无法排除,请联系H3C技术支持工程师。
SNA Installer[向导>创建集群]页面提示“该节点主机名称不合法。主机名称最长63个字符,仅支持小写字母、数字、连字符和小数点,且不能以连字符、小数点起始或结束。”
(1) 远程登录SNA Installer所在服务器,按主机名命名规范,修改主机名。new-hostname表示新主机名。
[root@sna001 /]# hostnamectl --static set-hostname new-hostname
(2) 重启服务器,使主机名的修改生效。
[root@sna001 /]# reboot –f
SNA Installer安装完成后,无法登录SNA Installer界面。
故障产生的原因可能为:在安装ISO的过程中SNA Installer安装包传输异常导致SNA Installer安装包文件损坏。排障步骤如下:
(1) 远程登录服务器,若/opt/matrix目录下仅存在config和app目录,且/h3Linux目录下没有SNA Installer软件的安装包(Matrix-version.zip),仅有SNA Installer的md5文件。出现这种情况则表明是文件传输过程中损坏。请执行下一步。
(2) 在本地使用解压软件将ISO安装包中Packages文件夹下的SNA Installer安装包Matrix-version.zip解压。将软件上传到服务器,执行以下命令安装:
[root@sna001 ~]# unzip Matrix-V500R002B01D001-x86_64.zip
[root@sna001 ~]# cd Matrix-V500R002B01D001-x86_64/
[root@sna001 Matrix-V500R002B01D001-x86_64]# ./install.sh
(3) 如果上述操作完成后故障仍无法排除,请联系H3C技术支持工程师。
系统安装完成后,使用ifconfig interface down、ifconfig interface up命令进行关闭和激活网卡的操作后,部分容器启动异常导致SNA Center功能异常。
故障产生的原因可能为使用ifconfig interface down、ifconfig interface up命命令进行关闭和激活网卡的操作,导致服务器路由表中的默认路由被删除。
故障处理步骤如下:
(1) 远程登录服务器,使用route命令查看服务器路由表中是否存在默认路由,若默认路由不存在,请使用systemctl restart network命令重新启动网络。
[root@sna3 ]# systemctl restart network
(2) 启动之后,使用route命令查看系统内默认路由是否恢复。若默认路由恢复,请执行下一步。
[root@sna3 /]# route
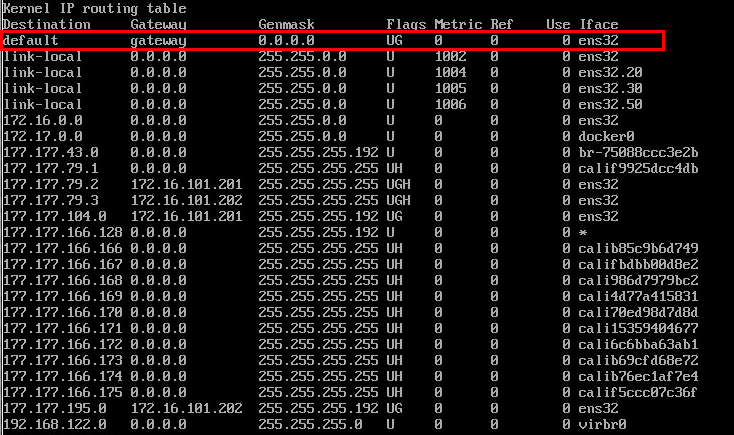
(3) 登录SNA Center,若仍功能异常无法正常使用,请联系H3C技术支持工程师。
集群中的某个节点因为硬件故障无法恢复,需要更换新的节点服务器。
造成故障的原因:集群节点服务器的硬件出现故障,导致节点服务器运行异常,且无法恢复。
故障处理步骤如下:
(1) 更换新节点服务器,并确保新节点服务器的主机名、IP地址、用户名及密码与故障节点相同。
(2) 在新节点服务器上部署SNA Installer,具体请参见《H3C SNA Center安装及组件部署指导》的“SNA Center安装”章节。
(3) 使用集群北向虚IP登录SNA Installer界面,在[部署/集群]页面下,单击故障节点右上角的![]() 按钮,选择[重建]菜单项重建该节点,即可完成更换服务器的操作。如果SNA Center上已部署vBGP,需要在重建故障节点之前,在节点上完成HugePages配置。
按钮,选择[重建]菜单项重建该节点,即可完成更换服务器的操作。如果SNA Center上已部署vBGP,需要在重建故障节点之前,在节点上完成HugePages配置。
集群中某个节点磁盘空间已满,在该节点主机中使用kubectl get pods --all-namespaces命令,出现大量处于Evicted状态的容器,手动清理磁盘后容器仍保持该状态。
造成故障的原因:节点服务器磁盘空间不足的情况下,K8S自动清理机制会产生大量处于Evicted状态的容器。
(2) 登录SNA Installer,进入集群部署页面。在该页面选择待修复的节点并单击节点右上角的![]() 按钮,选择“修复”选项进行节点修复,修复完成后K8S会自动删除节点服务器中处于Evicted状态的容器。
