- 产品与解决方案
- 行业解决方案
- 服务
- 支持
- 合作伙伴
- 新华三人才研学中心
- 关于我们












手册下载
H3C RoCE网络开局一本通-6W100-整本手册.pdf (4.63 MB)
H3C RoCE网络开局一本通
Copyright © 2024 新华三技术有限公司 版权所有,保留一切权利。
非经本公司书面许可,任何单位和个人不得擅自摘抄、复制本文档内容的部分或全部,并不得以任何形式传播。
除新华三技术有限公司的商标外,本手册中出现的其它公司的商标、产品标识及商品名称,由各自权利人拥有。
本文档中的信息可能变动,恕不另行通知。
目 录
4.2 参数网配置举例(S9825二层盒盒400G端口组网)
5.5 分布式存储前端网络RDMA/TCP融合组网典型配置举例
6.2 推荐值(国产芯片设备S12500G-AF/S12500CR/S6850-G)
6.5 参数调整(国产芯片设备S12500G-AF/S12500CR/S6850-G)
7.5 RoCE流量分析:AD-DC海量数据归类细化关联分析
10.5 跨IRF成员设备ECMP或聚合是否开启了本地优先转发功能
11.9.1 如何根据客户光纤链路的情况选择使用哪种传输距离的光模块?
11.9.4 接口有CRC错误或Local Fault一定是本端口的问题吗?
11.9.5 为什么H3C光模块条码插在其他友商设备上与H3C读到的不一致?
11.9.6 H3C千兆电口光模块(SFP-GE-T)无法读取制造信息或条码是否正常?
随着高性能计算、大数据分析、人工智能以及物联网等技术的飞速发展,集中式存储、分布式存储以及云数据库的普及,业务应用有越来越多的数据需要从网络中获取,这些应用对数据中心网络的交换速度和性能要求越来越高。
传统的TCP/IP软硬件架构及应用存在着网络传输和数据处理的延迟过大、存在多次数据拷贝和中断处理、TCP/IP协议处理消耗CPU资源等问题。RDMA(Remote Direct Memory Access,远程直接内存访问)技术的内核旁路机制允许应用与网卡之间直接读写数据,使得服务器内的数据传输时延降低。同时,RDMA利用相关的硬件和网络技术,使服务器网卡之间可以直接读内存,实现了高吞吐量、超低时延下低CPU开销的效果。
与TCP/IP协议相比,RDMA具有以下优势:
· 低时延:RDMA的内核旁路机制,允许应用与网卡之间的直接数据读写,将服务器内的数据传输时延降低到接近1微秒。
· 低CPU负载:RDMA的内存零拷贝机制,允许接收端直接从发送端的内存读取数据,极大的减少了CPU的负担,提升了CPU的效率。
图1-1 传统TCP/IP数据传输过程
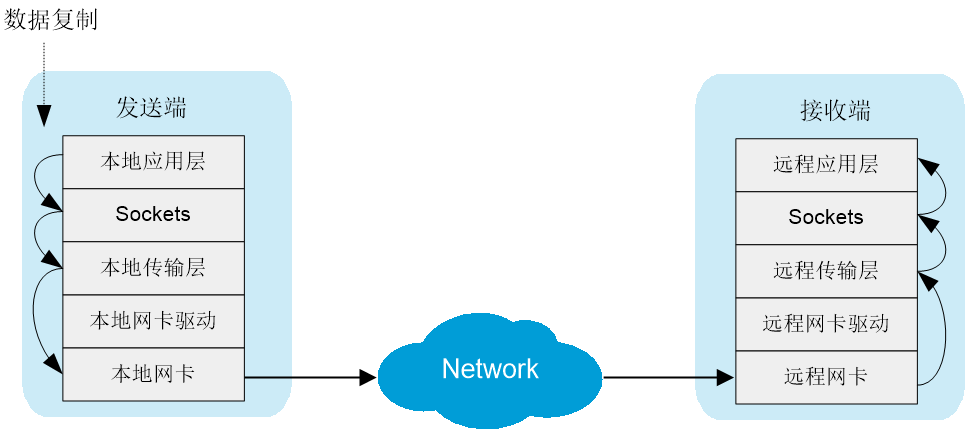
图1-2 RDMA数据传输过程
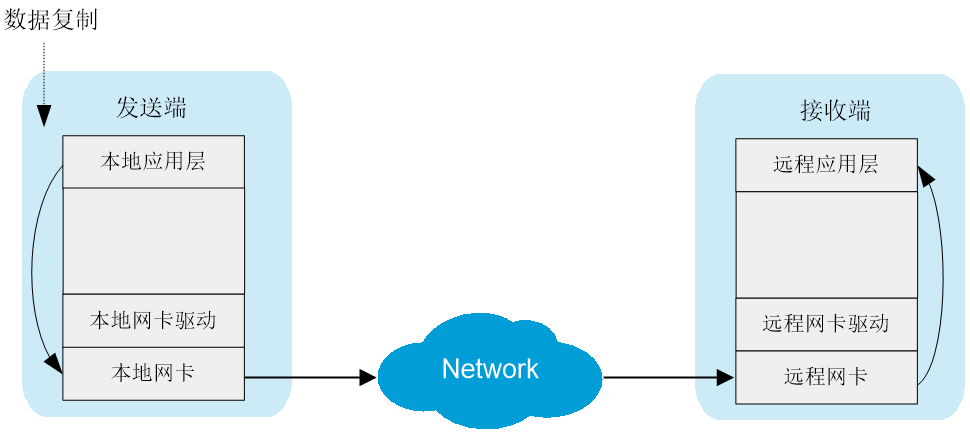
目前,RDMA网络主要有IB、iWAPR和RoCE三种类型。
· IB(InfiniBand,无限带宽):基于InfiniBand架构的RDMA技术,由IBTA(InfiniBand Trade Association)提出。搭建基于IB技术的RDMA网络需要专用的IB网卡和IB交换机,主要应用于高性能计算用户,成本较高。
· iWARP(Internet Wide Area RDMA Protocal,互联网广域RDMA协议):iWARP是基于TCP/IP协议的RDMA技术,由IETF标准定义。iWARP支持在标准以太网基础设施上使用RDMA技术,但服务器需要使用支持iWARP的网卡。
· RoCE(RDMA over Converged Ethernet,融合以太网RDMA协议):RoCE是基于以太网的RDMA技术,也是由IBTA提出。RoCE支持在标准以太网基础设施上使用RDMA技术,但是需要交换机支持无损以太网传输,需要服务器使用RoCE网卡。
其中ROCE分为RoCEv1和RoCEv2两代。
· RoCEv1协议:基于以太网承载RDMA,RoCEv1协议是一种以太网链路层协议,允许同一以太网广播域(VLAN)中的两个主机进行通信,只能部署于二层网络,它的报文结构是在原有的IB架构的报文上增加二层以太网的报文头,使用以太网类型(EtherType)0x8915标识RoCE报文。
· RoCEv2协议:基于UDP/IP协议承载RDMA,可部署于三层网络,它的报文结构是在原有的IB架构的报文上增加UDP头、IP头和二层以太网报文头,通过UDP目的端口号4791标识RoCE报文。RoCEv2支持基于源端口号HASH,采用ECMP实现负载分担,提高了网络的利用率。RoCEv2协议克服了RoCEv1仅限于单个广播域(VLAN)的限制。RoCEv2可以在L2和L3网络中使用,它通过改变数据包的封装方式,包括IP和UDP报头,实现L3路由功能。这使得RoCEv2可以在具有多个子网的网络中使用,从而实现更好的可扩展性。
当前分布式存储、HPC高性能计算、AI人工智能等场景均采用RoCEv2(RDMA over Converged Ethernet version 2)作为以太网上的传输协议来降低传输时延和CPU负担。
RoCEv2网络是基于无连接协议的UDP协议,相比于TCP协议,UDP协议传输速率更高、占用CPU资源更少,但是由于其不像TCP协议那样有滑动窗口、确认应答等机制来实现可靠传输,出现网络丢包时,依靠上层应用检查到后再做重传,会大大降低RDMA网络的传输效率。所以为了发挥出RDMA真正的性能,突破数据中心大规模分布式系统的网络性能瓶颈,就需要为RDMA搭建一套不丢包的无损网络环境,其关键就是解决网络拥塞。因此,以太网交换机需要支持无损网络的部署才能支持RoCEv2协议及其相关应用。
在RoCE网络中,我们需要构建智能无损以太网用于保证网络传输过程中不丢包。
智能无损网络一方面通过流量控制技术和拥塞控制技术来提升网络整体的吞吐量,降低网络时延,另一方面通过智能无损存储网络等技术实现网络和应用系统融合优化。根据智能无损网络技术和TCP/IP协议栈的对应关系,智能无损网络的技术架构如图1-3所示:
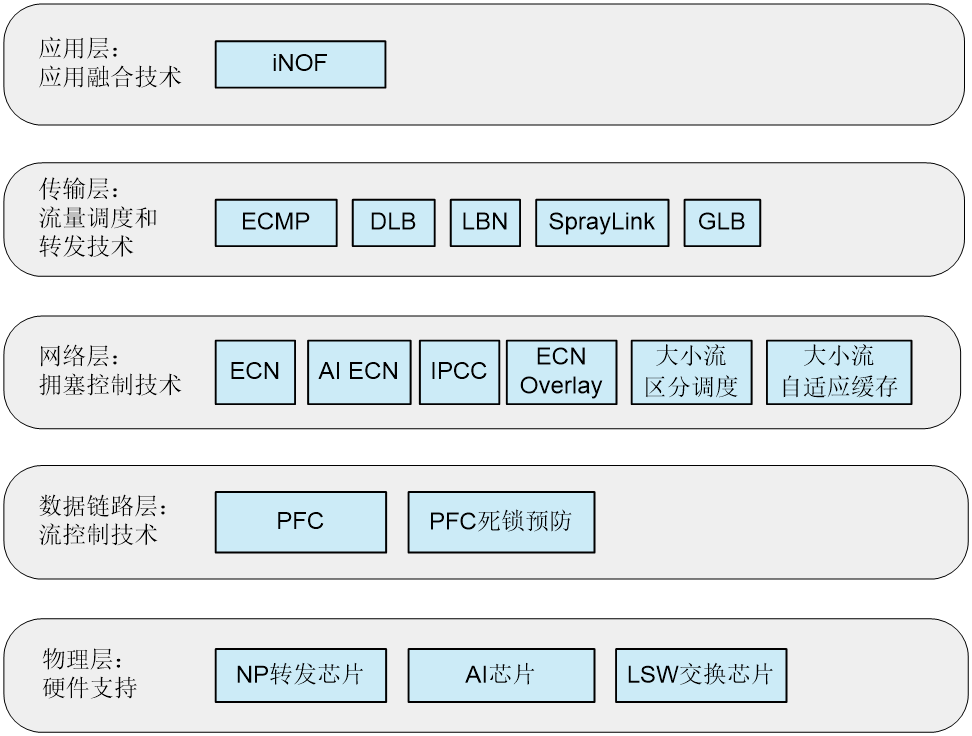
在智能无损网络中,PFC和ECN是必须配置的特性,其他特性可以根据实际情况进行选择性配置。
· 在物理硬件层,智能无损网络需要支持智能无损算法的AI芯片和转发/交换芯片的支持。
· 在数据链路层,部署流量控制技术PFC(Priority-based Flow Control,基于优先级的流量控制),同时预防PFC死锁问题。PFC技术由IEEE 802.1Qbb定义,用于解决拥塞丢帧问题。
· 在网络层,智能无损网络可以应用如下拥塞控制技术:
¡ ECN(Explicit Congestion Notification,显式拥塞通知)技术:ECN是一种端到端的网络拥塞通知机制,它允许网络在发生拥塞时不丢弃报文,在RFC 3168中定义。
¡ ECN Overlay技术:将ECN技术应用到VXLAN网络中,以实现VXLAN网络中端到端的拥塞通知机制。
¡ 大小流区分调度:设备端口转发报文时使用QoS的拥塞管理技术进行队列调度,提供不同的服务标准。网络中流量被管理员区分为大小流,并区分调度,以保证大流的吞吐率和小流的时延需求。
¡ 大小流自适应缓存:在设备上,小流队列和大流队列共享一块缓存空间来调度报文。开启大小流自适应缓存功能可以动态调节小流队列和大流队列所占共享缓存空间的大小。
¡ AI ECN功能:AI ECN结合了智能算法,可以根据智能算法对现网流量模型进行预测,并动态调整ECN的门限。
¡ IPCC(Intelligent Proactive Congestion Control,智能主动拥塞控制)是一种以网络设备为核心的主动拥塞控制技术,可以根据设备端口的拥塞状态,准确控制服务器发送RoCEv2报文的速率。
· 在传输层可以采用ECMP等技术对网络中的流量进行负载分担:
¡ ECMP(Equal-Cost Multipath Routing,等价多路径路由):路由表中到达同一目的地址的多个优先级和开销值相同、下一跳不同的多条路由构成等价路由。匹配等价路由的报文在多个下一跳上进行负载分担。
¡ DLB(Dynamic load balance,动态负载均衡)在芯片引入了硬件流表(FlowSet),可以记录某条流的状态,结合等价路径的状态信息,可以实现根据实时拥塞状态的等价路径成员的动态选择,优先选择负载较轻的链路进行转发。
¡ LBN(Load Balance Network,负载均衡网络)是一种网络级别的负载均衡技术。通过对端口进行分组和智能编排,形成入口和出口之间的一对一映射关系,将流量精准地负载分担到不同的出口,以提升网络吞吐率。
¡ SprayLink是一种端网融合负载均衡方案,由网络侧进行等价路由负载分担,由主机侧对负载分担后的报文进行乱序调整。网络侧逐包选择负载较轻的链路进行负载分担,解决传统等价路由负载分担不均,无法充分利用链路带宽的问题。
¡ GLB(Global Load Balancing,全局负载均衡)特性是在DLB特性基础上的一个功能扩展,主要是为了解决数据中心多跳网络中出现远端设备负载不均衡的问题。GLB在进行负载分担时会选择报文从本设备到目的设备之间负载最轻的链路。
· 在应用层,智能无损网络提供了iNOF(Intelligent Lossless NVMe Over Fabric,智能无损存储网络)功能,通过对iNOF主机的快速管控,提升存储网络的易用性,实现以太网和存储网络融合。
PFC(Priority-based Flow Control,基于优先级的流量控制)是构建无损以太网的必选手段之一,能够逐跳提供基于优先级的流量控制。
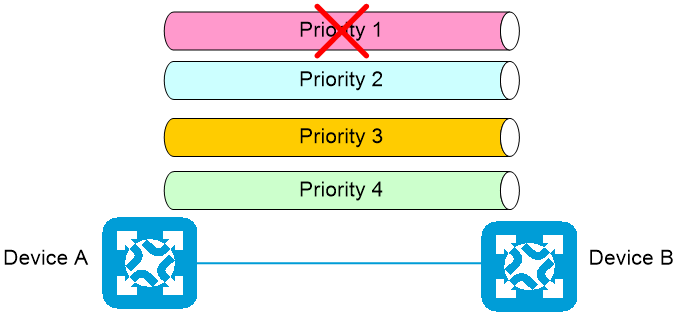
PFC允许网络设备根据不同的数据流的802.1p优先级进行流量控制。PFC允许在一条以太网链路上创建8个虚拟通道,并为每条虚拟通道指定一个802.1p优先等级。当特定优先级的流量拥塞时,网络设备可以向对端设备发送反压信号(PFC PAUSE帧),要求对端设备停止发送特定优先级的流量,以防止缓冲区溢出和数据丢失。这种个别流量控制方式允许网络在某些流量拥塞时保持流畅,同时防止对其他流量造成干扰。
如图2-1所示,Device A和Device B之间存在多个802.1p优先级的流量,每个优先级的流量采用单独的虚拟通道转发。当Device B设备指定优先级的报文发生拥塞时,设备会根据本端收到报文的802.1p优先级进行判别,从而确定对报文的处理方式:
· 如果Device B收到报文的802.1p优先级开启了PFC功能,则接收该报文,并向对端Device A发送PFC PAUSE帧,通知对端设备暂时停止发送该类报文。
· 对端Device A设备在接收到PFC PAUSE帧后,将暂时停止向本端发送该类报文。当拥塞仍然存在时,此过程将重复进行,直至拥塞解除。
· 如果Device B收到报文的802.1p优先级未开启PFC功能,则直接将报文丢弃。
· Device B收到的其他802.1p优先级的报文不受影响,可以正常处理。
如果Device A发生拥塞,也会采用上述过程通知Device B之停止发送该优先级的流量。
图2-1 PFC工作原理示意图
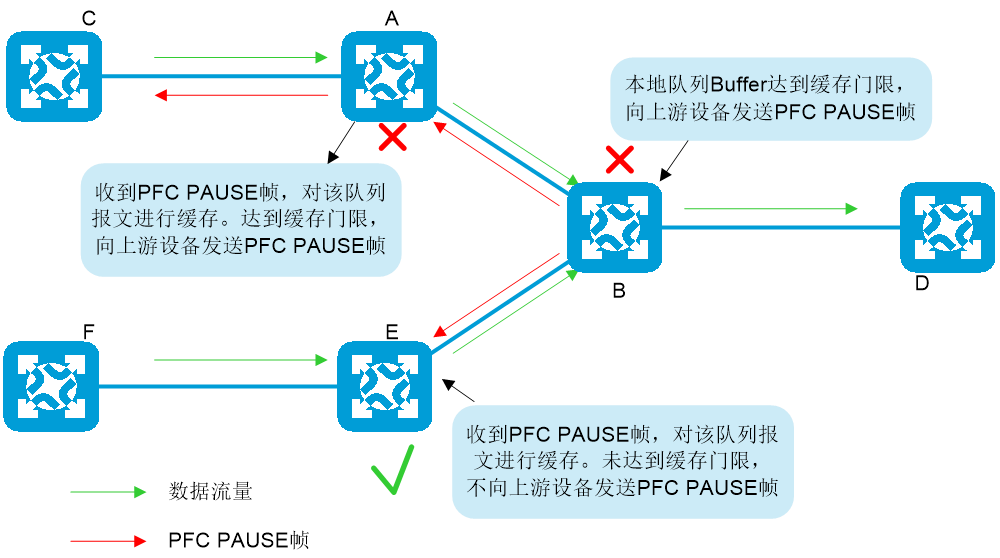
如图2-2所示,当Device B的出接口上某个队列产生拥塞时,导致本设备对应流量的入接口缓存超过门限,Device B向所有上游设备(数据报文的来源)发送PFC PAUSE帧。Device A接收到PFC PAUSE,会根据PFC PAUSE的指示,停止发送对应优先级的报文,并将数据存储到本地接口的缓存空间。如果Device A本地接口的缓存消耗超过缓存门限,则也向上游设备发送PFC PAUSE。如此,一级一级的发送PFC PAUSE,直到抵达网络终端设备,从而消除网络节点因拥塞造成的丢包。Device E接收到PFC PAUSE后,对该队列报文进行缓存,未达到Device E的缓存门限时,不向上游设备发送PFC PAUSE。
图2-2 多级设备之间的PFC PAUSE帧处理示意图
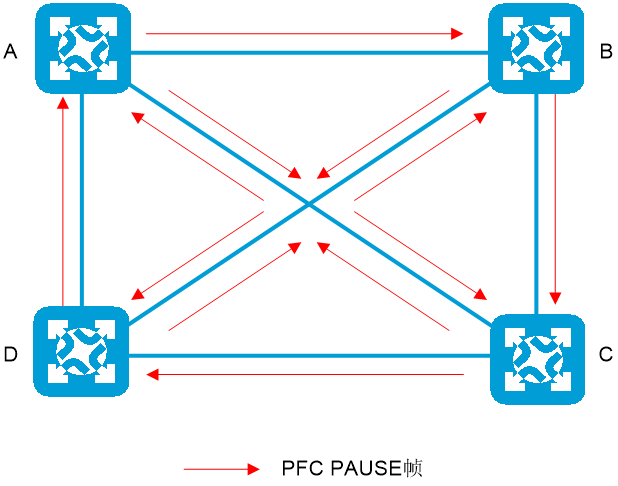
PFC死锁是指多个设备之间,因为环路等原因,同时出现了拥塞(各自端口缓存消耗超过了阈值),又都在等待对方释放资源,从而导致的“僵持状态”(所有交换机的数据流永久堵塞)。
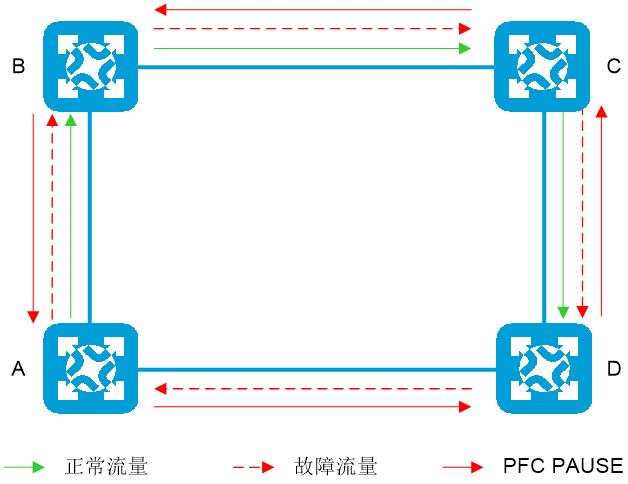
如图2-3所示,多个设备发生拥塞后互相发送PFC PAUSE帧,使PFC PAUSE帧在网络内泛洪,导致网络内设备无法转发报文,使整网业务瘫痪。
图2-3 PFC死锁产生示意图
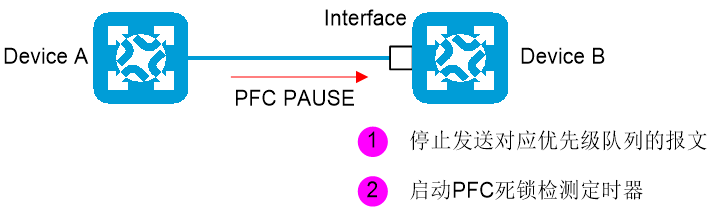
如图2-4所示,Device B的端口Interface收到来自Device A的PFC PAUSE帧后,停止发送对应优先级队列的报文。Device B启动PFC死锁检测定时器,在检测周期内检测该优先级队列收到的PFC PAUSE帧。
图2-4 触发PFC死锁检测示意图
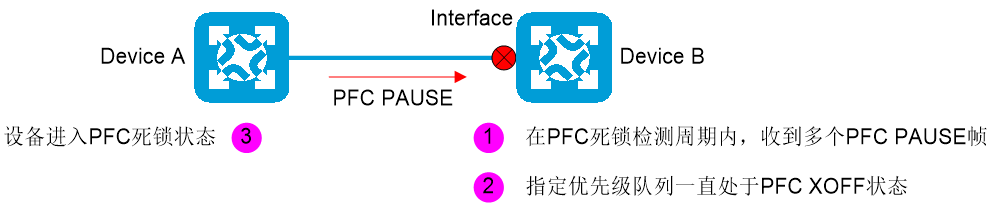
如图2-5所示,如果在PFC死锁检测周期内,Device B上端口Interface的指定优先级队列一直处于PFC XOFF(PFC反压帧触发门限)状态,即在检测周期内该优先级队列持续不断地收到PFC PAUSE帧,则Device B判定Device A发生死锁,进入死锁状态。
图2-5 PFC死锁判定示意图
![]()
PFC反压帧触发门限是缓冲区中某802.1p优先级报文在该存储空间使用的资源上限。该802.1p优先级报文占用的资源达到上限后,会触发设备发送PFC PAUSE帧。
设备检测到某个接口发生死锁后,将启动自动恢复定时器。在自动恢复周期内,设备将关闭该接口的PFC功能和PFC死锁检测功能,以忽略接口收到的PFC PAUSE帧。同时,设备对数据报文执行转发或丢弃动作(由管理员手工配置),以规避PFC死锁问题。
在自动恢复定时器超时后,设备将开启PFC功能和PFC死锁检测功能。如果经过死锁恢复后,仍不断出现PFC死锁现象,管理员可以设置PFC死锁的触发上限,当PFC死锁发生次数到达上限后,设备将强制关闭PFC功能和PFC死锁检测功能。待排除故障后,需要管理员手工恢复PFC功能和PFC死锁检测功能。
PFC死锁预防是指设备通过识别易造成PFC死锁的业务流,修改队列优先级,从而预防PFC死锁的发生。
如图2-6所示,正常情况下,业务流量转发路径为A-B-C-D。当网络的防环机制出现问题时,将会导致业务流量从D向A转发。故障流量在A-B-C-D间转发,形成环路。如果网络设备A~D接口的缓存空间中使用的资源达到PFC XOFF门限,则网络设备向故障流量的上游发送PFC PAUSE帧。PFC PAUSE帧在环网中持续发送,最终导致所有设备进入PFC死锁状态,整网断流。
图2-6 环网PFC死锁示意图
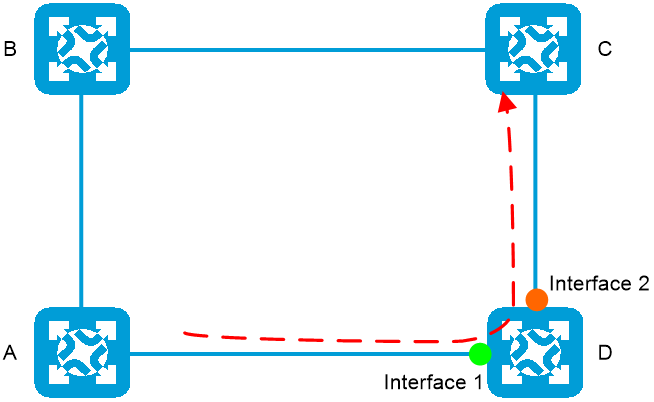
PFC死锁预防功能中定义了端口组概念,如图2-7所示,设备D上interface 1与interface 2属于同一端口组。当设备D检测到同一条业务流从属于该端口组的接口上进出,即说明该业务流是一条高风险业务流,易形成PFC PAUSE帧环路,引起PFC死锁。
![]()
具有相同PFC死锁预防功能配置的接口属于同一端口组。有关PFC死锁预防功能配置,请参见相关配置手册。
图2-7 PFC高风险业务流
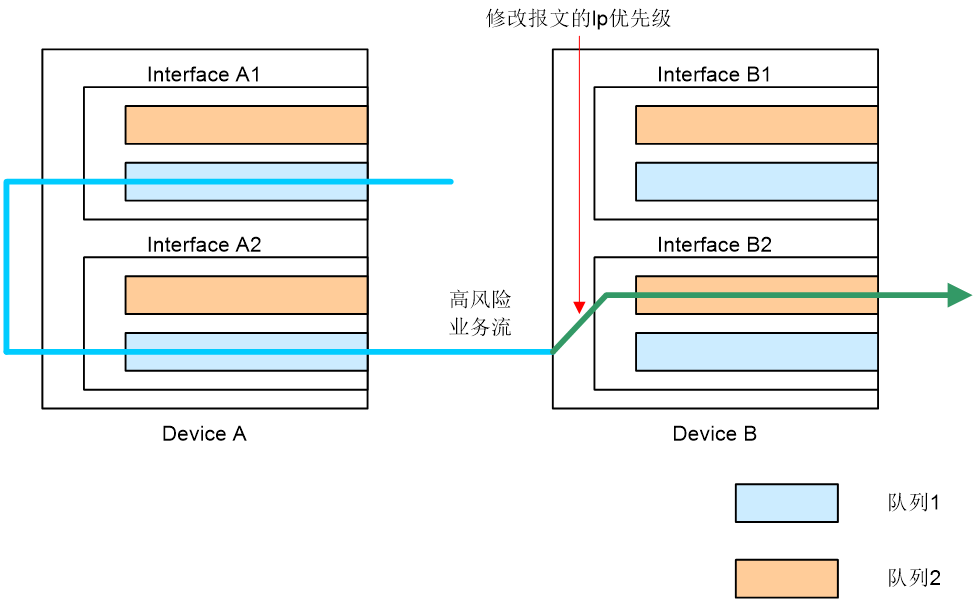
目前,PFC死锁预防仅针对携带DSCP值的业务流量。
设备收到报文后,会根据报文的DSCP值以及设备上dscp-lp的映射关系,将该报文加入指定lp优先级的队列转发。PFC死锁预防功能工作原理为:
(1) 部署端口组:管理员提前规划,将可能产生PFC PAUSE帧的接口划分到同一端口组。例如,一台Leaf交换机,将其上行口划分到同一端口组中。
(2) 识别高风险业务流。
(3) 修改映射关系:设备收到报文后,修改报文的DSCP值和对应的lp优先级,使报文在新的lp优先级队列中使用新的DSCP值转发。
如图2-8所示,Device A发送指定DSCP值的业务流量。Device B收到业务流量后,根据报文的DSCP值以及设备上dscp-lp的映射关系,让业务流量在队列1中转发。如果Device B检测到该业务流量为高风险业务流,易引起PFC死锁,则Device B会修改业务流量队列优先级,使业务流量切换到队列2转发,这样就可以规避队列1可能产生的PFC PAUSE帧,预防PFC死锁的产生。
图2-8 PFC死锁预防工作原理示意图
拥塞控制是指对进入网络的数据总量进行控制,使网络流量保持在可接受水平的一种方法。拥塞控制与流量控制的区别在于:
· 流量控制是由接收端来控制数据传输速率,防止发送端过快的发送速率引起接收方拥塞丢包;
· 拥塞控制是一个全网设备协同的过程,所有主机和网络中的转发设备均参与控制网络中的数据流量,以达到网络无丢包、低时延、高吞吐的目的。
在现网中,流量控制和拥塞控制需要配合应用才能真正解决网络拥塞。
在当前的数据中心网络中,ECN功能是应用最广泛的一种拥塞控制方法,本章节介绍ECN、ECNOverlay、大小流区分调度、AI ECN和IPCC等功能的基本原理。
ECN(Explicit Congestion Notification,显式拥塞通知)是一种拥塞通知技术,ECN功能利用IP报文头中的DS域来标记报文传输路径上的拥塞状态。支持该功能的终端设备可以通过报文中的ECN标记判断出传输路径上是否发生了拥塞,从而调整报文的发送方式,避免拥塞加剧。
在RFC 2481标准中,IP报文头中DS域的最后两个比特位被定义为ECN域,并进行了如下定义:
· 比特位6用于标识发送端设备是否支持ECN功能,称为ECT位(ECN-Capable Transport)
· 比特位7用于标识报文在传输路径上是否经历过拥塞,称为CE位(Congestion Experienced)
图2-9 IPv4报文头中的ECN域示意图

如图2-9所示以IPv4报文为例,RFC 3168对ECN域的取值进行如下规定:
· ECN域的取值为00时,表示该报文不支持ECN功能。
· ECN域的取值为01或者10时,表示该报文支持ECN功能,分别记为ECT(0)或ECT(1)。
· ECN域的取值为11时,表示该报文在转发路径上发生了拥塞,记为CE。
ECN功能需要和WRED策略配合应用。
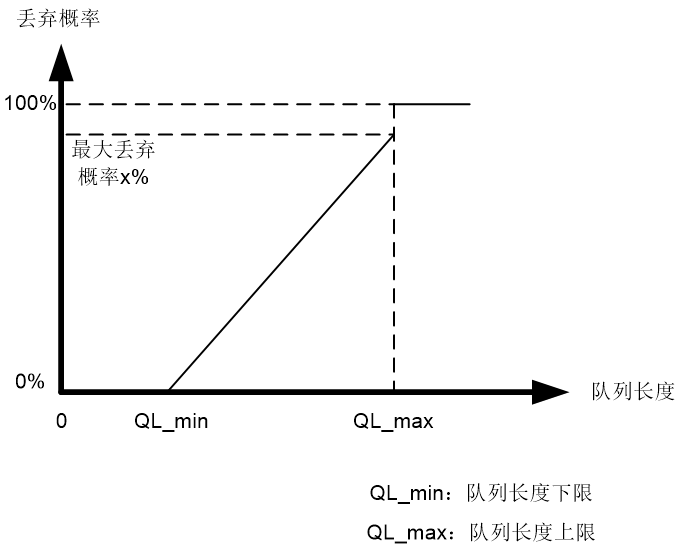
如图2-10所示,没有开启ECN功能的WRED策略按照一定的丢弃策略随机丢弃队列中的报文,WRED策略为每个队列都设定上限长度QL_max和下限长度QL_min,对队列中的报文进行如下处理:
· 当队列的长度小于下限QL_min时,不丢弃报文;
· 当队列的长度超过上限QL_max时,丢弃所有到来的报文;
· 当队列的长度在上限QL_max和下限QL_min之间时,开始随机丢弃到来的报文。队列越长,丢弃概率越高,队列丢弃概率随队列长度线性增长,不超出最大丢弃概率x%。
图2-10 WRED丢弃概率与队列长度示意图
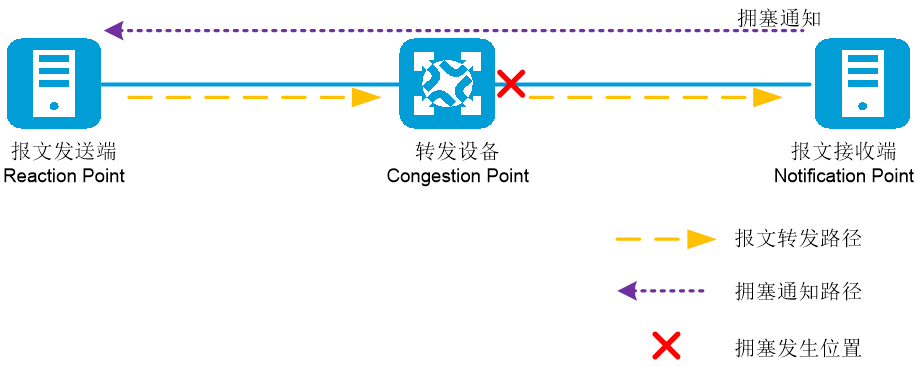
· 如图2-11所示,在部署ECN功能的WRED策略的组网图中,存在三类设备角色:
· 转发设备(Congestion Point):报文在网络中转发路径上经过的设备,转发设备支持ECN功能,可以识别报文中ECN域的取值。报文在转发设备的接口上可能发生拥塞,所以转发设备又称为Congestion Point,转发设备需要部署ECN功能的WRED策略。
· 报文接收端(Notification Point):接收端设备网卡支持ECN功能,可以识别报文中取值为01、10或者11的ECN域。接收端同时作为拥塞通知的发起设备,收到ECN域取值为11的报文时,将每隔时间周期T1发送拥塞通知报文给报文发送端,要求发送端降低报文发送速率。
· 报文发送端(Reaction Point):发送端设备网卡支持ECN功能,从发送端发出报文的ECN域的取值为01或者10。发送端同时作为拥塞通知的应答设备,收到拥塞通知时,将以一定的降速比率降低当前自身发送报文的发送速率,并开启计时器,当计时器超出时间T2(T2>T1)后,发送端设备未再次收到拥塞通知,则发送端认为网络中不存在拥塞,恢复之前的报文发送速率。当计时器在时间T2(T2>T1)内,发送端设备再次收到拥塞通知,则发送端进一步降低报文发送速率。
图2-11 部署ECN功能的WRED策略的组网图
部署了ECN功能的WRED策略的转发设备(Congestion Point)对接收到的数据报文进行识别和处理的具体处理方式如下:
· 当转发设备的报文在出方向进入队列排队,该队列的长度小于下限QL_min(QL_min也称为ECN低门限)时,不对报文进行任何处理,转发设备直接将报文从出接口转发。
· 当转发设备的报文在出方向进入队列排队,该队列的长度大于下限QL_min但小于上限QL_max(QL_max也称为ECN高门限)时:
¡ 如果设备接收到的报文中ECN域取值为00,表示报文发送端不支持ECN功能,转发设备按照未开启ECN功能的WRED策略处理,即随机丢弃接收的报文。
¡ 如果设备接收到的报文中ECN域取值为01或者10,表示报文发送端支持ECN功能,将按照WRED策略中的线性丢弃概率来修改部分入方向报文的ECN域为11后继续转发该报文,所有入方向接收到的报文均不丢弃。
¡ 如果设备接收到的报文中ECN域取值为11,表示该报文在之前的转发设备上已经出现拥塞,此时转发设备不处理报文,直接将报文从出接口转发。
· 当转发设备的报文在出方向进入队列排队,该队列的长度大于上限QL_max时:
¡ 如果设备接收到的报文中ECN域取值为00,表示报文发送端不支持ECN功能,转发设备按照未开启ECN功能的WRED策略处理,即丢弃接收的报文。
¡ 如果设备接收到的报文中ECN域取值为01或者10,表示报文发送端支持ECN功能,将100%修改入方向报文的ECN域为11后继续转发该报文,所有入方向接收到的报文均不丢弃。
¡ 如果设备接收到的报文中ECN域取值为11,表示该报文在之前的转发设备上已经出现拥塞,此时转发设备不处理报文,直接将报文从出接口转发。
合理设置ECN门限可以缓解拥塞的同时保证网络的时延和吞吐率。
上述ECN域标识的修改过程是转发设备在出方向报文检测到拥塞后,修改入方向报文ECN域标识。设备在处理过程中存在一定延时,为了加快该流程,转发设备在出方向队列检测到拥塞后,直接修改出方向报文的ECN域标识,这个技术称为Fast ECN。
相较于未部署ECN功能的WRED策略,部署了ECN功能的WRED策略具备如下优势:
· 通过合理设置WRED策略中队列长度的下限值,可以使转发设备提前感知到路径上的拥塞,并由报文接收端通知报文发送端放缓发送速率。
· 在转发设备上,对超出队列长度上限值的报文仅标记ECN域为11,而不再丢弃报文,避免网络中报文丢弃和重传的过程,减少了网络时延。
· 网络中出现拥塞时,发送端在一定时间内逐步降低报文发送速率,在拥塞现象消失后,发送端逐步提升报文发送速率,避免出现网络吞吐量在拥塞前后快速振荡的情况。
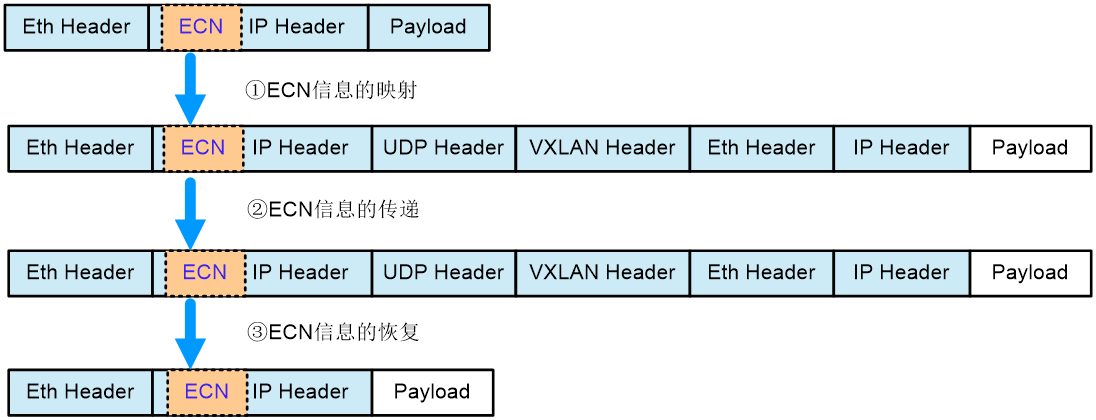
ECN Overlay功能是指在VXLAN网络中使用ECN功能,即在VXLAN网络中设备出接口发生拥塞时,报文的ECN域可以被标记为CE,并且设备可以正常传递携带CE标记的报文,而不会丢失ECN域中的标记信息。
VXLAN网络中拥塞发生的位置不同,报文ECN域处理流程和传递ECN信息的过程略有不同。如图2-12所示,VXLAN隧道入节点的出接口发生拥塞为例,报文ECN域处理流程和传递ECN信息的过程为:
(1) ECN信息的映射:在VXLAN隧道的发起端检测到拥塞时,设备将原始IP报文的ECN域标记为CE。报文发送时,将原始IP报文进行VXLAN封装,此时设备将原始IP报文ECN域的CE映射到VXLAN报文外层IP头部的ECN域中。
(2) ECN信息的传递:在VXLAN网络中传递的报文将携带CE标记,Underlay的中转设备不进行修改。
(3) ECN信息的恢复:在VXLAN隧道的终结端解封装VXLAN报文时,执行第一步中相反的操作,即设备将VXLAN报文外层IP头部的ECN域中的信息复制到原始IP报文的ECN域中。
如果VXLAN网络的中转发设备的出接口上发生拥塞,则仅在Underlay的中转设备上标记VXLAN报文外层IP头部的ECN域,并且在VXLAN隧道的终结端将ECN域中的信息复制到原始IP报文的ECN域中。如果VXLAN隧道出节点的出接口发生拥塞,则仅需要执行上述ECN信息的恢复步骤。
图2-12 ECN Overlay工作原理示意图
网络中充斥着各种各样的流量,我们可以简单的将其分为大流和小流。
· 大流(Elephant Flows,大象流):大流通常是业务数据流量,如文件传输、数据库同步和数据备份信息。大流的特点是数量虽少,却占用了网络中相当大的带宽资源,对吞吐率有要求,对时延不敏感。大流占网络流总数的10%左右,但其承载了网络总数据量的85%。
· 小流(Mice Flows ,老鼠流):小流通常是用来建立连接的协议流量,如网页请求、协议信令消息等等。小流的特点是它们在网络中出现非常频繁,数量众多,但每个流的数据量小,对时延敏感,对带宽和吞吐率的要求较低。网络流量中的绝大多数都是小流。
突发大流引起的网络拥塞,可能会增加小流的时延,并引发小流丢包。因此,在调度流量避免拥塞时,优先保障小流的调度和时延至关重要。在无损网络中我们希望将大小流区分调度,以满足小流的延迟需求和大流的吞吐率需求。
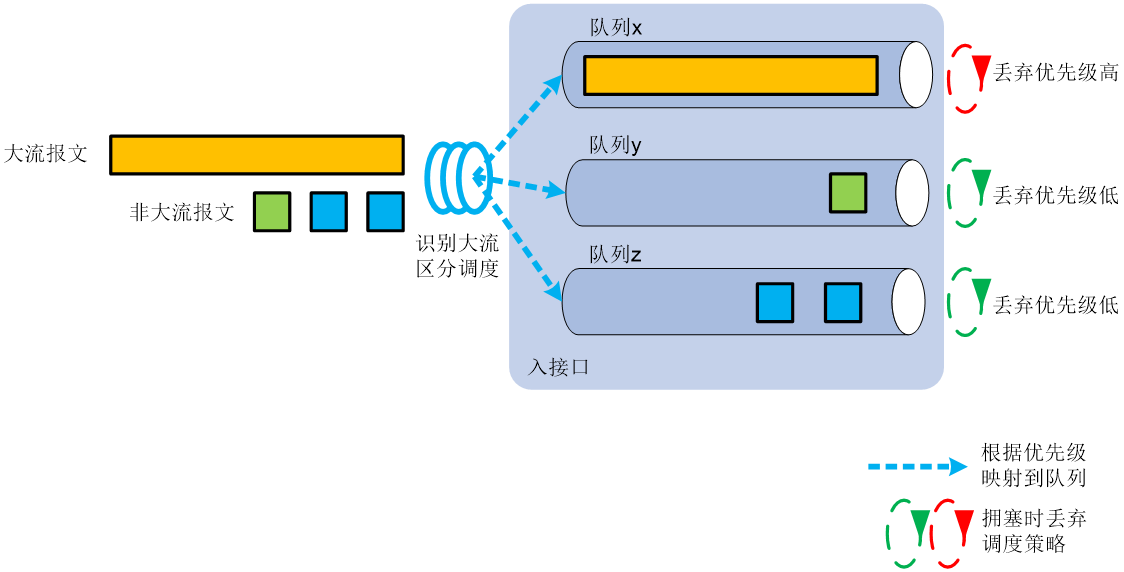
如图2-13所示,大小流区分调度机制如下:
(1) 网络管理员配置大流识别参数(流速和尺寸),设备根据识别参数将网络流量中的大流识别出来;
(2) 网络管理员为大流指定丢弃优先级、本地优先级或dot1q优先级,设备根据本地优先级或者dot1q优先级将识别出来的大流映射到特定的队列中,与其他非大流区分调度。一旦发生拥塞,设备也可以根据配置的丢弃优先级,优先丢弃大流报文,以保证小流的低延迟体验。
大小流区分调度可以在一定程度上解决小流被大流阻塞的问题,但在网络中如果绝大多数流量都是小流的场景或者突发流量等情况下,通过静态配置识别参数的大小流区分调度功能优化的效果不佳,例如数据中心网络中绝大多数流量是对时延更敏感的小流。对于上述场景,可以开启大小流自适应缓存功能。
在设备上,小流队列和大流队列共享一块缓存空间来调度报文。开启大小流自适应缓存功能可以动态调节小流队列和大流队列所占共享缓存空间的大小。
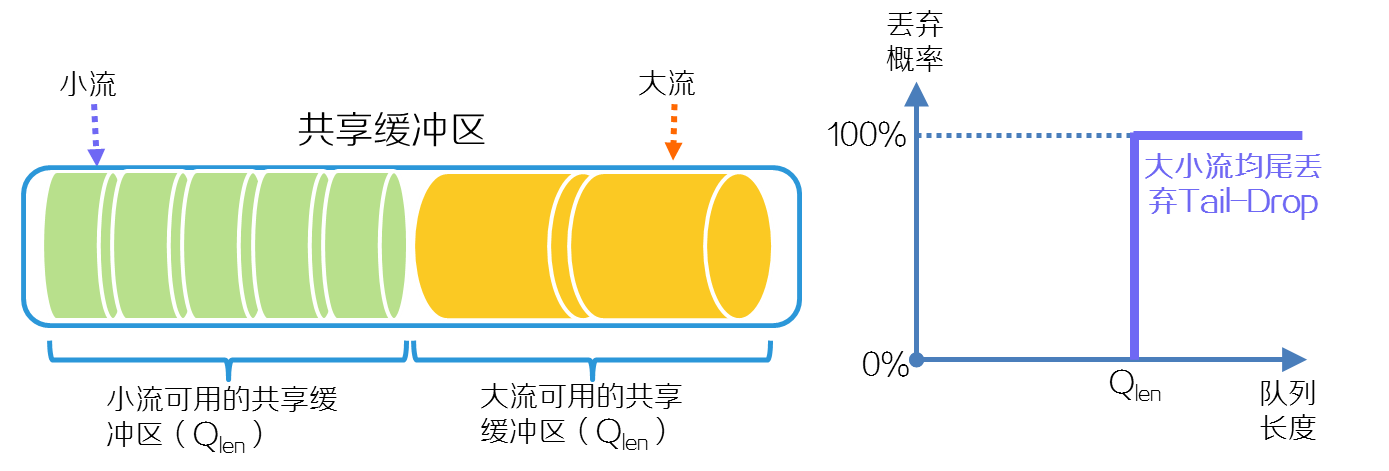
大小流自适应缓存功能的工作机制如下:
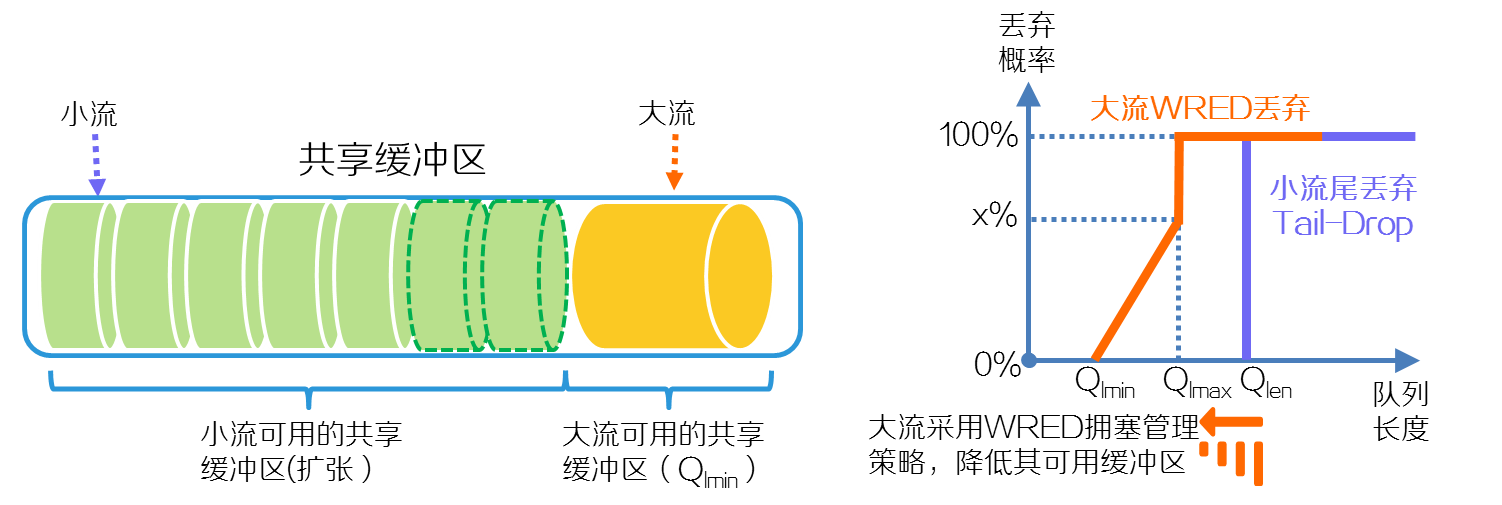
(1) 如下图所示,缺省情况下,设备中的不同队列均分共享缓冲区,队列之间允许互相抢夺竞争缓冲区资源。网络拥塞时,造成拥塞的队列可能竞争得到较多的共享缓冲区资源。共享缓冲区占满之后,大小流均采取尾丢弃的策略来丢弃报文,即新进入缓冲区的大流和小流均被丢弃,丢弃的报文引发重传机制,重传的报文时延变大,因此,小流的时延无法保障。
图2-14 未启用大小流自适应缓存功能
(2) 启用大小流自适应缓冲技术后,如果发生网络拥塞出现丢包,系统自动调整大流为WRED拥塞管理策略,标记大流的丢弃优先级为黄色,并且降低大流的WRED丢弃门限,队列长度超出Qlmin门限,开始丢弃大流。系统限制大流可占用的共享缓存区降低到Qlmin门限以内。大流减少的缓冲区资源被小流抢占。
图2-15 启用大小流自适应缓存功能时小流丢包
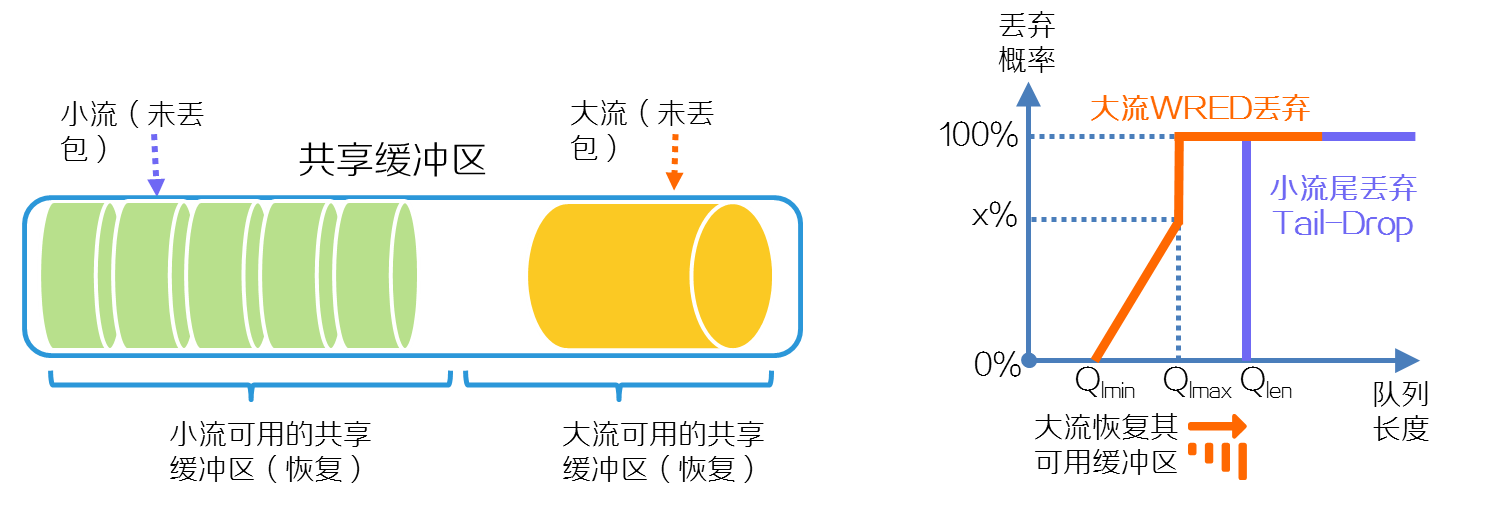
(3) 一段时间周期内,如果仍出现网络拥塞和丢包现象,则继续降低大流的WRED丢弃门限,限定大流可用的共享缓存区大小。系统可以多次降低大流可用的共享缓存区大小。
(4) 一段时间周期内,如果不再出现丢包,则逐渐恢复大流的WRED丢弃门限,直到大流最终恢复到缺省的尾丢弃策略。
图2-16 启用大小流自适应缓存功能时小流不再丢包
各个队列转发的数据流量特征会随时间动态变化,网络管理员通过静态设置ECN门限时,并不能满足实时动态变化的网络流量特征:
· ECN门限设置过高时,转发设备将使用更长的队列和更多缓存来保障流量发送的速率,满足吞吐敏感的大流的带宽需求。但是,在队列拥塞时,报文在缓存空间内排队,会带来较大的队列时延,不利于时延敏感的小流传输。
· ECN门限设置偏低时,转发设备使用较短的队列和少量缓存尽快触发来降低队列排队的时延,满足小流对时延的需求。但是,过低的ECN门限会降低网络吞吐率,影响吞吐敏感的大流,限制了大流的传输。
另一方面网络中如果同时部署了PFC和ECN功能时,我们希望ECN门限设置可以保证设备优先触发ECN功能,降低报文发送端的速率缓解拥塞情况,而非先触发PFC功能直接通知发送端停止发送报文。只有当ECN功能触发后未缓解拥塞,拥塞反而严重恶化时才触发PFC功能,此时通知发送端停止数据报文发送,直到拥塞缓解后再通知继续发送数据报文。ECN和PFC同时部署减缓拥塞时的作用顺序应如下图所示:
图2-17 ECN和PFC同时部署减缓拥塞示意图
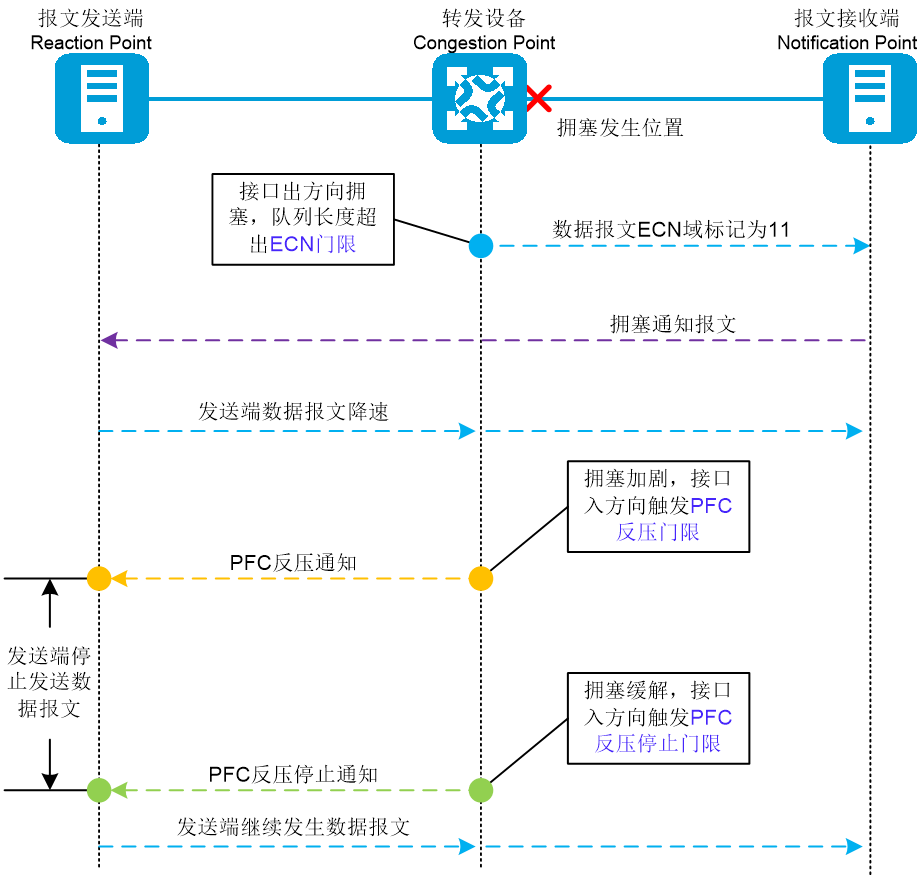
由图2-17流程可知,当拥塞发生时,从转发设备发送ECN域标记为11的数据报文到报文发送端降速的过程中,发送端仍以原速率持续发送数据报文,这段时间内网络中的拥塞将进一步恶化,只有合理并动态设置ECN低门限,设备才能尽量避免PFC触发影响网络中的吞吐率。