按钮,选择“修复”选项进行节点修复,修复完成后K8S会自动删除节点服务器中处于Evicted状态的容器。
应用绑定网络后,若重启指定节点的网络服务,将会导致容器内网络网卡丢失,网络连接异常。
造成故障的原因:重启节点网络服务会删除创建网络时创建的VLAN子接口及该节点容器内的网卡,导致容器内网络连接异常。
故障处理步骤如下:
(1) 使用reboot命令重启故障容器所在节点。
(2) 若重启失败请联系H3C技术支持工程师。
在SNA Installer上部署SNA Center时,提示集群中存在运行异常的Master节点。
造成故障的原因可能为网络故障或节点服务器异常断电等。故障处理步骤如下:
(1) 使用ping命令等检查SNA Installer与故障节点间的网络连通性是否正常,以及检查节点是否被异常断电。
(2) 通过集群北向业务虚IP登录页面,单击故障节点右上角的![]() 按钮并选择“修复”选项尝试进行节点修复。修复完成后,系统会自动清理未部署完成应用的残留数据。
按钮并选择“修复”选项尝试进行节点修复。修复完成后,系统会自动清理未部署完成应用的残留数据。
(3) 节点修复完成后,请再次部署应用。
(4) 如果上述操作完成后故障仍无法排除,请联系H3C技术支持工程师。
SNA Installer集群重启后,能访问登录页面,但是无法正常登录。namespace为base-service的Pod状态全部为running。
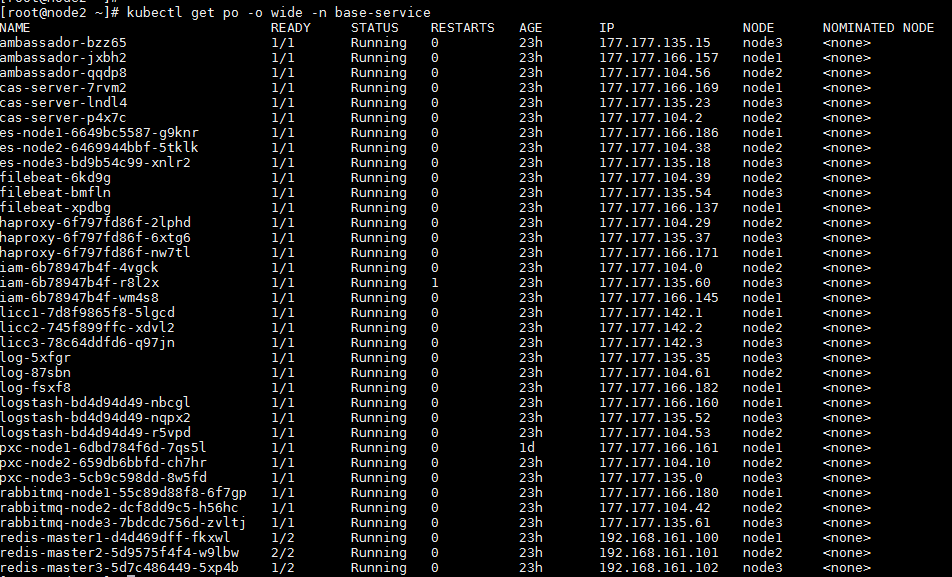
造成故障的原因可能为PXC数据库集群重启后Pod内服务未恢复。故障处理步骤如下:
(1) 远程登录SNA Center所在服务器,使用kubectl delete pod pod-name –n base-service命令将当前所有的PXC服务所在的pod删除,删除后,系统自动创建新的Pod承载该服务。等待Pod自动重新创建,且状态为running后再次尝试访问并登录。
(2) 如果上述操作完成后故障仍无法排除,请联系H3C技术支持工程师。
SNA Center组件部署页面,上传应用包进度一直是0%。
造成故障的原因可能是组件部署服务未正确启动。
(1) 远程登录SNA Center所在服务器,在控制台通过kubectl get pods –n dnec | grep dnec-deploy命令查看服务所在的Pod是否正确启动。Pod正常启动显示如下图所示。
![]()
(2) 若Pod的状态不是Running,使用kubectl delete pod pod-name –n dnec命令将有故障的服务所在的pod删除,删除后,系统自动创建新的Pod承载该服务。pod-name表示Pod名称。
![]()
(3) 如果上述操作完成后故障仍无法排除,请联系H3C技术支持工程师。
组件页面进行升级,页面提示升级失败。
故障处理步骤:
(1) 根据升级版本的不同,故障处理步骤有所不同:
· 若进行不同版本之间的升级,升级失败后,单击<回滚>按钮,系统自动为升级失败的组件进行回滚操作,将组件回退到升级前的版本。
· 若进行同版本升级,升级失败后,需远程登录三台物理服务器,在服务器的/opt/matrix/app/install/packages路径下删除升级失败的安装包,重新上传升级前的版本,然后在界面上单击<回滚>按钮,将组件回退到升级前的版本。
(2) 如果上述操作完成后故障仍无法排除,请联系H3C技术支持工程师。
组件安装或者组件升级后,直接进入控制器场景页面,出现菜单显示不全的异常。
造成故障的可能原因为:浏览器未清除缓存。
故障处理步骤:
(1) 在浏览器中清除缓存并重新登录SNA Center。
(2) 如果上述操作完成后故障仍无法排除,请联系H3C技术支持工程师。
跨域编排组件在单机部署的SNA Center上备份,在扩容到三机集群模式的SNA Center上恢复数据失败。卸载组件后重新部署,SNA Center提示组件部署成功,但应用场景不可用,服务器上NFV Orchestrator组件Pod异常。
造成故障的可能原因为:组件恢复失败,导致组件配置信息错误,重新部署后Pod无法正常启动。
故障处理步骤:
(1) 远程登录SNA Center所在服务器,在控制台通过kubectl get pods –n onap命令查看服务所在的Pod是否正确启动。Pod正常启动的显示如下图所示。
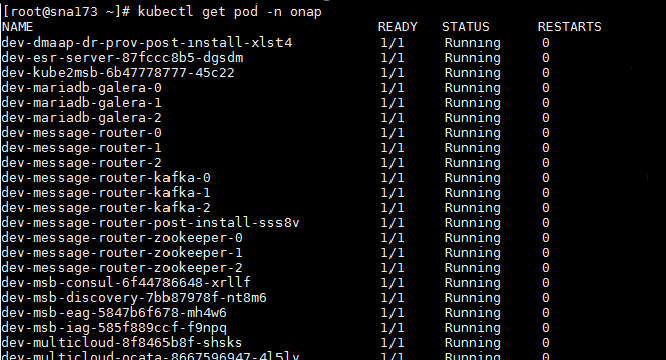