基于以上原因,我们需要一种智能地实时ECN低门限控制功能,这种功能称为AI ECN功能。
AI ECN利用设备本地的AI业务组件,按照一定流量模型算法动态优化ECN门限。
图2-18 AI ECN功能实现示意图
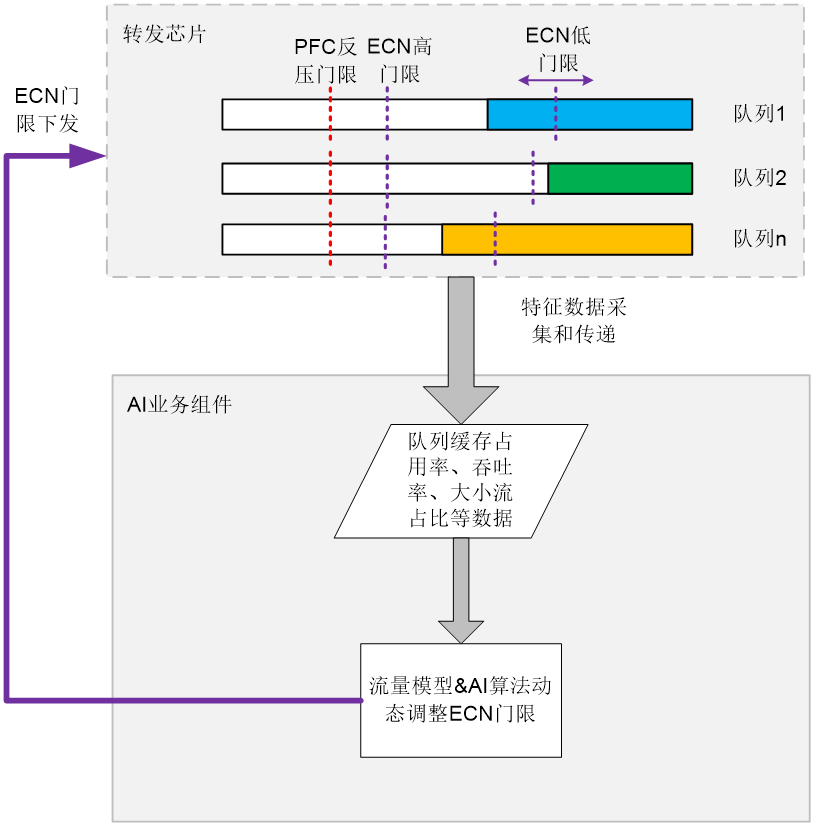
设备内的转发芯片会对当前流量的特征进行采集,比如队列缓存占用率,流量吞吐率,当前大小流占比等特征数据,然后将网络流量实时信息传递给AI业务组件。
AI ECN功能启用后,AI业务组件收到推送的流量状态信息后,将智能的对当前的流量特征进行判断,识别当前的网络流量场景是否符合已知的流量模型。
· 如果该流量模型符合大量已知流量模型中的一种,AI业务组件将根据已知流量模型推理出实时ECN门限最优值。
· 如果该流量模型不符合已知流量模型,AI组件将基于现网状态,在保障高带宽、低时延的前提下,对当前的ECN门限不断进行实时修正,最终计算出最优的ECN门限配置。
最后,AI业务组件将最优ECN门限下发到设备转发芯片中,调整ECN门限。
AI ECN能够根据流量特征和变化而实时调整ECN门限:
· 当队列中小流占比高时,降低ECN触发门限,保证多数小流的低时延性。
· 当队列中大流占比高时,提高ECN触发门限,保证多数大流的高吞吐性。
根据设备芯片和硬件能力,AI ECN功能实现的模式有三类,采用不同的AI ECN功能模式,设备获取ECN门限的方式不同:
· 网络中设备的ECN门限由分析器集中计算并传递给设备,实现拥塞通知功能,这种方式AI ECN功能由分析器完成计算分析,对设备本身硬件能力要求较低。
· 设备本地实现的分布式AI ECN功能,设备智能地为队列设置最佳的ECN门限,这种方式AI ECN功能对设备硬件算力要求较高,可能消耗设备CPU资源。
· 设备的神经网络功能实现的AI ECN功能,神经网络算法智能地为队列设置最佳的ECN门限,需要设备硬件芯片支持该功能的算法。
IPCC(Intelligent Proactive Congestion Control,智能主动拥塞控制)与ECN技术类似,也是一种通过拥塞通知报文来通知发送端降低报文发送速率,从而避免网络拥塞的技术。IPCC是由网络设备主动发起的拥塞控制技术。用于转发RoCEv2报文的网络设备接口如果开启了IPCC功能,则设备根据该接口的拥塞情况,主动发送拥塞通知报文通知报文发送端降低发送报文的速率,并且设备可以基于接口队列的拥塞严重程度,智能计算出需要发送拥塞通知报文的数量,精准调整控制发送端发送报文的降速,避免发送端过度降低速度。
IPCC和传统ECN技术的对比如表2-1所示。
表2-1 IPCC和传统ECN技术对比
|
技术对比 |
IPCC |
传统ECN |
|
发送拥塞通知报文位置 |
转发报文的网络设备 |
报文的接收端 |
|
报文拥塞的响应过程 |
直接主动响应。由网络中出现拥塞点的设备发送拥塞通知给报文发送端,拥塞点快速触发,通知发送端降速 |
间接被动响应。被标记的报文需传播整条转发路径抵达接收端后再由接收端发送拥塞通知报文通知发送端降速 |
|
发送端降速的效果 |
出现拥塞点的网络设备根据拥塞接口上队列长度和缓存占用,智能计算需要发送的拥塞通知报文个数,精确控制发送端降速 |
报文接收端如果持续收到ECN域取值为11的报文时,将每隔一定时间周期发送拥塞通知报文给报文发送端降速,降速效果滞后于拥塞点的实际变化 |
|
应用场景 |
仅对RoCEv2报文生效 |
对于TCP、UDP等报文均能生效,适用范围更广 |
|
硬件支持要求 |
需要硬件芯片和驱动支持 |
需要硬件芯片和驱动支持 |
由表2-1比较可知,IPCC在ECN功能基础上进行改进,使转发设备具备发送拥塞通知报文的能力,对于网络中拥塞控制更加准确和迅速。
由于IPCC功能仅对RoCEv2报文生效,下面先简单介绍RoCEv2报文的结构和报文的关键信息。
RoCEv2和InfiniBand是目前主流的RDMA协议,但相较于InfiniBand,RoCEv2是基于以太网的RDMA协议。如图2-19所示,RoCEv2是基于UDP协议封装的,其中RoCEv2报文的目的端口号固定为4791。RoCEv2和InfiniBand主要变化在数据链路层和网络层,RoCEv2报文传输层继承了InfiniBand报文中传输层的Base Transport Header和Extended Transport Header的结构和信息。
图2-19 RoCEv2与InfiniBand报文格式对比
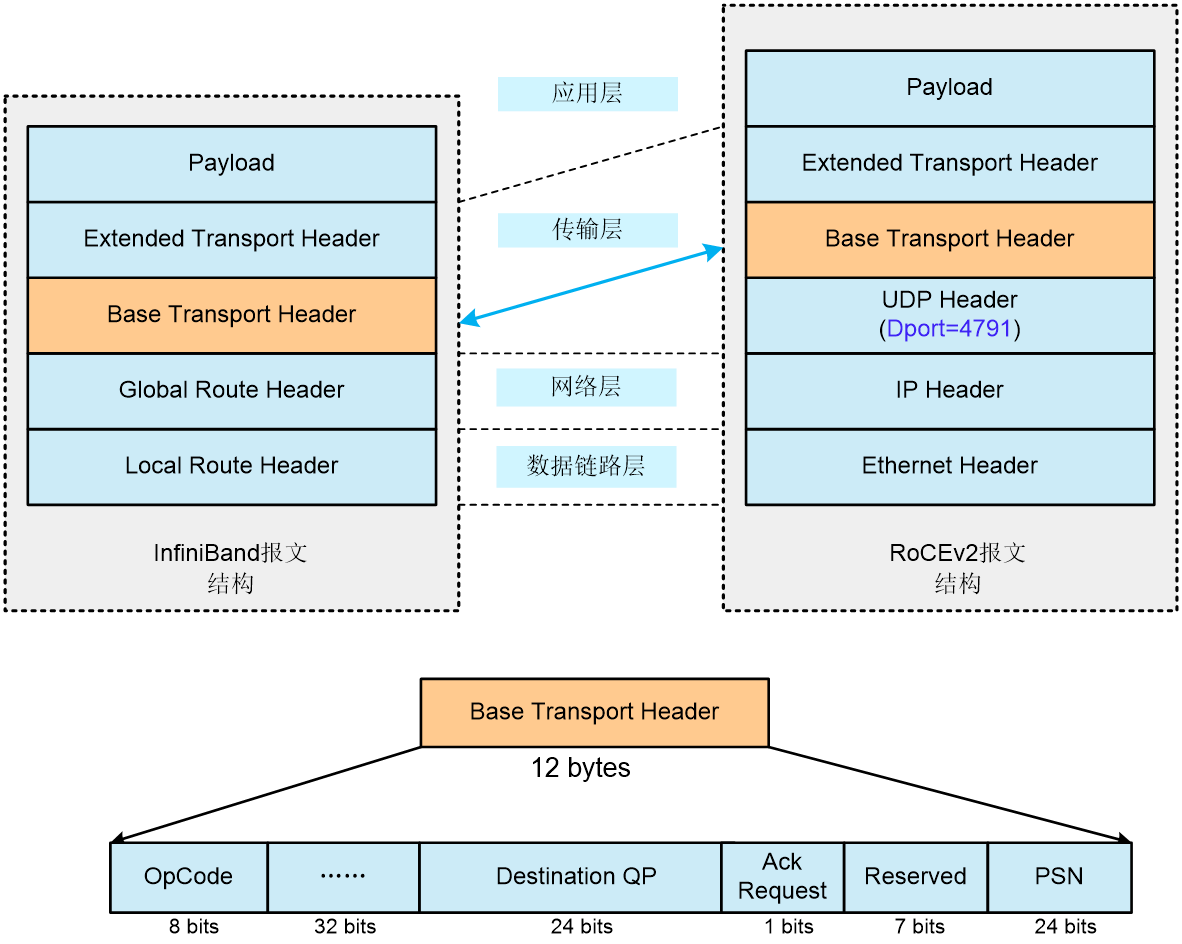
根据InfiniBand Architecture Specification标准中的定义,BTH(Base Transport Header,基本传输层报文头)中包含了RoCEv2报文的关键信息,其中部分字段的含义如下:
· OpCode:表示RoCEv2的操作类型,也标识了BTH之后携带的ETH(Extended Transport Header,扩展传输层报文头)的类型。具体类型包括但不限于:
¡ Send:此类操作用于发送端向远端请求传递数据,发送端不指定接收端存储数据的地址。
¡ RDMA Write:此类操作用于发送端向远端请求写入数据,发送端会在报文中指定接收端存储数据的地址、key(关键值)和数据长度。
¡ RDMA Read:此类操作用于发送端向远端请求读取数据,发送端会在报文中会指定远端请求读取数据的地址、key和数据长度。
¡ ACK:表示ACK报文,远端接收到一组RoCEv2报文,会反馈的应答消息。
操作类型为Send、Write和Read的RoCEv2报文也被称为RoCEv2数据报文。
· Destination QP(Destination Queue Pair):目的端的队列编号,用来标识一条RoCEv2流。通常,在RoCEv2数据报文中执行一个Send、RDMA Write和RDMA Read操作时,发送端和目的端都会创建一个队列,生成一个队列对QP。发送队列用于存储发送端的消息和请求,接收队列用于存储远端发送的消息或请求。Destination QP是用来建立RoCEv2流表的关键信息。
· ACK Request:应答响应要求标记位,表示是否要求远端发送ACK的响应。
· PSN(Packet Serial Number):表示RoCEv2报文的序列号,可通过检测PSN是否连续来判断是否存在丢失的数据包,若出现了丢包,就会返回NAK报文。
图2-20 IPCC工作原理图
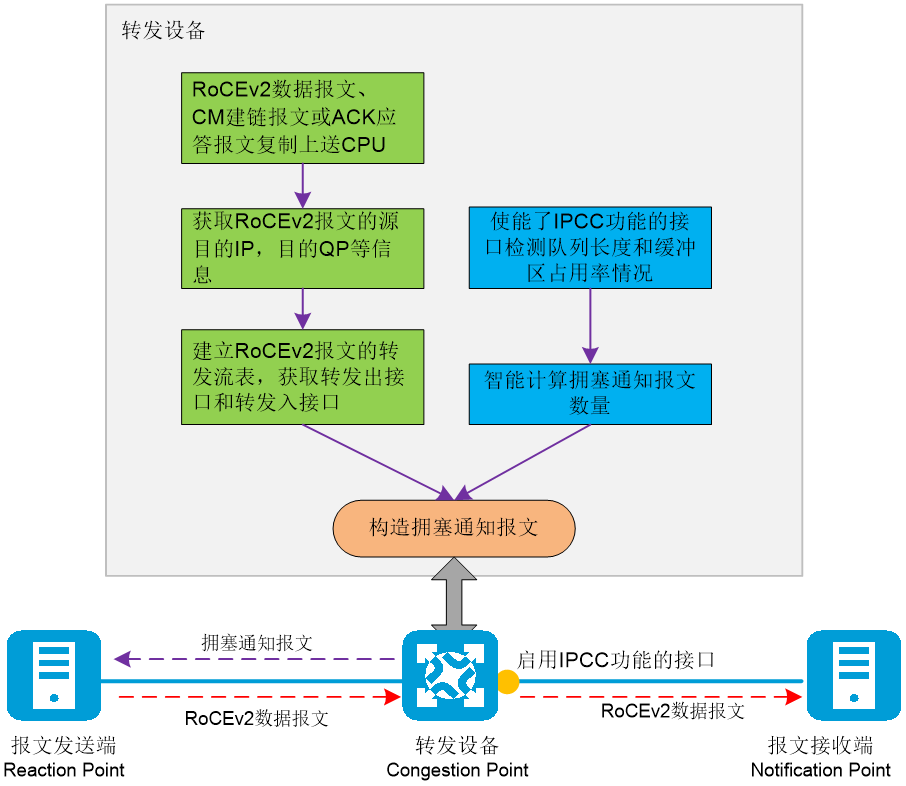
IPCC的工作原理如图2-20所示。
· 建立RoCEv2流表:在转发设备上,启用了IPCC功能的接口复制经过该设备的RoCEv2数据报文,并将其上送到设备的CPU处理。根据RoCEv2报文的源IP地址、目的IP地址和目的QP信息等信息建立RoCEv2流表。RoCEv2流表中包括流量的入方向接口和出方向接口、出接口队列的相关信息。
持续存在RoCEv2流量时,设备上保持并维护RoCEv2流表。如果出接口上发生拥塞则可以判断根据RoCEv2流表定位到该业务流的出入接口。
· 智能计算拥塞通知报文数量:转发设备对接口中启用了IPCC功能的队列进行检测,根据队列长度以及队列占用缓存空间的比率变化智能计算主动发送的拥塞通知报文数量。
¡ 当队列长度增加,队列缓存占用率较少,则发送少量拥塞通知报文给发送端,缓解队列拥塞,但不会使发送端过渡降速;
¡ 当队列长度增加,队列缓存占用率较多,则发送较多的拥塞通知报文给发送端,快速缓解队列拥塞,降低转发时延。
¡ 当队列长度减少,队列缓存占用率较少,则不发送拥塞通知报文给发送端,防止降速造成吞吐率下降;
¡ 当队列长度减少,队列缓存占用率较多,则发送少量拥塞通知报文给发送端,在尽量保证吞吐率和时延性能的情况下缓解队列拥塞。
转发设备根据RoCEv2流表中的地址信息构造拥塞通知报文,并主动将拥塞通知报文发送给发送端。发送的拥塞通知报文数量为上一步中计算出的报文数目。发送端收到拥塞通知报文后,通过降低RoCEv2报文的发送速率来缓解网络拥塞。
IPCC功能克服了传统ECN所面临的局限性,它通过更精细的算法来确定何时以及如何发送拥塞通知报文。这种改进方法依赖于对网络状况的实时分析,以计算出恰当的拥塞通知报文发送频率。该机制确保拥塞通知的发送既迅速又精确,以便及时地缓解网络拥塞情况,而不会引起不必要的性能下降。IPCC功能通过动态调整通知报文的发送,优化了网络流量管理,从而提高了整个网络的数据传输效率和稳定性。
智能无损网络是一系列技术的集合,它一方面通过流量控制技术和拥塞控制技术来提升网络整体的吞吐量,降低网络时延,另一方面通过智能无损存储网络等技术实现网络和应用系统融合优化。
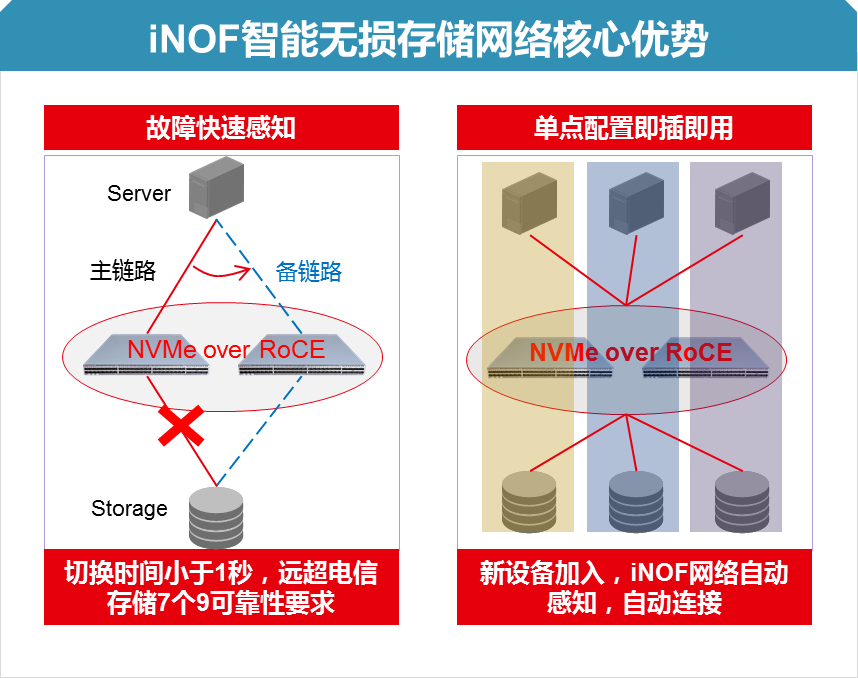
iNOF(Intelligent Lossless NVMe Over Fabric,智能无损存储网络)就是一种以太网和存储网络的融合优化技术。它能实现海量存储设备的自动发现,网络故障的快速感知,并将存储设备的加入和离开第一时间通知给智能无损网络内的所有设备,为实现智能无损网络的“无丢包、低时延、高吞吐”提供基础支持。
iNOF有两种典型组网:iNOF直连组网和iNOF跨交换机组网,这两种组网的适用场景不同,原理机制也不同。
iNOF网络中,包括以下三个重要元素:
· iNOF主机:支持iNOF协议的网络服务器和磁盘设备,以下简称主机。
· iNOF交换机:用于接入主机且支持iNOF功能的交换机。
· iNOF域(Zone):iNOF使用域来管理主机。当域内有主机加入或者离开,iNOF会将这个主机的加入和离开信息通知给同一域内的其它主机,以便其它主机能够感知同一域内任一主机的加入或者离开。
为方便管理,iNOF域分为两类:
¡ 自定义iNOF域:用户根据组网需求手工创建的iNOF域,需要手工向其中添加主机。
¡ 缺省iNOF域:设备出厂即存在的iNOF域,无需用户创建,不能删除。对于未加入自定义iNOF域的主机,用户可以选择是否自动让它加入缺省iNOF域。
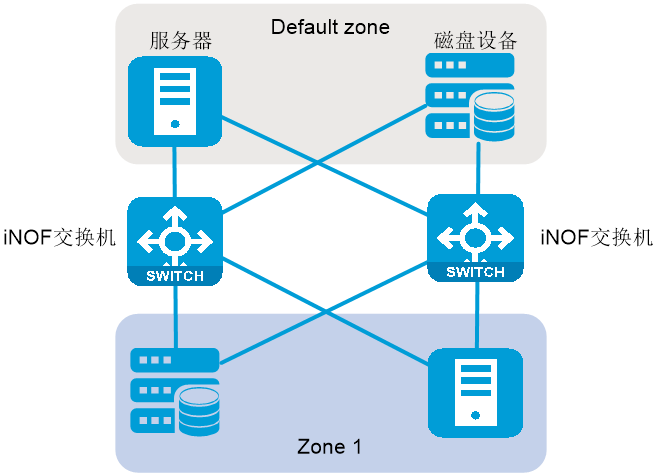
iNOF直连组网如图2-21所示,它要求同一域内的所有主机和同一iNOF交换机直连。主机和iNOF交换机之间通过交互二层报文,来通知主机状态变化(即主机加入或离开iNOF网络,也称为主机上线/离线),iNOF交换机之间不交互iNOF相关信息。iNOF直连组网适用于小规模网络。
图2-21 iNOF直连组网示意图
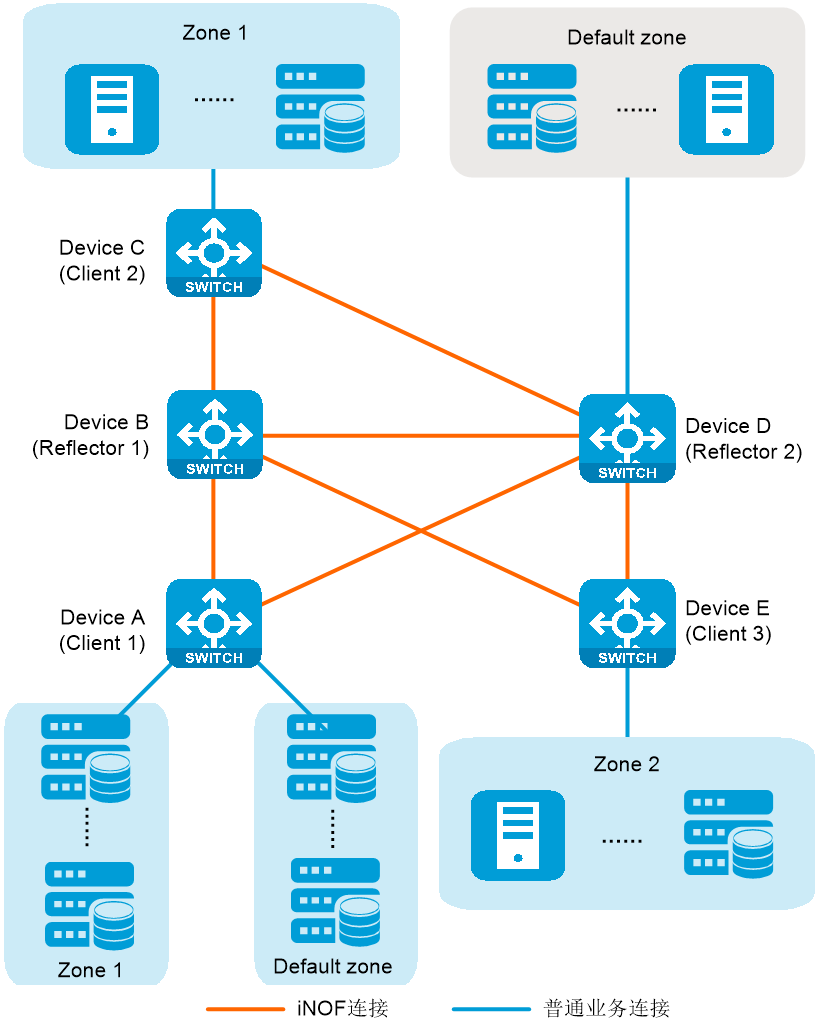
iNOF跨交换机组网如图2-22所示,它支持同一域内的主机可以连接在不同的iNOF交换机上,iNOF交换机之间通过iNOF报文传递域内所有主机的加入或离开信息。iNOF跨交换机组网适用于规模较大的数据中心,这样的数据中心拥有多台主机,主机属于不同的组织或部门(对应不同的iNOF域),同一组织或部门的主机通过多台iNOF交换机相连。
为了跨交换机传递主机信息,通常要求iNOF交换机之间全部两两建立直连连接,这种全连接的方式增加了维护复杂度,不利于后续iNOF交换机的加入。H3C基于成熟的BGP技术,将BGP协议进行扩展,复用BGP反射器技术,来实现iNOF跨交换机组网。
在iNOF跨交换机组网中:
· iNOF交换机和主机直连,iNOF交换机和主机之间交互的报文和报文交互流程同iNOF直连组网。
· iNOF交换机之间基于IBGP连接建立iNOF连接,通过BGP报文携带iNOF路由信息,利用BGP反射器技术,将一台iNOF交换机感知到的主机状态变化通知给域内的所有iNOF交换机。iNOF路由信息包括主机的加入或离开信息,以及iNOF的配置信息。
![]()
在iNOF跨交换机组网中,为简化组网,必须至少部署一台iNOF反射器,其它iNOF交换机均为客户机。所有客户机和反射器连接,客户机和客户机之间不建议连接,主机和iNOF反射器、iNOF交换机直连。因为客户机和客户机之间连接容易导致组网的复杂性,在路由快速变化时可能会出现路由表项短暂波动等非预期或不可控的现象。
为避免单点故障、提高网络的可靠性,一个iNOF域中也可以部署多个iNOF反射器。当一个反射器故障时,其它反射器能继续工作。这些路由反射器及其客户机之间形成一个集群,反射器上需要配置相同的集群ID,以便集群具有统一的标识,避免路由环路的产生。
图2-22 iNOF跨交换机组网示意图
iNOF具有以下优势:
· 即插即用
当主机接入iNOF网络时,iNOF交换机能够自动发现该设备,并将新主机加入消息同步给网络中的其他iNOF交换机以及通知同一iNOF域中的其它主机,以便其它主机能迅速发现新加入的主机,并自动和新主机建立连接,迅速实现存储业务的部署。
· 故障快速感知
当网络故障时,iNOF交换机能够快速检测到故障,并将故障状态信息同步给网络中的其它iNOF交换机以及通知同一iNOF域中的其它主机。如果该网络故障影响了存储设备,则主机会快速断开与该存储设备的连接,将业务切换到冗余路径。
H3C对成熟的BGP技术进行扩展,来实现iNOF跨交换机组网的技术具有以下特性:
· 基于BGP连接建立iNOF连接,传输层使用TCP协议,可以为iNOF信息的传输提供稳定的连接。
· 基于BGP提供的丰富的路由策略,能够对iNOF路由实现灵活的过滤和选择。
· iNOF复用BGP路由反射功能,在大规模的iNOF网络中可以有效减少iNOF连接的数量,简化网络拓扑,降低网络维护成本。同时,管理员在反射器上完成iNOF域和成员主机的配置后,iNOF可自动将这些配置同步给客户机,从而,可以简化iNOF的部署和配置。
· iNOF复用BGP的GR(Graceful Restart,平滑重启)和NSR(Nonstop Routing,不间断路由)功能,在iNOF交换机进行主备倒换或BGP协议重启时,保障iNOF信息的传递不中断。
· iNOF复用BGP连接,BGP支持和BFD联动,因此,iNOF也能够利用BFD快速检测到链路故障。
· 借助BGP会话的各种加密手段,例如MD5认证、GTSM(Generalized TTL Security Mechanism,通用TTL安全保护机制)、keychain认证,可以提高iNOF交换机间连接的安全性。
负载均衡技术提供高效便捷的流量分发服务,通过对访问流量进行分析、调度和优化,将访问流量自动分配给多个数据中心、多条链路或多台服务器,从而轻松应对大流量访问需求。
负载均衡技术分为服务器负载均衡、入链路负载均衡、出链路负载均衡、DNS透明代理、全局负载均衡等。本文主要介绍链路级的负载均衡技术,其他内容请参考相关手册。
传统的以太网链路聚合、等价路由采用逐流负载分担机制。在该机制下,设备会根据报文的五元组等特征,通过HASH算法为数据流选择一个下一跳。对于特征相同的流量,哈希算法会选择相同的等价等价路由下一跳或聚合成员链路。这种方法实现了不同数据流在不同链路上的负载分担,也避免了报文乱序。
这种方式选择的下一跳时固定的,不能根据实际的转发情况和链路负载情况变化,因此也被称为静态负载分担。它的缺点如下:
· 没有考虑负载分担链路中各成员链路的利用率,从而会出现成员链路之间的负载分担不均衡,尤其当大数据流出现时会加剧所选中成员链路的拥塞甚至引起丢包。
· 在多跳路径上容易出现HASH极化,导致报文在多次转发后负载不均匀。
图2-23 流量在等价路由的多条路径上实现负载分担
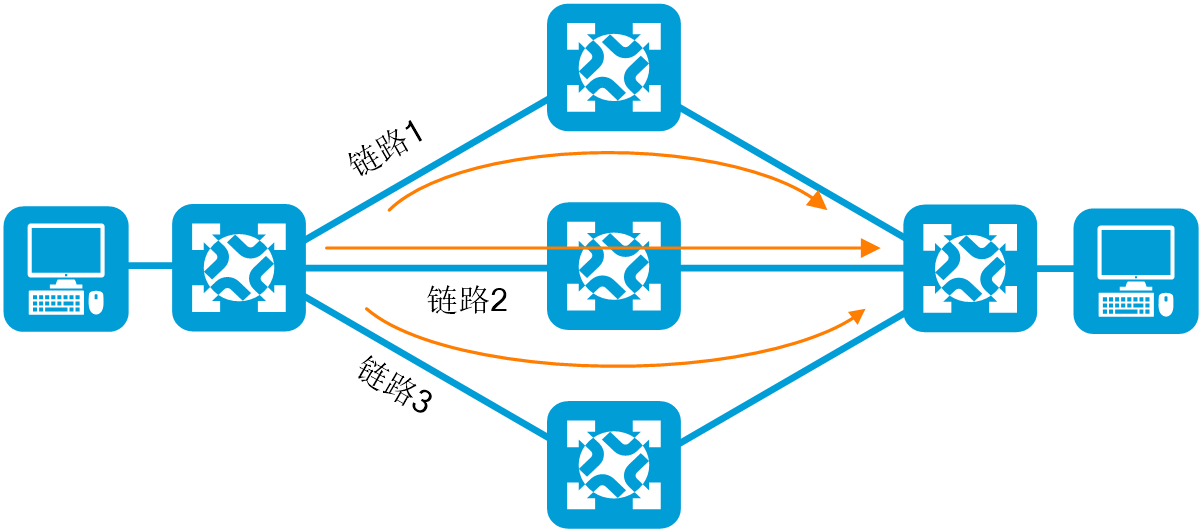
DLB(Dynamic load balance,动态负载均衡)的出现弥补了静态负载分担的缺陷。它在芯片引入了硬件流表(FlowSet),可以记录某条流的状态,结合等价路径的状态信息,可以实现根据实时拥塞状态的等价路径成员的动态选择,优先选择负载较轻的链路进行转发。
DLB通过引入时间戳、实时负载度量(端口带宽负载、队列大小)因子,在时间、带宽空间两个维度优化了负载均衡效果,提供了动态、智能的HASH机制。
等价路由和聚合组通过配置动态负载分担模式,实现DLB功能。配置动态负载分担模式后,设备可以根据链路的负载分担情况,优先选择负载最轻的路径进行转发。动态负载分担有三种模式(本功能的支持情况请以设备的实际情况为准):
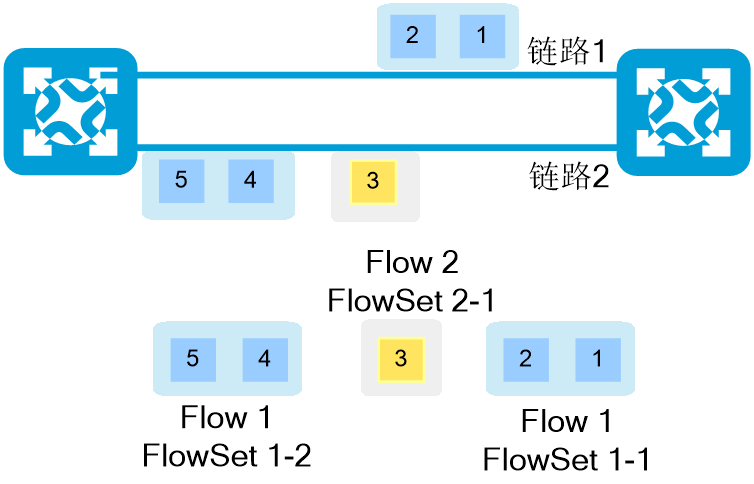
· Eligibility模式:Eligibility模式下,同一个数据流中时间间隔小于等于flowset-inactive-time的报文组成一个FlowSet。设备基于FlowSet选取当前负载较轻的成员链路进行转发,同一FlowSet中的数据包的转发链路相同。具体过程如下:
a. 具有一定特征的流量第一次进入设备转发,则被认为是新的流,设备为之创建Flowset;同时为之设置flowset-inactive-time老化计时器。
b. 设备在flowset-inactive-time周期内,计算出当前等价路由组中负载较轻的路径,转发该流量,在该周期内,具有相同特征的流量会使用相同的转发路径,并实时刷新flowset-inactive-time老化计时器,维持本Flowset为有效状态(会话保持)。
c. 超过flowset-inactive-time老化时间周期,如若未有流量维持该Flowset有效,则该Flowset记录被老化,即使后续再有该Flowset相同特征的流量到来,设备认为是一个新的流,创建新的Flowset,重新HASH到负载较轻的路径。
图2-24 Eligibility模式
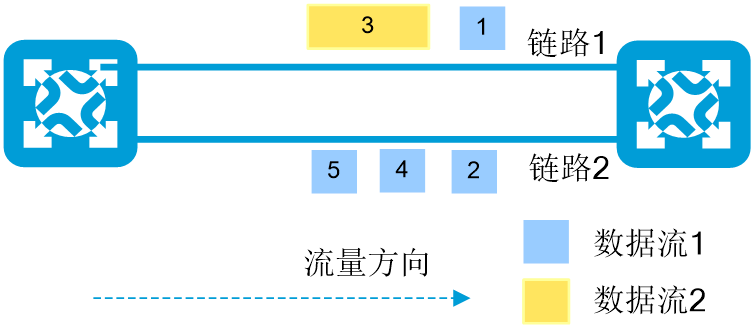
· Spray模式:Spray模式采用逐包负载分担机制,设备基于数据包选取当前等价路由组中负载最轻的路径进行转发。同一个数据流的多个数据包的转发链路可能不同,因此接收端可能会出现报文乱序的问题,在该模式下需确保接收端支持报文乱序重组的功能。
图2-25 Spray模式
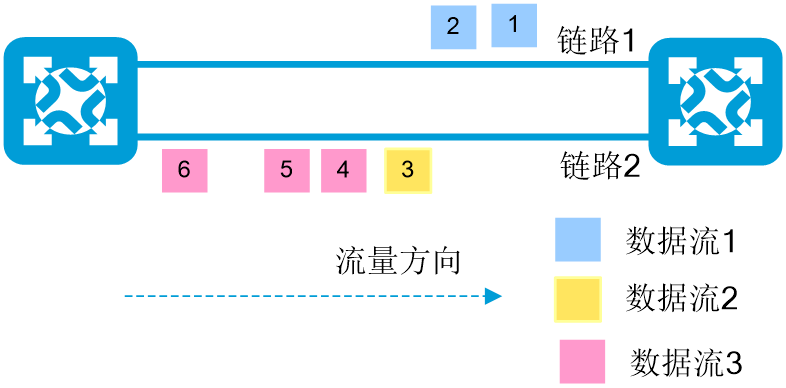
· 固定模式(Fixed模式):固定模式会为数据流的第一个数据包选择负载较轻的路径,同一个数据流的后续数据包使用第一个数据包的转发路径。
图2-26 固定模式(Fixed模式)
关于等价路由模式和聚合动态负载分担的详细介绍,请参见产品配套的“三层技术-IP路由”中的“IP路由基础”,以及“二层技术-以太网交换”中的“以太网链路聚合”配置和命令手册。
在上下行带宽1:1的AI智算网络中,常遇到多入口多出口的复杂场景。在此类场景中,我们希望能够在保持数据包顺序即逐流转发的前提,将来自多个入口相同目的地址的流量均匀地分发到多个出口。然而,在实际环境中,往往会出现多个入口的流量汇聚到某一个出口,而其他出口上没有流量的情况,导致负载分担不均衡和网络拥塞。
为了解决这一问题,H3C提出了LBN(Load Balance Network,负载均衡网络)技术,这是一种网络级别的负载均衡技术。通过对端口进行分组和智能编排,形成入口和出口之间的一对一映射关系,将流量精准地负载分担到不同的出口,以提升网络吞吐率。
关于LBN的详细介绍,请参见产品配套的“接口管理”中的“以太网接口”配置和命令手册。
目前LBN技术仅支持应用在等价路由场景和二层以太网链路聚合场景。
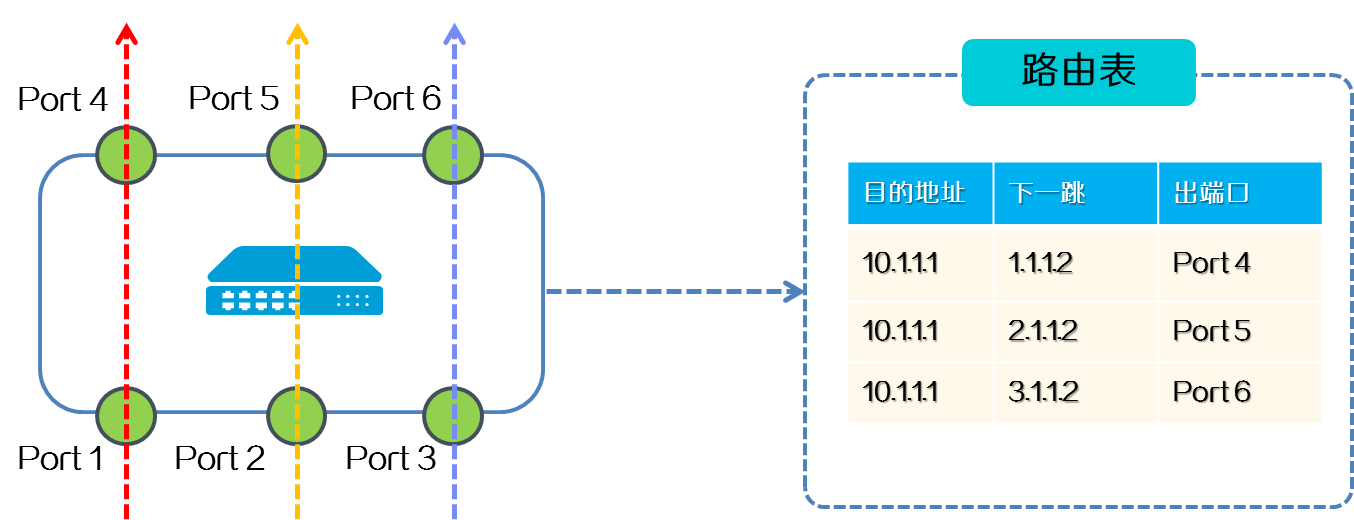
在等价路由场景,设备的路由表会出现相同目的地址不同下一跳的等价路由。具有相同目的地址的流量从设备不同的端口进入后,通过等价路由,会从不同的端口转发出去。通过LBN技术,入端口经过算法映射到唯一出端口,例如,来自Port 1的流量只能从Port 4出,来自Port 2的流量只能从Port 5出。
图2-27 LBN应用在等价路由场景
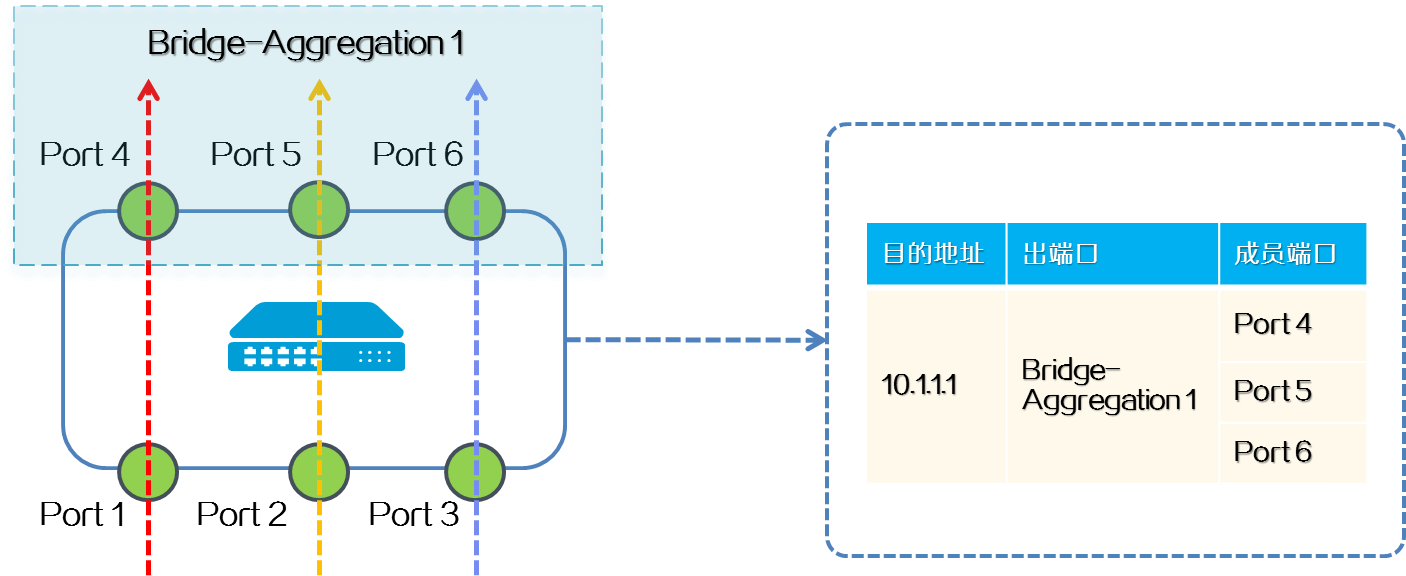
在二层以太网链路聚合场景,如下图所示,Port 4,Port 5,Port 6是二层聚合口Bridge-Aggregation 1的成员端口。具有相同目的地址的流量从设备不同的端口进入后,根据目的地址查找流量的出端口是一个二层聚合口,形成了多入口多出口的场景。通过LBN技术,入端口经过算法映射到唯一出端口,例如,来自Port 1的流量只能从Port 4出,来自Port 2的流量只能从Port 5出。
图2-28 LBN应用在二层以太网链路聚合场景
以等价路由场景为例,LBN的工作原理如下:
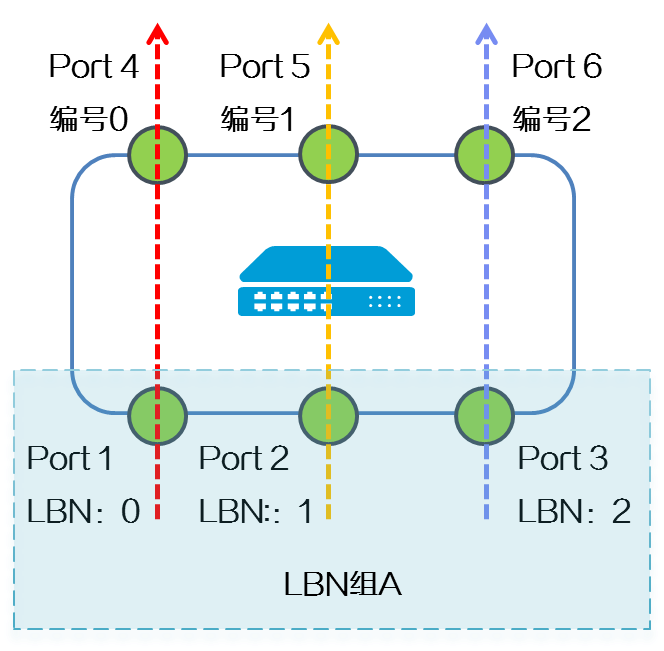
(1) 用户将入端口加入LBN组后,设备为LBN组中每个入端口设置LBN值,例如为Port 1 设置LBN值为0。
(2) 对出端口进行编号。根据路由表中每个等价路由组内的出端口顺序或二层聚合口成员端口的加入顺序,为出端口从0开始编号。例如,Port 4, Port 5,Port 6的编号依次为0,1,2。
图2-29 LBN为入端口和出端口进行编号
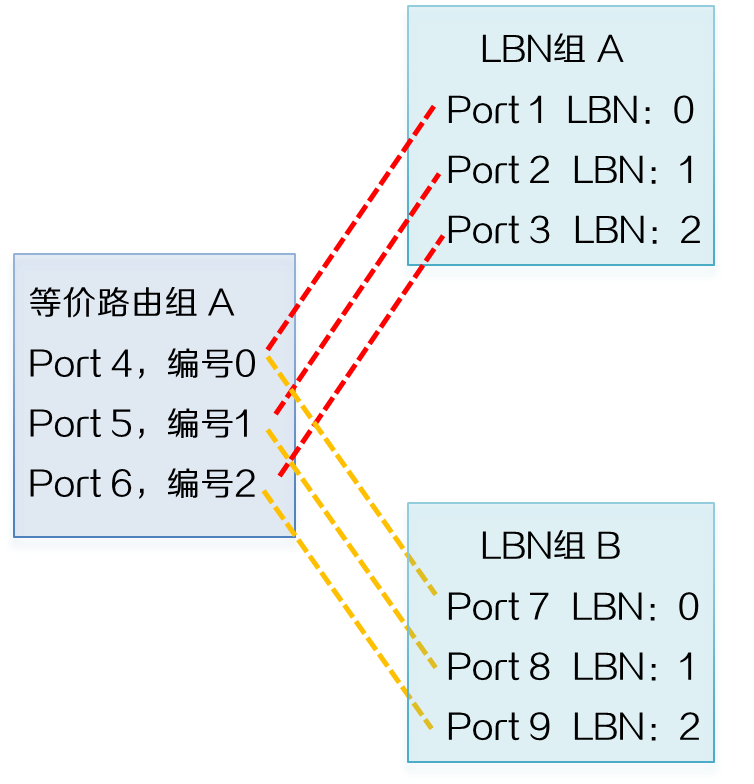
(3) 每个等价路由组与每个LBN组形成映射关系。将每个LBN组中入端口的LBN值依次对每个等价路由组内的出端口数量进行取余运算,形成每个入端口与出端口的映射关系。例如,Port 1的LBN值为0,等价路由组A中存在3个出端口。LBN值0对3取余为0,则Port 1对应的流量出端口是编号为0的Port 4。
图2-30 等价路由组与LBN组映射
在二层以太网链路聚合场景,则形成每个二层聚合口与每个LBN组的映射关系。计算方式与等价路由组类似。
在上下行带宽1:1的AI智算网络中,Leaf1设备有8个200G端口下连至服务器,编号为1~8;分别有4个400G端口上连至每个Spine设备,其中与Spine1连接的端口编号为9~12。
图2-31 LBN典型组网
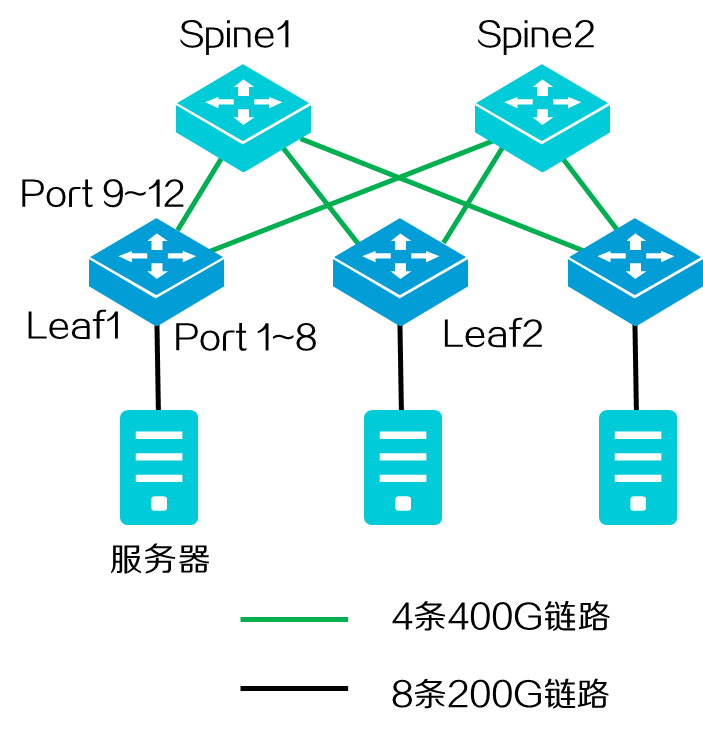
Leaf1设备通过LBN技术,形成出入端口的映射关系。当流量从入端口进入后,根据目的地址查找路由表和映射关系,唯一确定转发出口,实现流量精确负载分担转发。
· Port 1、2对应的流量出端口为Port 9;
· Port 3、4对应的流量出端口为Port 10;
· Port 5、6对应的流量出端口为Port 11;
· Port 7、8对应的流量出端口为Port 12。
在等价路由场景中,流量在等价路由的多个下一跳上进行负载分担。然而,随着数据中心网络的发展,流量的模型也在发生着变化,时常会出现大象流与老鼠流共存的现象,传统的静态等价路由负载分担已经不能满足需求。
图2-32 传统的等价路由负载分担方式已经不能满足需求
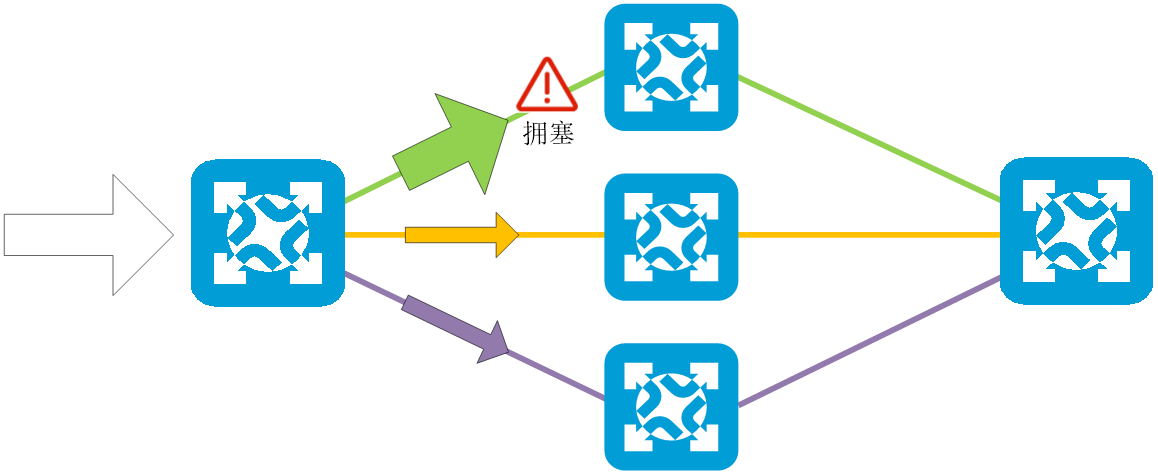
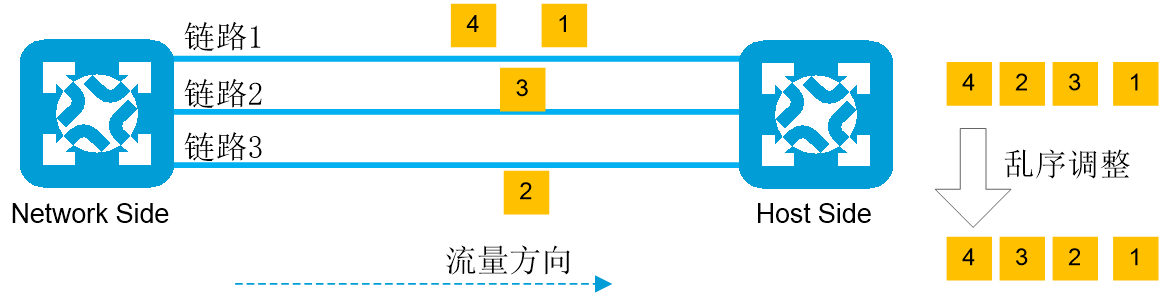
SprayLink是一种端网融合负载均衡方案,由网络侧进行等价路由负载分担,由主机侧对负载分担后的报文进行乱序调整。
SprayLink可以根据链路带宽、队列深度情况动态调整报文转发的链路,像均匀的喷雾一般将流量喷洒至各条链路,以解决传统等价路由负载分担不均,无法充分利用链路带宽的问题。
图2-33 SprayLink示意图
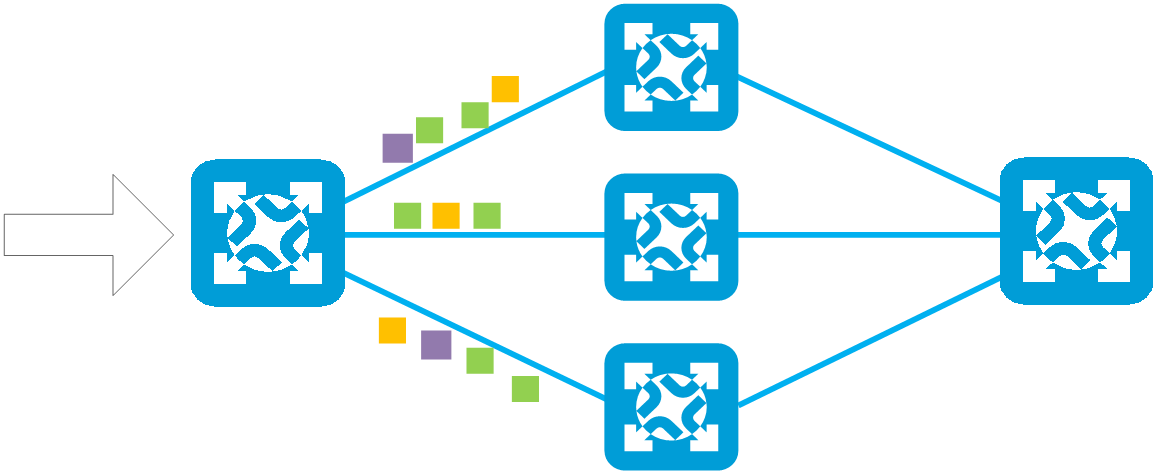
设备通过三个步骤完成SprayLink负载分担。
(1) 区分流量。
SprayLink是一种逐包的负载均衡方式,而在数据中心网络中,部分场景下,部分报文要求不能乱序,无法通过逐包方式进行负载均衡,此时需要网络侧首先对流量进行区分,再进行负载分担。以无法进行逐包负载的RoCE协议报文为例,说明SprayLink区分流量的步骤:
a. 对所有报文默认采用逐包负载分担。
b. 设备全局下发ACL,规则为匹配UDP目的端口号为4791,reserve字段为0的报文,此报文为RoCE协议报文(reserve 为RoCE协议报文特有),动作为进行逐流负载分担。未匹配上ACL规则的报文则进行逐包负载分担。
(2) Spray HASH。
Spray HASH的特点如下:
¡ 设备基于数据包,而不是基于数据流进行转发。基于数据包的负载分担将每个数据包都视为一个独立的流,负载会更为均衡。
¡ 设备会定期检测成员链路端口发送的报文字节数,并依此挑选当前负载最轻的路径进行转发,以达到动态负载分担的效果。
Spray HASH效果如下图所示,网络侧向主机侧发送报文,中间的链路2负载过高,故报文将通过其他两条链路进行负载分担,直到高负载链路的负载恢复。
图2-34 Spray HASH效果图
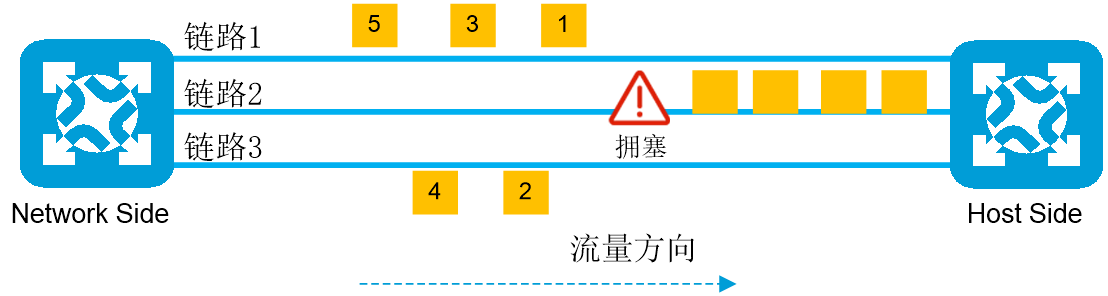
负载分担的过程为:
a. Network Side收到报文1,在无负载的链路1和链路3中随机选择链路1转发。
b. Network Side收到报文2,选择负载较轻的链路3转发。
c. Network Side收到报文3,因为链路1和链路3负载相同,再次随机选择链路1转发。
d. Network Side收到报文4,选择负载较轻的链路3转发。
e. Network Side收到报文5,选择负载较轻的链路1转发。
(3) 乱序调整。
因为Spray HASH采用逐包负载分担,同一个数据流的多个数据包的转发链路可能不同,因此主机侧接收端收到的报文可能是乱序的,接收端需要通过报文乱序重组功能整理报文的顺序。如下图所示:
图2-35 Spray HASH报文乱序调整
如今以太网越来越多的部署RoCE(RDMA over Converged Ethernet,以太网RDMA)网络,允许设备间不经CPU,直接互相访问网卡中的数据,以实现更低的延迟和更高的CPU效率。RoCE区分协议报文和数据报文,数据报文可以使用Spray HASH逐包负载分担,而协议报文因不能乱序,需使用传统的逐流负载分担方式,SprayLink可以区分这两种流量,适合部署于RoCE网络中。
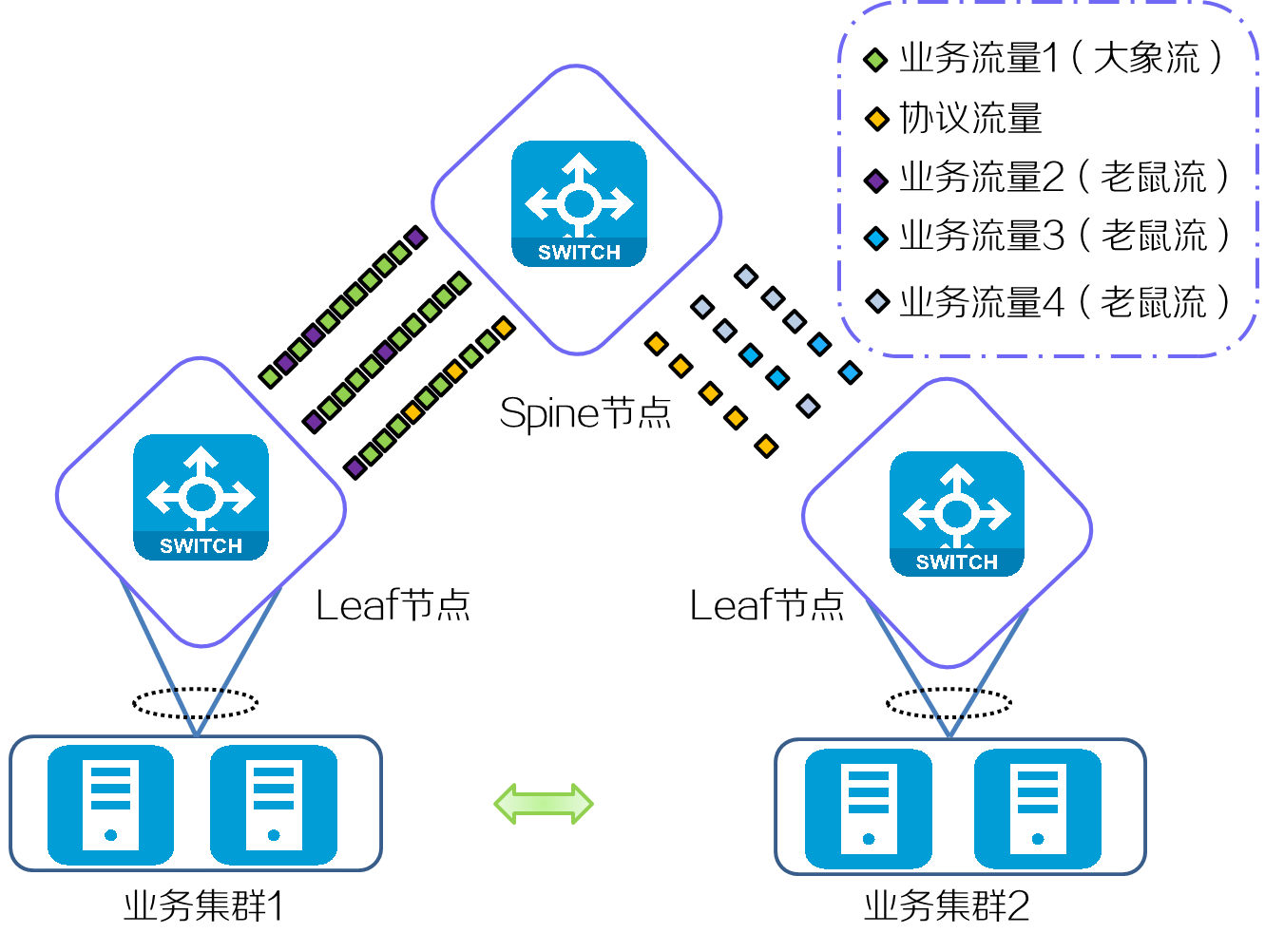
某个数据中心RoCE网络流量的模型如下:
· 存在一条RoCE业务流量大象流,用于AI训练,占据带宽的70%。
· 存在数条业务流量老鼠流,用于HTTPS业务请求和应答、应用程序间的API调用和少量数据的查询和增删改,共占据带宽的20%。
· 存在数条RoCE协议报文的老鼠流,用于建立及维护RoCE网络,占据带宽的10%。
使用传统负载分担时,会出现负载分担不均的情况,大象流会集中于量集中到某条路径转发,其他路径分配到很少的流量或者没有流量,影响链路利用率,并且负载大的链路可能会发生业务异常。
如下图所示,业务集群1进行AI训练业务,使用SprayLink的效果为:
图2-36 SprayLink部署样例
可通过如下模式配置SprayLink:
· 配置等价路由Spray模式:设备基于数据包选取当前等价路由组中负载最轻的路径进行转发,具体命令为:ecmp mode spray
关于上述命令的详细介绍,请参见产品配套的“三层技术-IP路由”中的“IP路由基础”配置和命令手册。
· 指定链路聚合的动态负载分担模式为Spray模式。该模式下,基于数据包选取当前负载分担链路中带宽利用率最小的成员链路进行转发。属于同一Flow的数据包可能选择不同的成员链路转发,接收流量的设备上可能出现报文乱序问题。因此,该模式下需要保证接收流量的设备上支持报文乱序重组功能。具体命令为:link-aggregation load-sharing mode dynamic spray
关于上述命令的详细介绍,请参见产品配套的“二层技术-以太网交换”中的“以太网链路聚合”配置和命令手册。
· 配置基于报文逐包进行负载分担,并指定spray算法。spray算法在逐包的同时,考虑不同报文的大小,让负载更均衡。具体命令为:ip load-sharing mode per-packet spray(三层接口视图)
关于上述命令的详细介绍,请参见产品配套的“三层技术-IP业务”中的“IP转发基础”配置和命令手册。
· 通过策略路由设置多个下一跳或缺省下一跳的负载分担方式为spray方式,在该方式下,设备基于数据包选取当前负载分担链路中负载较轻的成员链路进行转发。具体命令为:apply loadshare-mode { next-hop | default-next-hop } spray(策略节点视图/IPv6策略节点视图)
关于上述命令的详细介绍,请参见产品配套的“三层技术-IP路由”中的“策略路由”配置和命令手册。
GLB(Global Load Balancing,全局负载均衡)是在DLB特性基础上的一个功能扩展,主要是为了解决数据中心多跳网络中出现远端设备负载不均衡的问题。
由于DLB在进行负载分担时只会考虑本地下一跳链路的负载情况,不会考虑报文下一跳到目的设备之间的链路负载情况。如果下一跳设备在发送报文给下一个下一跳设备之间的链路发生拥塞,则可能会引起丢包。
如下图所示,在一个典型的Spine-Leaf数据中心组网中,由于ECMP的HASH极化问题或者是流量的分布问题,可能会出现负载分担不均衡导致的报文拥塞问题。
图2-37 Leaf1->Leaf4之间有2个负载分担链路
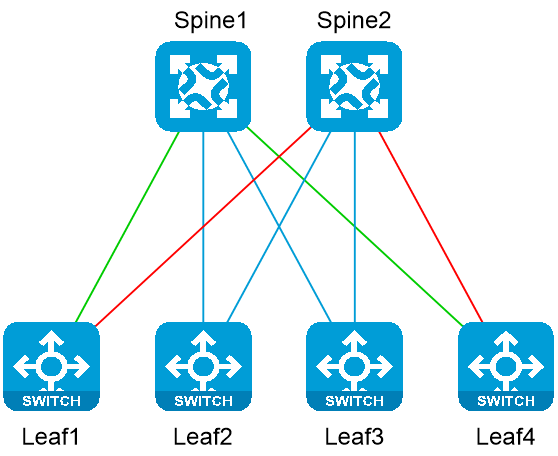
在上述网络中,流量的转发路径是Leaf1->Leaf4,Leaf1到Leaf4之间的链路形成等价路由。
· 在未配置GLB特性之前,如果Spine2到Leaf4之间的链路发生了拥塞,而Leaf1设备感知不到,它可能会把流量发给Spine2,再通过Spine2发送给Leaf4设备,从而加剧Spine2和Leaf4之间的链路拥塞。