(2) 若Pod不是Running状态,请在SNA Center上卸载园数融合组件。
(3) 远程登录SNA Center所在服务器,在三个节点的控制台分别通过rm -rf /opt/matrix/app/data/NFVOrchestrator命令卸载园数融合产品遗留的数据。
(4) 在SNA Center上重新部署组件。
(5) 如果上述操作完成后故障仍无法排除,请联系H3C技术支持工程师。
系统异常断电后重新上电,系统功能异常,可能情况为安装、卸载、升级等操作失败,或者程序运行异常。
(1) 请使用对应现象的故障处理步骤进行故障排查与修复。
(2) 若无法修复,对系统进行重装。重新使用ISO文件在故障节点上部署H3Linux操作系统和SNA Installer。登录SNA Installer,在[部署/集群]界面,单击故障节点右上角的![]() 按钮,选择[修复]菜单项修复该节点。
按钮,选择[修复]菜单项修复该节点。
(3) 如果上述操作完成后故障仍无法排除,请联系H3C技术支持工程师。
服务器断电后,集群中有一台服务器无法启动。
造成故障可能的原因为Redis集群故障或PXC容器未正确启动。
(1) 远程登录SNA Center所在服务器。
(2) 使用kubectl get pod -n base-service -o wide|grep redis命令查看Redis容器状态,如果没有READY列为2/2且STATUS列为Running的容器,则说明Redis集群有问题。以下图故障为例,解决方法如下:

a. 分别进入到两台启动的节点的/opt/matrix/app/data/base-service/iam/redis/redis-slave目录下。
b. 使用cat /opt/matrix/app/data/base-service/iam/redis/redis-slave/redis.conf|grep "slaveof"命令查看指定的文件中有无对应的字段,有则将对应字段删除。
![]()
c. 使用cat /opt/matrix/app/data/base-service/iam/redis/redis-slave/redis.conf |grep "replicaof"命令查看指定的文件中有无对应字段,有则将对应字段删除。
![]()
d. 删除成功后,使用kubectl get pod -n base-service -o wide|grep redis命令查看Redis容器ID,使用kubectl delete pod pod-name -n base-service命令,将所有Redis容器删除。删除后,系统自动创建新的Pod承载该服务。等待Pod自动重新创建,若存在READY列为2/2且STATUS列为Running的容器,表示Redis集群恢复正常。
(3) 使用kubectl get po -n base-service -o wide|grep pxc查看PXC容器运行状态。以下图故障为例,解决方法如下:

a. 使用kubectl exec -it pod-ID bash -n base-service分别进入两个Running的容器,使用mysql –uroot –pc-krit命令查看mysql状态,若wsrep_local_state_comment状态为Synced且wrep_cluster_status状态为Primary,则表示mysql启动成功,PXC容器运行正常,请直接联系H3C技术支持工程师排查故障;若状态不正确,请继续执行下一步。
b. 查看/var/lib/mysql文件夹下的grastate.dat文件,比较两台中seqno值的的大小。
![]()
c. 若存在seqno为-1的节点,需要先在节点上执行mysqld_safe --wsrep-recover命令,从输出结果中选取seqno最大的节点,将safe_to_bootstrap的值修改为1,若seqno大于等于0且相等,则任意选取一个,将safe_to_bootstrap的值修改为1。
mysqld_safe --wsrep-recover命令执行结果不同,以如下两种情况为例,查看seqno的方法如下:
- wsrep_start_position前的数字为该容器的seqno。本举例中,seqno为78。
[root@pxc-node2-78c5ccd776-ctd5r /]# mysqld_safe --wsrep-recover
2019-11-21T11:09:09.960585Z mysqld_safe Logging to '/var/log/mysql/mysqld.log'.