· 配置了GLB之后,Spine设备会把链路质量周期性发送给Leaf设备,Leaf设备在进行选路时,会考虑报文从本设备到目的设备之间的所有链路质量,从而在源头上减少链路拥塞。在本例中,Leaf1设备会选择将报文发送给Spine1设备,Spine1再把报文发送给Leaf4,从而绕过拥塞链路。
GLB的工作机制如下:
(1) Spine和Leaf设备判断链路的质量,并记录在本地的链路状态表项里。
(2) Spine设备周期性地向Leaf设备通告链路的质量状态,Leaf设备接收所有Spine层的GLB消息,根据GLB消息刷新本地链路状态表项。经过上述过程,每台设备都知道了网络中所有链路质量信息。
(3) Leaf设备在发送报文给其他设备时,会计算本设备到目的设备之间的所有链路质量,并选择最优路径将报文转发出去。
通过上述过程,GLB实现的负载均衡的效果比DLB更好,可以做到亚毫秒级别流量调度粒度,对微突发造成的网络拥塞反应得更块。
目前RoCE网络主要应用于智算中心和高性能计算中心、金融存储网络环境中的参数网络和高性能存储网络。
在人工智能计算中心,RoCE网络分为参数网络和高性能存储网络两种类型:
· 参数网络:参数网络是业务区的RoCE网络,用于为GPU服务器、高性能计算服务器之间提供高带宽无丢包的互联能力。关于参数网络的更多详细介绍,请参见RoCE参数网络介绍。
· 高性能存储网络:高性能存储区的RoCE网络用于为GPU服务器、高性能计算服务器和高性能存储之间提供高带宽无丢包的互联能力。关于高性能存储网络的更多详细介绍,请参见RoCE高性能存储网络介绍。
人工智能作为全球科技领域的高地,近年来得到了飞速的发展。以ChatGPT为代表的人工智能技术不仅将对传统行业带来革命性的变革,也向数据中心等基础设施提出了更高的要求。
智算中心是人工智能领域的重要组成部分,肩负着助力人工智能产业的走向兴盛的使命,承担为人工智能企业提供高性能计算资源的重要职责。随着人工智能技术的快速发展,智算中心在智能制造、大数据分析、深度学习等领域中起着至关重要的作用。
智算中心的规模正在不断扩大,积极响应人工智能和大数据计算需求的爆发式增长。一方面,各大科技公司、高校和科研院所纷纷成立或扩建智算中心,形成了从区域级到国家级的多层次布局。另一方面,政府也在加大对智算中心建设的支持力度,加大计算集群的规模和数量。
布局和规划智算中心,可以为人工智能大模型、AI算法等技术的研究提供基础条件,进而提升各个行业的发展,促进数字经济的高质量发展。智算中心的创新发展,有望成为带动人工智能及相关产业快速发展的新引擎。
H3C智算中心全面支撑大模型的训练业务,提供从基础设施到模型训练的一站式开发平台;全面提升算力服务,提供算力、存力、运力协同感知的高性能计算集群;满足国家双碳战略,提供符合零碳绿色的算力中心。
· 全面提升算力性能,提供多种算力类型:同时提供NVIDIA GPU算力和国产化GPU算力,全面支持新华三的最新人工智能计算服务器,包含R5500G6、R5300G6和R4900G6。提供包含英伟达、昆仑芯等多种算力类型。并且傲飞算力调度平台可以同时兼容多种异构算力,灵活调度,让用户无感底层算力差异。全面助力算法工程师快速训练微调模型,同时满足不同用户的对不同算力类型的特色需求。
我司算力平台和大模型平台从底层服务器,到GPU驱动,K8S插件都完成了商用GPU算力和国产化算力的适配。根据客户选择的资源池不同,下发不同的依赖镜像,实现异构算力推理/训练的调度。
· 高性能算力配套硬件,极致释放澎湃算力:200G/400G RoCE网络,充分满足大模型训练微调的网络高带宽和低延时需求。并将新华三的高性能CX系列存储做成了云服务,在继承了云下高性能的读写带宽和IOPS要求的同时,提供了云服务模式下的多租户隔离能力,保证了最终用户的数据安全。
· 算网协同,充分释放GPU算力,提高运维效率:智能无损网络方案采取机内NVSwitch + 机间 RoCE组网方案实现大模型并行训练通信网络。自动将TP流量卸载在NVSwitch上,DP/PP流量卸载到RDMA网络,算网协同,最大程度提升GPU算力使用效率。同时人工智能计算节点上线自动感知,拓扑自动感知,支持大模型多机并行训练。同时AI参数网自动化部署能力,帮助客户减轻复杂的参数网运维,降低系统运维难度。
· 增强云服务能力,解决行业算力短缺难题:在支持云上、云下两种部署模式的基础上,增强了智算云服务的运营能力和多租户的支持能力,可以助力政府、算力运营商建设高效可靠的运营型人工智能算力中心,通过集约化建设解决区域内算力短缺的难题。
· 增强LLMOPS工程能力,提升大模型落地效率:在支持MLOPS及算力调度的基础之上,增加LLMOPS能力,帮助行业用户快速落地大模型。一方面基于百业灵犀系列大模型和新华三算力基础设施,可以为用户提供完整大模型开发部署解决方案。另一方面,智算解决方案基于新华三算力基础设施和算力平台,集成了LLama2、Chatglm2.0、百川等开源大模型,让用户可以基于开源路线实现大模型落地。同时配套提供训练推理的执行优化与过程优化及软硬件结合的训练推理优化服务,帮助用户在智算中心落地大模型。
如下几种情况,建议选择云上场景,基于云的资源管理能力,可提供基础算力资源和算力平台:
· 政府、运营商建设的对外运营公共算力中心。
· 大企业自建,对内运营,服务于不同业务部门的智算中心。
· GPU服务器数量在32台以上。
智算解决方案云上场景典型组网如下图所示:
图3-1 智算方案云上场景典型组网
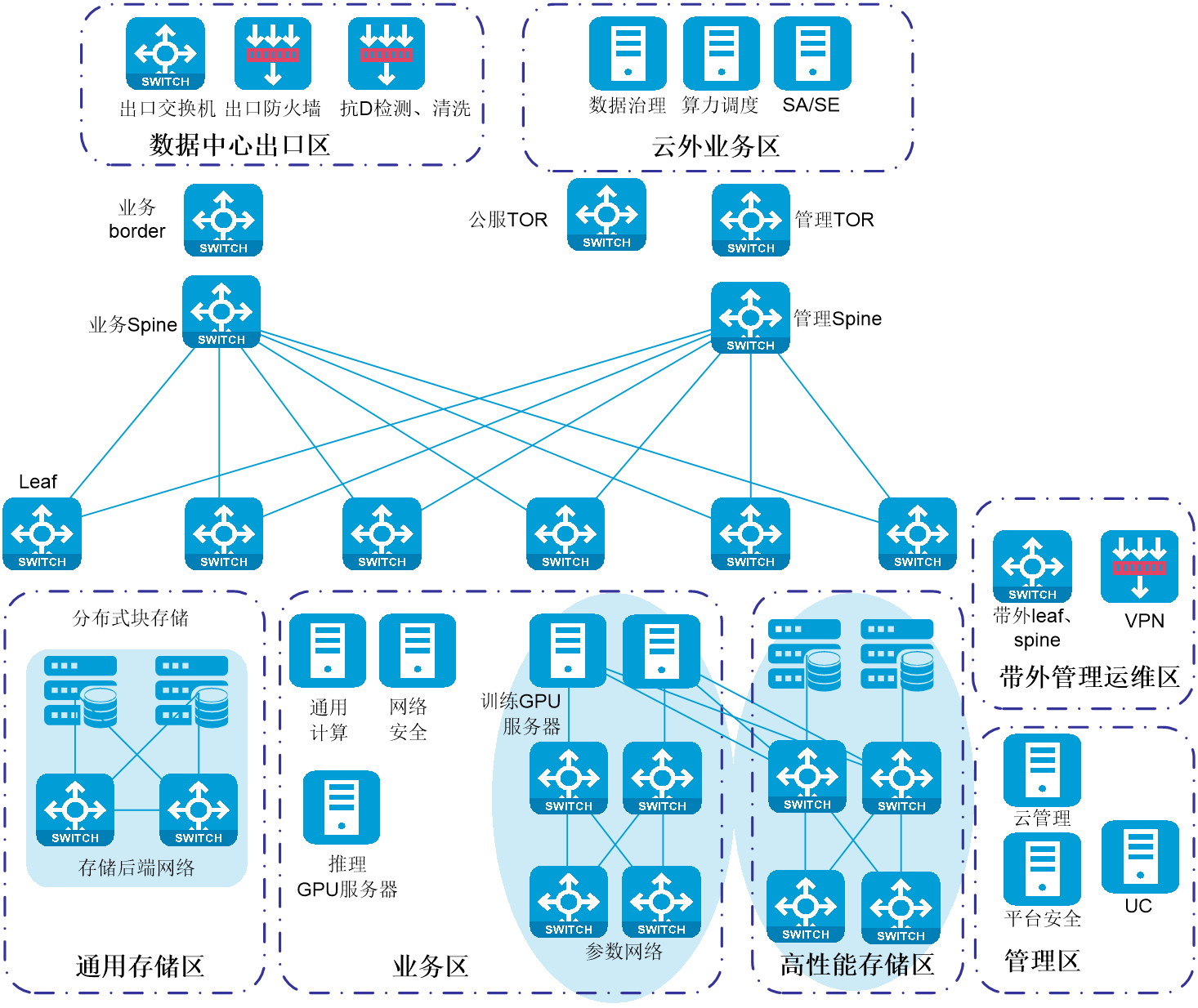
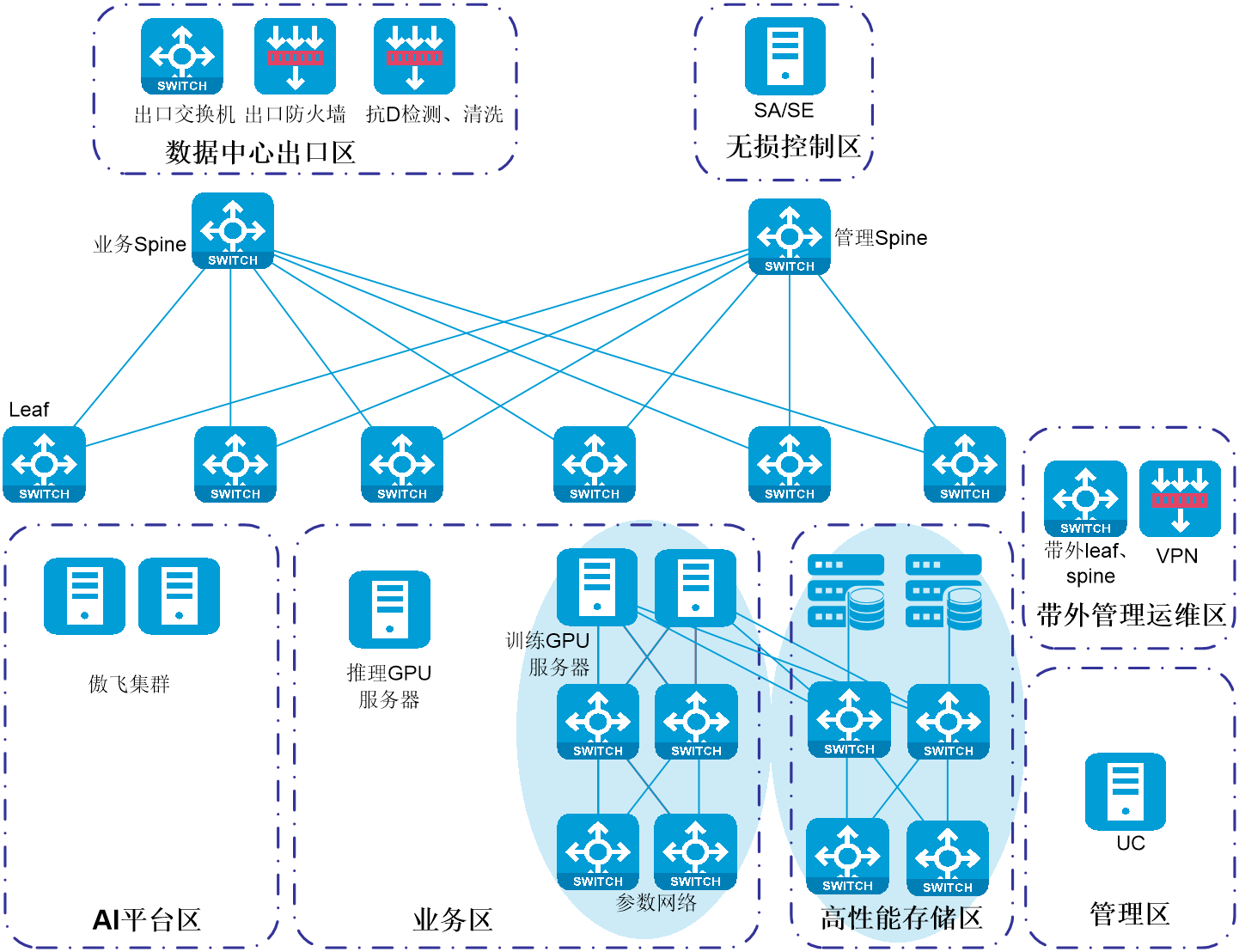
按资源分区,各部署区域及说明如下:
· 数据中心出口区:数据中心网络接入互联网,可旁挂出口防火墙等安全设备,提供平台级别的安全防护能力。是智算中心与外部网络之间的连接点,部署两台互联网接口交换机支持和运营商对接,同时配备抗D设备做安全防护;配备一对物理出口防火墙实现内外网络隔离、控制流量和访问策略等基础的安全防护;最后通过出口交换机,提供数据中心内部和其他网络平面的互联能力
· 云外业务区:又称公服区,一般部署不区分租户的业务,本次部署两类业务。傲飞平台,对外为用户提供AI开发的全流程服务,对内通过调用云的API接口创建用于人工智能训练的CCE容器集群以及向CCE容器集群下发训练任务;SA/SE,收集GPU服务器的网卡等运行信息,分析整体AI训练流量,用于AI业务调优。
· 管理区:部署云管理平台、平台级安全系统、UCenter统一运维平台,为用户提供统一的系统管理、安全防护和运维运营。
· 带外管理运维区:主要用于运维和管理接入。
· 通用存储区:部署OneStor块存储,主要为业务区的通用计算、网络安全和云平台提供块存储,一般采用三副本设计。
· 业务区:主要部署和最终用户相关的业务,主要部署四类业务资源。GPU训练计算资源,主要为人工智能算法开发和模型训练提供GPU能力,主要为H800 OAM服务器,如新华三的R5500G6服务器,训练资源会接入RoCE网络平面;GPU推理计算资源,主要为人工智能推理提供GPU能力,如对模型进行自动评估、部署为推理后进行人工测试等,获取在真实场景下的推理性能;网络安全资源,如提供HSLB,为容器集群提供外部的访问能力;通用资源,当用户申请了裸金属GPU服务器时,可以配套申请通用资源中的虚拟机,用户通过虚拟机做跳板,可以对所有裸金属服务器进行环境搭建和基础运维。
· 高性能存储区:部署用于人工智能训练的高性能分布式文件存储。CX系列存储,主要提供人工智能模型训练过程中的数据集读取,模型checkpoints的写入等;GUI节点,用于云平台的API接口调用;CES节点,用于外部的以太网络写入和导出数据。
按网络平面,智算解决方案云下场景可划分为如下平面:
· 数据中心接入平面:是智算中心与外部网络之间的连接点,部署两台互联网接口交换机以支持和运营商对接,同时配备抗D设备做安全防护;配备一对物理出口防火墙实现内外网络隔离、控制流量和访问策略等基础的安全防护;最后通过出口交换机,提供数据中心内部和其他网络平面的互联能力
· 云外业务平面:一般部署不区分租户的业务,此次部署一组公服TOR交换机,提供公共服务的连接能力
· 云内业务平面:被云控制器管理,通过VxLAN技术形成OverLay的大二层隔离网络,实现各租户的隔离功能,云内业务平面通过spine-leaf架构连接业务区的各资源
· RoCE网络平面:高速互联网络,提供高带宽无丢包的网络平面。为GPU服务器之间以及GPU服务器和高性能存储之间提供互联的能力
· 通用存储平面:网络安全、云平台一般基于虚拟化进行部署,所依赖的块资源,通用网络平面连通网络安全池和云平台集群,为其提供公共的块存储资源
· 带内管理平面:为云平台管理其他的服务器、存储提供独立的互联网络,网络为独立的Underlay网络,为spine-leaf架构
· 带外管理平面:统一运维平台通过独立的带外网管理各ICT基础设施,一般也是spine-leaf架构,提供独立的underlay网络。同时提供VPN接入能力,方便运维人员安全的接入此网络进行基础的运维。
如下几种情况,建议选择云下场景,基于算力平台调度算力,快速开发AI算法和训练模型:
· 中小企业自建自用、AI开发业务相对单一的智算中心。
· 32台以下GPU服务器。
智算解决方案云下场景典型组网如下图所示:
图3-2 智算方案云下场景典型组网
按资源分区,各部署区域及说明如下:
· AI平台区:部署傲飞平台,对外为用户提供AI开发的全流程服务,对内通过调用云的API接口创建用于人工智能训练的CCE容器集群以及向CCE容器集群下发训练任务。
· 无损控制区:部署SA/SE,收集GPU服务器的网卡等运行信息,分析整体AI训练流量,用于AI业务调优。
· 业务区:主要部署和最终用户相关的业务,在智算场景下主要包括GPU训练计算资源和GPU推理计算资源。GPU训练计算资源主要为人工智能算法开发和模型训练提供GPU能力,主要采用H800 OAM服务器,如新华三的R5500G6服务器,训练资源会接入RoCE网络平面;GPU推理计算资源,主要为人工智能推理提供GPU能力,如对模型进行自动评估、部署为推理后进行人工测试等,获取在真实场景下的推理性能。
· 高性能存储区:部署用于人工智能训练的高性能分布式文件存储。CX系列存储,主要提供人工智能模型训练过程中的数据集读取,模型checkpoints的写入等;GUI节点,用于云平台的API接口调用;CES节点,用于外部的以太网络写入和导出数据。
· 管理区:部署云管理平台、平台级安全系统、UCenter统一运维平台,为用户提供统一的系统管理、安全防护和运维运营。
按网络平面,智算解决方案云下场景可划分为如下平面:
· 数据中心接入平面:是智算中心与外部网络之间的连接点,部署两台互联网接口交换机支持和运营商对接,同时配备抗D设备做安全防护;配备一对物理出口防火墙实现内外网络隔离、控制流量和访问策略等基础的安全防护;最后通过出口交换机,提供数据中心内部和其他网络平面的互联能力。
· 业务平面:傲飞和业务节点的K8S集群通信业务,业务平面通过spine-leaf架构连接业务区的各资源。
· RoCE网络平面:高速互联网络,提供高带宽无丢包的网络平面。为GPU服务器之间以及GPU服务器和高性能存储之间提供互联的能力。
· 带内管理平面:为云平台管理其他的服务器、存储提供独立的互联网络,网络为独立的Underlay网络,为spine-leaf架构。
· 带外管理平面:统一运维平台通过独立的带外网管理各ICT基础设施,一般也是spine-leaf架构,提供独立的underlay网络。同时提供VPN接入能力,方便运维人员安全的接入此网络进行基础的运维。
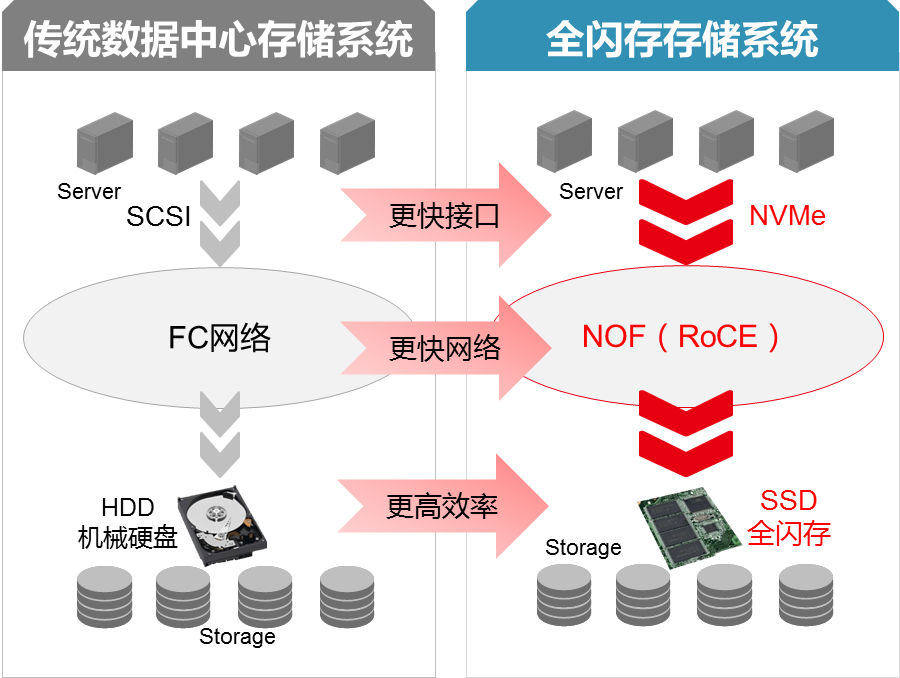
随着高性能计算、大数据分析、人工智能以及物联网等技术的飞速发展,集中式存储、分布式存储以及云数据库的普及等原因,业务应用有越来越多的数据需要从网络中获取,这对数据中心网络的交换速度和性能要求越来越高。
全闪存时代背景下,NVMe(Non-Volatile Memory express,非易失性内存主机控制器接口规范)存储协议的出现极大提升了存储系统内部的存储吞吐性能、降低了传输时延。NVMe-oF(NVMe over Fabrics)存储网络旨在使用NVMe通过网络结构将主机连接到存储。使用基于消息的模型通过网络在主机和目标存储设备之间发送请求和响应,NVMe-oF的普及使大数据服务的存算分离结构能够成为主流。在多种Fabric技术中,NVMe over RoCE比FC性能更高(更高的带宽、更低的时延),同时兼具TCP的优势(全以太化、全IP化),因此NVMe over RoCE是NoF最优的承载网络方案,也已成为业界NoF的主流技术被广大存储厂商所接受,成为业界NoF的主流。
图3-3 存储无损以太网
iNoF存储网络技术可实现客户业务在无损RoCE网络下iNOF域内的所有设备可以第一时间自动感知网络服务器和磁盘设备的加入和离开,实现“即插即用”,以及故障场景下业务快速感知和切换。
图3-4 iNoF存储网络核心优势
无损存储网络典型组网如下图所示:
图3-5 无损存储网络示意图
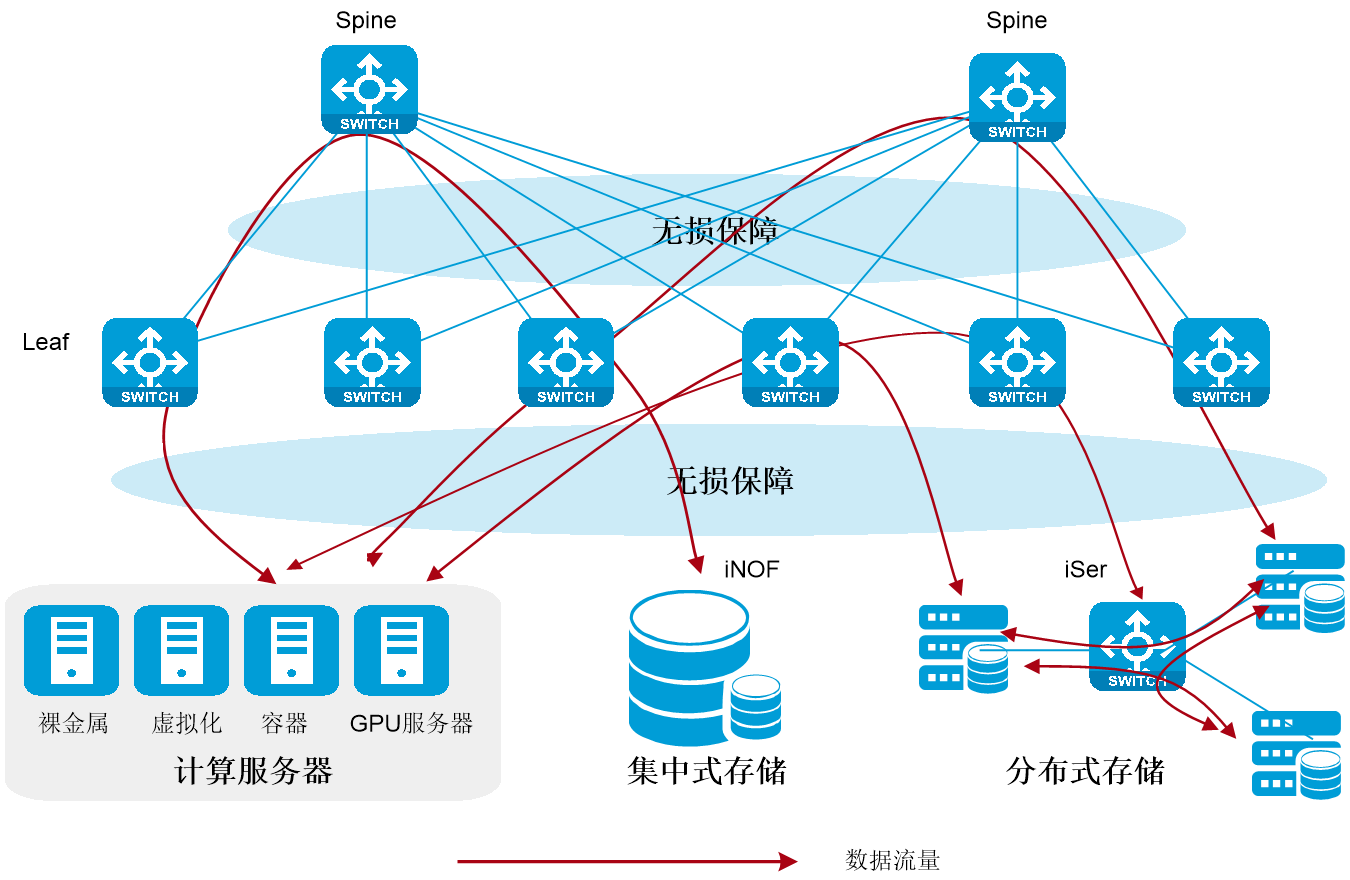
在无损存储网络中,集中式存储场景通过iNOF支持RoCE,分布式存储场景通过iSER支持RoCE。
参数网络是智能计算中心业务区的RoCE网络,用于为GPU服务器之间提供高带宽无丢包的互联能力。参数网络是分布式训练专用网络,在网络层设备上不需要和其它网络相连。参数网络推荐采用无阻塞的200G/400G网络,各服务器网口利用参数网络进行高速无损的数据交换,以实现AI训练性能的最大化。
根据组网规模和设备形态,目前支持如下组网类型:
· 小规模组网(单框/单盒):在小规模场景(端口数量不超过512,服务器数量不超过64)下,可以根据实际情况使用单框/单盒组网,该方案部署简单、有更高的可靠性(双主控)、更先进的负载均衡技术(cell级均衡,无HASH极化等问题)、更优的拥塞控制(credit调度机制,确定性的拥塞控制),但是该方案规模有限、易扩展性差,建议谨慎选择此方式。
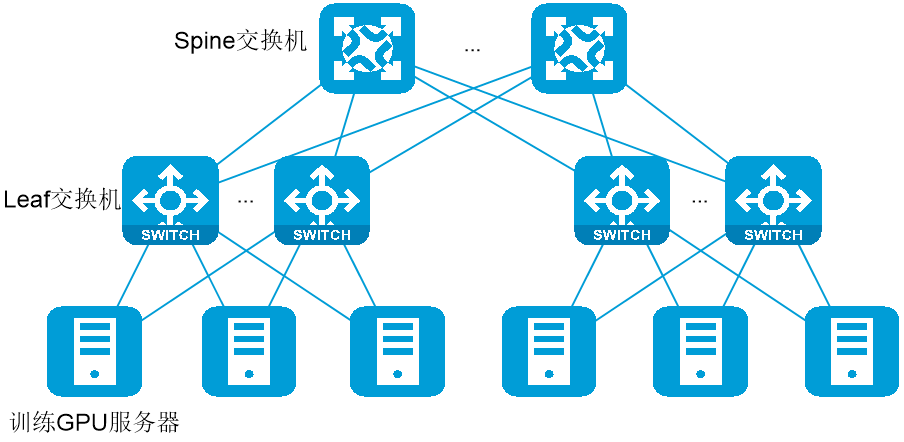
· 中大规模组网二级盒盒组网(Leaf-Spine架构):在网络规模较大时推荐使用Leaf-Spine架构的二级盒盒组网,该方案易扩展、支持较大规模组网,并且转发时延较低,推荐使用此方案。
· 中大规模组网二级框盒组网(Leaf-Spine架构):在超大规模网络环境中(端口数量超过2048,服务器数量超过256),可以使用Leaf-Spine架构的二级框盒组网,但是该方案部署较为复杂,框式交换机内部转发时延较高,建议谨慎选择此方案。
对于小规模组网,建议使用单盒或单框方案,GPU服务器的所有参数网网卡均与交换机互联,并针对不同服务器同序号的网卡配置到相同VLAN中。对于一级单框组网,建议同轨网卡接到相同的线卡上,同轨间通信集中在线卡内部,减少通信跳数及通信时延。