2019-11-21T11:09:09.965125Z mysqld_safe Logging to '/var/log/mysql/mysqld.log'.
2019-11-21T11:09:10.017850Z mysqld_safe Starting mysqld daemon with databases from /var/lib/mysql
2019-11-21T11:09:10.033950Z mysqld_safe Skipping wsrep-recover for c7a6ac19-0a38-11ea-a345-3e37567626e5:78 pair
2019-11-21T11:09:10.036550Z mysqld_safe Assigning c7a6ac19-0a38-11ea-a345-3e37567626e5:78 to wsrep_start_position
2019-11-21T11:09:13.243177Z mysqld_safe mysqld from pid file /var/run/mysqld/mysqld.pid ended
- Recovered position的Pod ID后边的数字为该容器的seqno。本举例中,seqno为20。
[root@pxc-node3-5789455cd4-vcwz9 ~]# mysqld_safe --wsrep-recover
140821 15:57:15 mysqld_safe Logging to '/var/lib/mysql/percona3_error.log'.
140821 15:57:15 mysqld_safe Starting mysqld daemon with databases from /var/lib/mysql
140821 15:57:15 mysqld_safe WSREP: Running position recovery with --log_error='/var/lib/mysql/wsrep_recovery.6bUIqM' --pid-file='/var/lib/mysql/percona3-recover.pid'
140821 15:57:17 mysqld_safe WSREP: Recovered position 4b83bbe6-28bb-11e4-a885-4fc539d5eb6a:20
140821 15:57:19 mysqld_safe mysqld from pid file /var/lib/mysql/percona3.pid ended
d. 使用kubectl delete pod pod-name –n base-service命令将四个容器删除。
e. 待容器启动完成后,分别进入容器,使用mysql –uroot –pc-krit命令查看mysql状态,若wsrep_local_state_comment状态为Synced且wrep_cluster_status状态为Primary,则表示mysql启动成功。
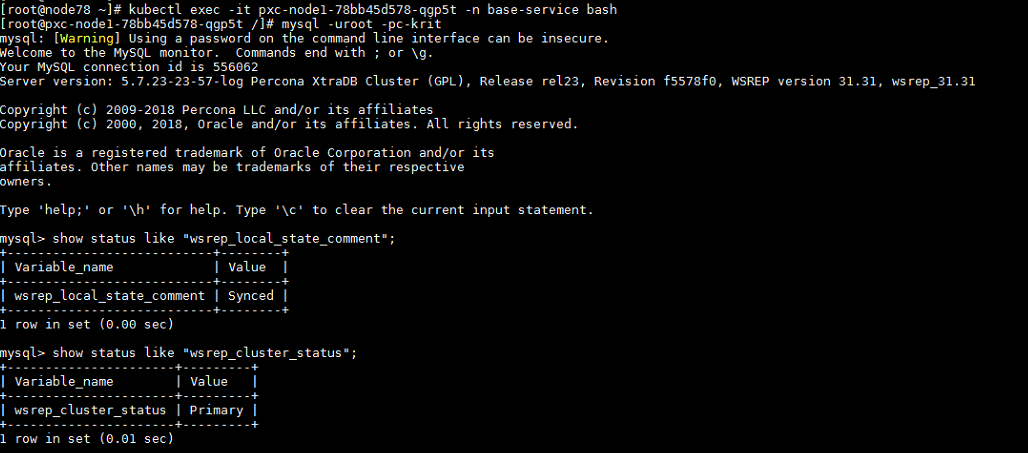
f. 如果上述操作完成后故障仍无法排除,请联系H3C技术支持工程师。











 售前咨询
售前咨询


 售后咨询
售后咨询

 人工在线咨询
人工在线咨询