图4-1 单框/单盒组网示例
对于中大规模组网,建议使用Leaf-Spine网络架构,具体如下:
· 服务器多轨接入:GPU服务器按交换机可连服务器数量分组,同组内的GPU服务器上相同序号的参数网网卡连接到同一台Leaf交换机上。少数需要跨轨通信的场景,通过交换机互通。例如,Leaf交换机可以连接32台GPU,则可以将32台服务器分为一组,每个服务器上安装8个参数网网卡,每个服务器上的第n台参数网网卡连接到第n台交换机上。
图4-2 多轨接入
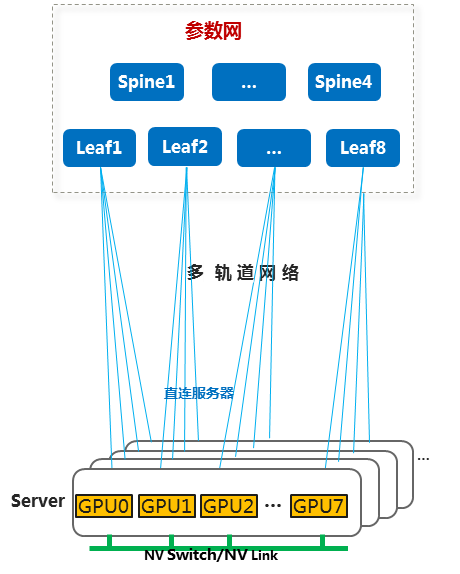
· 每8台Leaf交换机为一组,Leaf交换机和Spine交换机之间全互连。
· 为了构建无阻塞、收敛比1:1的RDMA网络,Leaf交换机上行和下行接口带宽应该相同。
图4-3 中大规模组网示例
如图4-4所示:
· GPU计算场景RDMA网络采用Spine、Leaf两级架构,Spine设备为S9825-64D,Leaf设备为S9825-64D。
· Leaf设备作为服务器的网关,Spine、Leaf之间为三层ECMP网络,在进行数据高速转发的同时支持转发路径的冗余备份。
· 服务器接口单归接入,不需要Leaf堆叠或者M-LAG。
现要求实现RDMA应用报文使用队列5进行无损传输。
![]()
本文以2台Spine设备、8台Leaf设备示例。实际应用中Spine层部署4台S9825-64D设备、Leaf层部署8台S9825-64D设备(上行口/下行口各使用32*400G)可以实现收敛比1:1的RDMA网络。
图4-4 数据中心GPU计算场景RDMA组网图
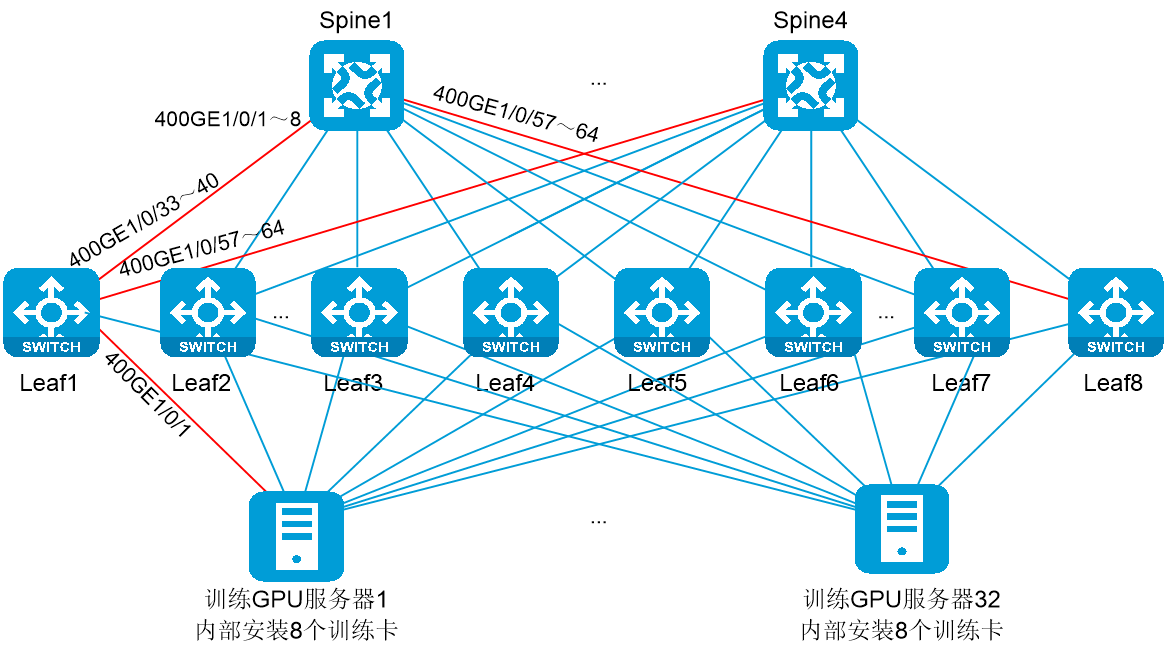
表4-1 接口IP地址规划
|
设备 |
接口 |
IP地址 |
设备 |
接口 |
IP地址 |
|
Leaf1 |
400GE1/0/1~32 |
Vlan 2 |
Spine1 |
400GE1/0/1 |
9.179.56.0/31 |
|
400GE1/0/33 |
9.179.56.1/31 |
… |
… |
||
|
… |
… |
400GE1/0/8 |
9.179.56.14/31 |
||
|
400GE1/0/40 |
9.179.56.15/31 |
400GE1/0/57 |
9.179.56.112/31 |
||
|
400GE1/0/57 |
9.179.57.129/31 |
… |
… |
||
|
… |
… |
400GE1/0/64 |
9.179.56.126/31 |
||
|
400GE1/0/64 |
9.179.57.143/31 |
|
|
||
|
Vlan-int2 |
9.179.64.1/26 |
|
|
||
|
Leaf 8 |
400GE1/0/1~32 |
Vlan 2 |
Spine 4 |
400GE1/0/1 |
9.179.57.128/31 |
|
400GE1/0/33 |
9.179.56.113/31 |
… |
… |
||
|
… |
… |
400GE1/0/8 |
9.179.57.142/31 |
||
|
400GE1/0/40 |
9.179.56.127/31 |
400GE1/0/57 |
9.179.57.240/31 |
||
|
400GE1/0/57 |
9.179.57.241/31 |
… |
… |
||
|
… |
… |
400GE1/0/64 |
9.179.57.254/31 |
||
|
400GE1/0/64 |
9.179.57.255/31 |
|
|
||
|
Vlan-int2 |
9.179.65.193/26 |
|
|
![]()
Spine4端口编号规则与Spine1一样;Leaf8端口编号规则与Leaf1一样。为图形简洁起见,图中不再一一标注。
配置BGP路由协议。配置Spine、Leaf设备的AS号都为805。Spine作为路由反射器,与各Leaf建立IBGP邻居。
为实现RDMA应用报文的无损传输,我们需要部署PFC功能和ECN功能:
· PFC功能基于优先级队列对报文进行流量控制。RDMA报文携带802.1P优先级5,我们对802.1P优先级为5的报文开启PFC功能。
RDMA报文转发路径的所有端口都需要配置PFC功能,因此我们在Spine设备与Leaf设备互连的端口、Leaf设备连接服务器的端口均开启PFC功能。
· ECN功能提供端到端的拥塞控制。设备检测到拥塞后,对报文的ECN域进行标记。接收端收到ECN标记的报文后,向发送端发送拥塞通知报文,使发送端降低流量发送速率。本例中,我们在Spine设备与Leaf设备互连的端口、Leaf设备连接服务器的端口均开启ECN功能。
ECN功能配置的high-limit值(queue queue-id [ drop-level drop-level ] low-limit low-limit high-limit high-limit [ discard-probability discard-prob ])需要小于PFC反压帧触发门限值,以使ECN功能先生效。
配置PFC功能时,必须配置接口信任报文自带的802.1p优先级或DSCP优先级(qos trust { dot1p | dscp }),并且转发路径上所有端口的802.1p优先级与本地优先级映射关系以及DSCP优先级与802.1p优先级映射关系必须一致,否则PFC功能将无法正常工作。对于本组网中的二层或三层接口,建议配置接口信任报文自带的DSCP优先级(qos trust dscp)。
对于接收到的以太网报文,设备将根据优先级信任模式和报文的802.1Q标签状态,设备将采用不同的方式为其标记调度优先级。当设备连接不同网络时,所有进入设备的报文,其外部优先级字段(包括DSCP和IP)都被映射为802.1p优先级,再根据802.1p优先级映射为内部优先级;设备根据内部优先级进行队列调度的QoS处理。
关于优先级映射的详细介绍,请参见产品配套的“ACL和QoS配置指导”中的“优先级映射”。
(1) 配置Leaf1。
# 配置FourHundredGigE1/0/33~FourHundredGigE1/0/64工作在三层模式,并配置各接口的IP地址。
<Leaf1> system-view
[Leaf1] interface range FourHundredGigE1/0/33 to FourHundredGigE1/0/64
[Leaf1-if-range] link-mode route
[Leaf1-if-range] quit
[Leaf1] interface Fourhundredgige 1/0/33
[Leaf1-FourHundredGigE1/0/33] ip address 9.179.56.1 31
[Leaf1-FourHundredGigE1/0/33] quit
[Leaf1] interface Fourhundredgige 1/0/34
[Leaf1-FourHundredGigE1/0/34] ip address 9.179.56.3 31
[Leaf1-FourHundredGigE1/0/34] quit
[Leaf1] interface Fourhundredgige 1/0/35
[Leaf1-FourHundredGigE1/0/35] ip address 9.179.56.5 31
[Leaf1-FourHundredGigE1/0/35] quit
[Leaf1] interface Fourhundredgige 1/0/36
[Leaf1-FourHundredGigE1/0/36] ip address 9.179.56.7 31
[Leaf1-FourHundredGigE1/0/36] quit
[Leaf1] interface Fourhundredgige 1/0/37
[Leaf1-FourHundredGigE1/0/37] ip address 9.179.56.9 31
[Leaf1-FourHundredGigE1/0/37] quit
[Leaf1] interface Fourhundredgige 1/0/38
[Leaf1-FourHundredGigE1/0/38] ip address 9.179.56.11 31
[Leaf1-FourHundredGigE1/0/38] quit
[Leaf1] interface Fourhundredgige 1/0/39
[Leaf1-FourHundredGigE1/0/39] ip address 9.179.56.13 31
[Leaf1-FourHundredGigE1/0/39] quit
[Leaf1] interface Fourhundredgige 1/0/40
[Leaf1-FourHundredGigE1/0/40] ip address 9.179.56.15 31
[Leaf1-FourHundredGigE1/0/40] quit
[Leaf1] interface Fourhundredgige 1/0/57
[Leaf1-FourHundredGigE1/0/57] ip address 9.179.57.129 31
[Leaf1-FourHundredGigE1/0/57] quit
[Leaf1] interface Fourhundredgige 1/0/58
[Leaf1-FourHundredGigE1/0/58] ip address 9.179.57.131 31
[Leaf1-FourHundredGigE1/0/58] quit
[Leaf1] interface Fourhundredgige 1/0/59
[Leaf1-FourHundredGigE1/0/59] ip address 9.179.57.133 31
[Leaf1-FourHundredGigE1/0/59] quit
[Leaf1] interface Fourhundredgige 1/0/60
[Leaf1-FourHundredGigE1/0/60] ip address 9.179.57.135 31
[Leaf1-FourHundredGigE1/0/60] quit
[Leaf1] interface Fourhundredgige 1/0/61
[Leaf1-FourHundredGigE1/0/61] ip address 9.179.57.137 31
[Leaf1-FourHundredGigE1/0/61] quit
[Leaf1] interface Fourhundredgige 1/0/62
[Leaf1-FourHundredGigE1/0/62] ip address 9.179.57.139 31
[Leaf1-FourHundredGigE1/0/62] quit
[Leaf1] interface Fourhundredgige 1/0/63
[Leaf1-FourHundredGigE1/0/63] ip address 9.179.57.141 31
[Leaf1-FourHundredGigE1/0/63] quit
[Leaf1] interface Fourhundredgige 1/0/64
[Leaf1-FourHundredGigE1/0/64] ip address 9.179.57.143 31
[Leaf1-FourHundredGigE1/0/64] quit
# 创建VLAN 2,并配置VLAN 2接口的IP地址。
[Leaf1] vlan 2
[Leaf1] interface vlan-interface 2
[Leaf1-Vlan-interface2] ip address 9.179.64.1 26
(2) 配置其他Leaf设备。
配置设备各接口工作在三层模式,并参考图4-4配置各接口的IP地址,具体步骤略。
(3) 配置Spine1。
# 配置FourHundredGigE1/0/1~FourHundredGigE1/0/64工作在三层模式,并配置各接口的IP地址。
<Spine1> system-view
[Spine1] interface range FourHundredGigE1/0/1 to FourHundredGigE1/0/64
[Spine1-if-range] link-mode route
[Spine1-if-range] quit
[Spine1] interface Fourhundredgige 1/0/1
[Spine1-FourHundredGigE1/0/1] ip address 9.179.56.0 31
[Spine1-FourHundredGigE1/0/1] quit
[Spine1] interface Fourhundredgige 1/0/2
[Spine1-FourHundredGigE1/0/2] ip address 9.179.56.2 31
[Spine1-FourHundredGigE1/0/2] quit
[Spine1] interface Fourhundredgige 1/0/3
[Spine1-FourHundredGigE1/0/3] ip address 9.179.56.4 31
[Spine1-FourHundredGigE1/0/3] quit
[Spine1] interface Fourhundredgige 1/0/4
[Spine1-FourHundredGigE1/0/4] ip address 9.179.56.6 31
[Spine1-FourHundredGigE1/0/4] quit
[Spine1] interface Fourhundredgige 1/0/5
[Spine1-FourHundredGigE1/0/5] ip address 9.179.56.8 31
[Spine1-FourHundredGigE1/0/5] quit
[Spine1] interface Fourhundredgige 1/0/6
[Spine1-FourHundredGigE1/0/6] ip address 9.179.56.10 31
[Spine1-FourHundredGigE1/0/6] quit
[Spine1] interface Fourhundredgige 1/0/7
[Spine1-FourHundredGigE1/0/7] ip address 9.179.56.12 31
[Spine1-FourHundredGigE1/0/7] quit
[Spine1] interface Fourhundredgige 1/0/8
[Spine1-FourHundredGigE1/0/8] ip address 9.179.56.14 31
[Spine1-FourHundredGigE1/0/8] quit
[Spine1] interface Fourhundredgige 1/0/57
[Spine1-FourHundredGigE1/0/57] ip address 9.179.56.112 31
[Spine1-FourHundredGigE1/0/57] quit
[Spine1] interface Fourhundredgige 1/0/58
[Spine1-FourHundredGigE1/0/58] ip address 9.179.56.114 31
[Spine1-FourHundredGigE1/0/58] quit
[Spine1] interface Fourhundredgige 1/0/59
[Spine1-FourHundredGigE1/0/59] ip address 9.179.56.116 31
[Spine1-FourHundredGigE1/0/59] quit
[Spine1] interface Fourhundredgige 1/0/60
[Spine1-FourHundredGigE1/0/60] ip address 9.179.56.118 31
[Spine1-FourHundredGigE1/0/60] quit
[Spine1] interface Fourhundredgige 1/0/61
[Spine1-FourHundredGigE1/0/61] ip address 9.179.56.120 31
[Spine1-FourHundredGigE1/0/61] quit
[Spine1] interface Fourhundredgige 1/0/62
[Spine1-FourHundredGigE1/0/62] ip address 9.179.56.122 31
[Spine1-FourHundredGigE1/0/62] quit
[Spine1] interface Fourhundredgige 1/0/63
[Spine1-FourHundredGigE1/0/63] ip address 9.179.56.124 31
[Spine1-FourHundredGigE1/0/63] quit
[Spine1] interface Fourhundredgige 1/0/64
[Spine1-FourHundredGigE1/0/64] ip address 9.179.56.126 31
[Spine1-FourHundredGigE1/0/64] quit
(4) 配置其他Spine设备。
配置与Spine1类似,请参考图4-4所示的接口和IP地址进行配置,具体步骤略。
(1) 配置Leaf1
# 配置连接服务器的链路类型为Trunk,允许VLAN 2通过。
[Leaf1] interface range FourHundredGigE1/0/1 to FourHundredGigE1/0/32
[Leaf1-if-range] port link-type trunk
[Leaf1-if-range] undo port trunk permit vlan 1
[Leaf1-if-range] port trunk permit vlan 2
[Leaf1-if-range] port trunk pvid vlan 2
[Leaf1-if-range] quit
(2) 配置其他Leaf设备。
配置与Leaf1类似,具体步骤略。
(1) 配置Leaf1。
# 配置OSPF,与Spine互连接口使能OSPF。
<Leaf1> system-view
[Leaf1] interface loopback 0
[Leaf1-LoopBack0] ip address 1.1.1.1 255.255.255.255
[Leaf1-LoopBack0] quit
[Leaf1] ospf 1 router-id 1.1.1.1
[Leaf1-ospf-1] area 0.0.0.0
[Leaf1-ospf-1-area-0.0.0.0] network 1.1.1.1 0.0.0.0
[Leaf1-ospf-1-area-0.0.0.0] network 9.179.56.0 0.0.0.255
[Leaf1-ospf-1-area-0.0.0.0] network 9.179.57.0 0.0.0.255
[Leaf1-ospf-1-area-0.0.0.0] quit
[Leaf1-ospf-1] quit
# 启动BGP实例default,指定该BGP实例的本地AS号为805,并进入BGP实例视图。
[Leaf1] bgp 805
# 配置全局Router ID为1.1.1.1。
[Leaf1-bgp-default] router-id 1.1.1.1
# 创建IBGP对等体组Spine。
[Leaf1-bgp-default] group Spine internal
# 指定对等体组Spine建立邻居的源地址为loopbck0。
[Leaf1-bgp-default] peer Spine as-number 805
[Leaf1-bgp-default] peer Spine connect-interface loopback0
# 配置向对等体组Spine发布同一路由的时间间隔为0。
[Leaf1-bgp-default] peer Spine route-update-interval 0
# 将Spine设备添加为对等体组Spine中的对等体。
[Leaf1-bgp-default] peer 100.100.100.100 group Spine
[Leaf1-bgp-default] peer 100.100.100.103 group Spine
# 进入BGP IPv4单播地址族视图。
[Leaf1-bgp-default] address-family ipv4 unicast
# 配置进行BGP负载分担的路由条数为32。
[Leaf1-bgp-default-ipv4] balance 32
# 配置BGP路由的优先级,EBGP路由的优先级为10,IBGP路由的优先级为100,本地产生的BGP路由的优先级为100。
[Leaf1-bgp-default-ipv4] preference 10 100 100
# 允许本地路由器与对等体组Spine交换路由信息,发布本地业务网段路由9.179.64.0/26。
[Leaf1-bgp-default-ipv4] peer Spine enable
[Leaf1-bgp-default-ipv4] network 9.179.64.0 255.255.255.192
[Leaf1-bgp-default-ipv4] quit
[Leaf1-bgp-default] quit
(2) 配置Leaf8。
Leaf 8的配置与Leaf1类似,环回口地址为1.1.1.8,BGP发布本地业务网段路由9.179.65.192/26,具体配置略。
(3) 配置Spine1。
# 配置OSPF,与Leaf互连接口使能OSPF。
<Spine1> system-view
[Spine1] interface loopback 0
[Spine1-LoopBack0] ip address 100.100.100.100 255.255.255.255
[Spine1-LoopBack0] quit
[Spine1] ospf 1 router-id 100.100.100.100
[Spine1-ospf-1] area 0.0.0.0
[Spine1-ospf-1-area-0.0.0.0] network 100.100.100.100 0.0.0.0
[Spine1-ospf-1-area-0.0.0.0] network 9.179.56.0 0.0.0.255
[Spine1-ospf-1-area-0.0.0.0] network 9.179.57.0 0.0.0.255
[Spine1-ospf-1-area-0.0.0.0] quit
[Spine1-ospf-1] quit
# 启动BGP实例default,指定该BGP实例的本地AS号为805,并进入BGP实例视图。
<Spine1> system-view
[Spine1] bgp 805
# 配置全局Router ID为100.100.100.100。
[Spine1-bgp-default] router-id 100.100.100.100
# 配置设备在重启后延迟300秒发布路由更新消息。
[Spine1-bgp-default] bgp update-delay on-startup 300
# 创建IBGP对等体组LEAF。
[Spine1-bgp-default] group LEAF internal
# 指定对等体组LEAF建立邻居的源地址为loopbck0。
[Spine1-bgp-default] peer LEAF as-number 805
[Spine1-bgp-default] peer LEAF connect-interface loopback0
# 配置向对等体组LEAF发布同一路由的时间间隔为0。
[Spine1-bgp-default] peer LEAF route-update-interval 0
# 将Leaf设备添加为对等体组LEAF中的对等体。
[Spine1-bgp-default] peer 1.1.1.1 group LEAF
[Spine1-bgp-default] peer 1.1.1.8 group LEAF
# 进入BGP IPv4单播地址族视图。
[Spine1-bgp-default] address-family ipv4 unicast
# 配置进行BGP负载分担的路由条数为32。
[Spine1-bgp-default-ipv4] balance 32
# 配置BGP路由的优先级,EBGP路由的优先级为10,IBGP路由的优先级为100,本地产生的BGP路由的优先级为100。
[Spine1-bgp-default-ipv4] preference 10 100 100
# 允许本地路由器与对等体组LEAF100G交换路由信息,Spine为路由反射器。
[Spine1-bgp-default-ipv4] peer LEAF enable
[Spine1-bgp-default-ipv4] peer LEAF reflect-client
[Spine1-bgp-default-ipv4] quit
[Spine1-bgp-default] quit
(4) 配置Spine 4。
Spine 4的配置与Spine1类似,环回口地址为100.100.100.103,具体配置略。
(1) 配置Leaf1
# 配置队列5和队列6最多可使用的共享区域的大小为100%。队列5为RDMA应用报文队列,队列6为CNP报文所在队列。
[Leaf1] buffer egress cell queue 5 shared ratio 100
[Leaf1] buffer egress cell queue 6 shared ratio 100
[Leaf1] buffer apply
# 在接口FourHundredGigE1/0/1~FourHundredGigE1/0/64上配置队列5的WRED平均长度的下限为2100,平均长度的上限为5000,丢弃概率为20%,计算平均队列的指数为0,并为队列5开启ECN功能。开启接口的WFQ队列,并按照每次轮询可发送的报文的字节数进行计算,配置队列5具有较高调度权重60,队列6、7采用严格优先级调度。对队列6的报文进行流量整形。正常流速为200000000kbps,突发流量为16000000bytes。
[Leaf1] interface range fourhundredgige 1/0/1 to fourhundredgige 1/0/64
[Leaf1-if-range] qos wred queue 5 low-limit 2100 high-limit 5000 discard-probability 20
[Leaf1-if-range] qos wred queue 5 weighting-constant 0
[Leaf1-if-range] qos wred queue 5 ecn
[Leaf1-if-range] qos wfq byte-count
[Leaf1-if-range] qos wfq ef group 1 byte-count 60
[Leaf1-if-range] qos wfq cs6 group sp
[Leaf1-if-range] qos wfq cs7 group sp
[Leaf1-if-range] qos gts queue 6 cir 200000000 cbs 16000000
[Leaf1-if-range] quit
![]()
对于S9825系列、S9855系列交换机,支持在接口视图配置WRED的各种参数,并开启WRED功能(qos wred queue命令)。端口WRED方式可以只配置RoCE队列,不同接口可以配置不同的参数,使用更为灵活。对于支持该功能的产品和版本,推荐采用端口WRED方式。
(2) 配置Leaf8。
Leaf8和Leaf1的配置相同,具体配置略。
(3) 配置Spine1
# 配置队列5和队列6最多可使用的共享区域的大小为100%。
[Spine1] buffer egress cell queue 5 shared ratio 100
[Spine1] buffer egress cell queue 6 shared ratio 100
[Spine1] buffer apply
# 在接口FourHundredGigE1/0/1~FourHundredGigE1/0/64上配置队列5的WRED平均长度的下限为2100,平均长度的上限为5000,丢弃概率为20%,计算平均队列的指数为0,并为队列5开启ECN功能。开启接口的WFQ队列,并按照每次轮询可发送的报文字节数进行计算。配置队列5具有较高调度权重60,队列6、7采用严格优先级调度。对队列6的报文进行流量整形。正常流速为200000000kbps,突发流量为16000000bytes。
[Spine1] interface range fourhundredgige 1/0/1 to fourhundredgige 1/0/64
[Spine1-if-range] qos wred queue 5 low-limit 2100 high-limit 5000 discard-probability 20
[Spine1-if-range] qos wred queue 5 weighting-constant 0
[Spine1-if-range] qos wred queue 5 ecn
[Spine1-if-range] qos wfq byte-count
[Spine1-if-range] qos wfq ef group 1 byte-count 60
[Spine1-if-range] qos wfq cs6 group sp
[Spine1-if-range] qos wfq cs7 group sp
[Spine1-if-range] qos gts queue 6 cir 200000000 cbs 16000000
[Spine1-if-range] quit
![]()
对于S9825系列、S9855系列交换机,支持在接口视图配置WRED的各种参数,并开启WRED功能(qos wred queue命令)。端口WRED方式可以只配置RoCE队列,不同接口可以配置不同的参数,使用更为灵活。对于支持该功能的产品和版本,推荐采用端口WRED方式。
(4) 配置Spine 4
Spine 4的配置与Spine1相同,具体配置略。
(1) 配置Leaf1
# 配置Headroom最大可用的cell资源为32000(Headroom最大可用资源按照设备各个ITM所有接口配置的headroom总和计算,如S9825设备共两个ITM,每个ITM有32个400G接口(每个400G口Headroom门限为1000),则应配置为32*1000=32000)。
[Leaf1] priority-flow-control poolID 0 headroom 32000
# 配置PFC死锁检测周期为10,精度为high。
[Leaf1] priority-flow-control deadlock cos 5 interval 10
[Leaf1] priority-flow-control deadlock precision high
# 在Leaf设备连接服务器的下行接口FourHundredGigE1/0/1~FourHundredGigE1/0/32上配置接口信任DSCP优先级。
[Leaf1] interface range fourhundredgige 1/0/1 to fourhundredgige 1/0/32
[Leaf1-if-range] qos trust dscp
[Leaf1-if-range] quit
# 在Leaf设备连接Spine的上行接口FourHundredGigE1/0/33~FourHundredGigE1/0/64上配置接口信任报文自带的DSCP优先级。
[Leaf1] interface range fourhundredgige 1/0/33 to fourhundredgige 1/0/64
[Leaf1-if-range] qos trust dscp
[Leaf1-if-range] quit
# 在接口FourHundredGigE1/0/1~FourHundredGigE1/0/64上开启接口的PFC功能,并对802.1p优先级5开启PFC功能。开启接口的PFC死锁检测功能。配置接口物理连接up状态抑制时间为2秒。配置PFC门限值。
[Leaf1-1] interface range fourhundredgige 1/0/1 to fourhundredgige 1/0/64
[Leaf1-if-range] priority-flow-control enable
[Leaf1-if-range] priority-flow-control no-drop dot1p 5
[Leaf1-if-range] priority-flow-control deadlock enable
[Leaf1-if-range] link-delay up 2
[Leaf1-if-range] priority-flow-control no-drop dot1p 5 pause-threshold ratio 5 headroom 1000 pause-threshold-offset 12 reserved-buffer 16
[Leaf1-if-range] quit
(2) 配置Leaf 8
Leaf 8与Leaf1配置相同,具体步骤略。
(3) 配置Spine1
# 配置Headroom最大可用的cell资源为32000(Headroom最大可用资源按照设备各个ITM所有接口配置的headroom总和计算,如S9825设备共两个ITM,每个ITM有32个400G接口(每个400G口Headroom门限为1000),则应配置为32*1000=32000)。
[Spine1] priority-flow-control poolID 0 headroom 32000
# 配置PFC死锁检测周期为10,精度为high。
[Spine1] priority-flow-control deadlock cos 5 interval 10
[Spine1] priority-flow-control deadlock precision high
# 在接口FourHundredGigE1/0/1~FourHundredGigE1/0/64上配置接口信任报文自带的DSCP优先级,开启接口的PFC功能,并对802.1p优先级5开启PFC功能。开启接口的PFC死锁检测功能。配置接口物理连接up状态抑制时间为2秒。
[Spine1] interface range fourhundredgige 1/0/1 to fourhundredgige 1/0/64
[Spine1-if-range] qos trust dscp
[Spine1-if-range] priority-flow-control enable
[Spine1-if-range] priority-flow-control no-drop dot1p 5
[Spine1-if-range] priority-flow-control deadlock enable
[Spine1-if-range] link-delay up 2
# 配置接口FourHundredGigE1/0/1~FourHundredGigE1/0/64的PFC门限值。
[Spine1-if-range] priority-flow-control no-drop dot1p 5 pause-threshold ratio 5 headroom 1000 pause-threshold-offset 12 reserved-buffer 16
[Spine1-if-range] quit
(4) 配置Spine 4
Spine 4的配置与Spine1相同,具体配置略。
2台Spine设备、2台Leaf设备连接2台服务器进行下面验证。
验证方式一:
· 验证条件:同VLAN连接的服务器多对多打流,报文长度为9000字节。
· 验证结果:流量没有丢包,速率稳定;ECN全程生效。
验证方式二:
· 验证条件:不同VLAN连接的服务器两两互发流量,报文长度为9000字节。
· 验证结果:流量没有丢包,速率稳定;ECN全程生效,偶尔触发PFC,总体还是ECN优先生效。
综上所述,RDMA流量全程无丢包;流量速率波动正常;ECN优于PFC生效控制流量速率。
RoCE高性能存储网络用于为服务器和高性能存储之间提供高带宽无丢包的互联能力。
· 在人工智能计算中心,高性能存储网络用于连接AI训练/推理服务器和高性能存储设备,可以极大地提升AI训练和推理数据的存储和读写效率,单节点性能达到22GB/s。
· 在高性能计算中心或金融中心等场景,高性能存储网络连用于接高性能计算机和高性能存储设备,该方案可以解决客户需要高速读写数据、依赖存储性能问题的痛点。
在高性能无损存储网络中,RoCE网络对于真正发挥出iSER、NVMe-oF存储的高性能,突破数据中心大规模分布式系统的网络性能瓶颈至关重要。高性能存储网络中的RoCE网络分为如下类型:
· 集中式存储网络。
· 分布式存储前端、后端网络。
根据网络规模,高性能存储网络可以分为小规模组网和中大规模组网:
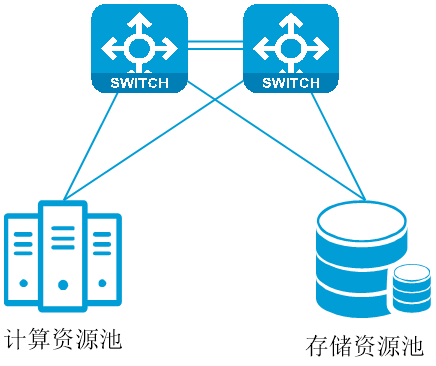
· 小规模组网(单框/单盒):在小规模场景(端口数量不超过512)下,可以根据实际情况使用单框/单盒组网,该方案部署简单、有更高的可靠性(双主控)、更先进的负载均衡技术(cell级均衡,无HASH极化等问题)、更优的拥塞控制(credit调度机制,确定性的拥塞控制),但是该方案规模有限、扩展性差,建议谨慎选择此方式。
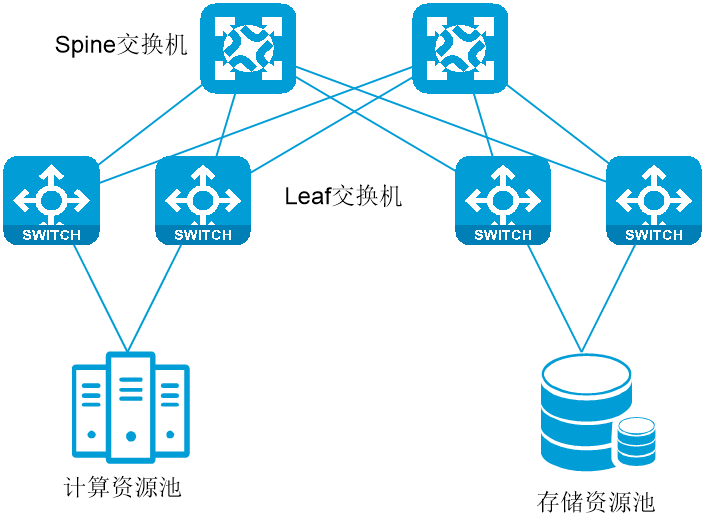
· 中大规模组网二级盒盒组网(Leaf-Spine架构):在网络规模较大推荐使用Leaf-Spine架构的二级盒盒组网,该方案易扩展、支持较大规模组网,并且转发时延较低,推荐使用此方案。
· 中大规模组网二级框盒组网(Leaf-Spine架构):在超大规模网络环境中(端口数量超过2048,服务器数量超过256),可以使用Leaf-Spine架构的二级框盒组网,但是该方案部署较为复杂,框式交换机内部转发时延较高,建议谨慎选择此方案。
对于小规模组网,建议使用单盒或单框方案,计算服务器和存储服务器与交换机互联。交换机与服务器间提供100G、200G网络可选,该网络需配置支持RDMA的RoCE特性,同时网络收敛比需高于2:3,推荐1:1。同时存储服务器和计算服务器均配置至少2个端口确保存储网络高可用。
图5-1 小规模组网
对于中大规模组网,建议使用Leaf-Spine网络架构,高性能存储网为Leaf-Spine的双层组网,Leaf和服务器间提供100G、200G网络可选,Spine和Leaf之间支持100G和400G两种。该网需配置支持RDMA的RoCE特性,同时网络收敛比需高于2:3,推荐1:1。同时存储服务器和计算服务器均配置至少2个端口确保存储网络高可用。
图5-2 中大规模组网示例
以二层盒盒组网为例,集中式存储的RoCE高性能存储网络典型组网如下图所示。
本节以每个平面使用Leaf-Spine的两层组网为例,Leaf和Spine均使用S6850-G系列盒式交换机。在该组网中,服务器和存储均采用VLAN接入,使用25G带宽链路,分别接入到两个平面的交换机;Leaf和Spine之间采用路由口互联,使用多条100G带宽链路,形成等价路由。
存储、存储服务器和交换机均支持iNOF(Intelligent Lossless NVMe Over Fabric,智能无损存储网络),从而可以快速感知网络服务器和磁盘设备的加入和离开。
本组网中要求实现RDMA应用报文使用队列5进行无损传输。
![]()
本文以一个平面1台Leaf设备示例,实际组网时一个平面可能存在多台Leaf,各Leaf设备的配置相似,此处不再一一列出。
图5-3 集中式存储典型组网
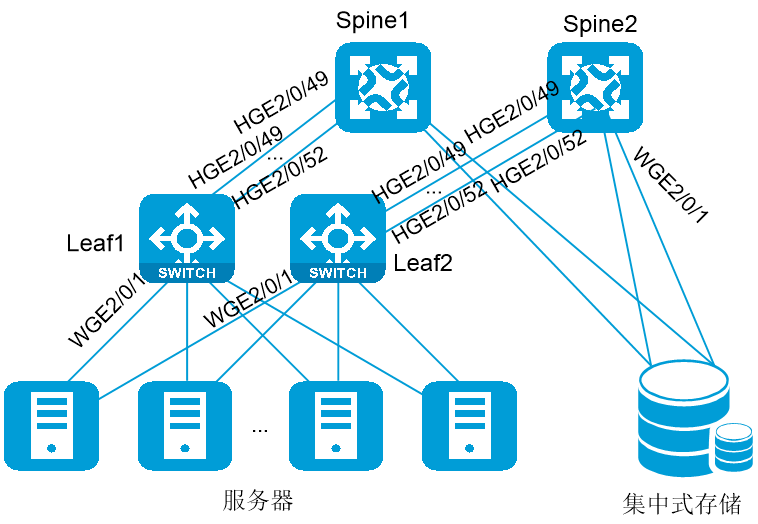
表5-1 服务器/存储接入口IP规划
|
设备 |
接口 |
IP地址/VLAN |
设备 |
接口 |
IP地址/VLAN |
|
Leaf1 |
WGE2/0/1 |
100 |
Leaf2 |
WGE2/0/1 |
200 |
|
… |
100 |
… |
200 |
||
|
WGE2/0/8 |
100 |
WGE2/0/8 |
200 |
||
|
Vlan-int100 |
100.1.1.254/24 |
Vlan-int200 |
200.1.1.254/24 |
||
|
LoopBack 0 |
91.1.1.1/32 |
LoopBack 0 |
91.1.1.2/32 |
||
|
Spine1 |
WGE2/0/1 |
101 |
Spine2 |
WGE2/0/1 |
201 |
|
… |
101 |
… |
201 |
||
|
WGE2/0/8 |
101 |
WGE2/0/8 |
201 |
||
|
Vlan-int101 |
101.1.1.254/24 |
Vlan-int200 |
201.1.1.254/24 |
||
|
LoopBack 0 |
92.1.1.1/32 |
LoopBack 0 |
92.1.1.2/32 |
表5-2 Leaf-Spine互联接口IP规划
|
设备 |
接口 |
IP地址/VLAN |
设备 |
接口 |
IP地址/VLAN |
|
Leaf1 |
HGE2/0/49 |
172.16.24.1/30 |
Spine1 |
HGE2/0/49 |
172.16.24.2/30 |
|
HGE2/0/50 |
172.16.24.5/30 |
HGE2/0/50 |
172.16.24.6/30 |
||
|
HGE2/0/52 |
172.16.24.9/30 |
HGE2/0/52 |
172.16.24.10/30 |
||
|
HGE2/0/52 |
172.16.24.13/30 |
HGE2/0/52 |
172.16.24.14/30 |
||
|
Leaf2 |
HGE2/0/49 |
172.16.25.1/30 |
Spine2 |
HGE2/0/49 |
172.16.25.2/30 |
|
HGE2/0/50 |
172.16.25.5/30 |
HGE2/0/50 |
172.16.25.6/30 |
||
|
HGE2/0/51 |
172.16.25.9/30 |
HGE2/0/51 |
172.16.25.10/30 |
||
|
HGE2/0/52 |
172.16.25.13/30 |
HGE2/0/52 |
172.16.25.14/30 |
![]()
· Leaf上服务器接入口的配置相似,配置仅以少量接口为例。
· Spine上存储接入口的配置相似,配置仅以少量接口为例。
· Leaf与Spine之间互联接口的配置相似,配置仅以少量接口为例。
· 本文以一个平面1台Leaf设备示例,实际组网时一个平面可能存在多台Leaf,各Leaf设备的配置相似,此处不再一一列出。
每个平面采用Leaf-Spine的两层组网形式。
使用IBGP作为路由互通协议:
· 通过BGP的IPv4地址族进行RDMA业务转发,发布Loopback口的地址(也作为router-id)、Leaf与Spine互联接口的网段、服务器/存储接入口的网段。
· 通过BGP的iNOF地址族传递存储、服务器的iNOF信息,Spine配置为路由反射器。
· 存储和服务器配置网关或路由,保证相互路由可达。
![]()
请按照业务需求和组网规模选择合适的路由协议,使用iNOF功能时,必须配置BGP的iNOF地址族用于iNOF信息传递,RDMA业务流量使用的路由协议没有限制。
为实现RDMA应用报文的无损传输,我们需要部署PFC功能和ECN功能:
· PFC功能基于优先级队列对报文进行流量控制。RDMA报文携带802.1P优先级5,我们对802.1P优先级为5的报文开启PFC功能。
RDMA报文转发路径的所有端口都需要配置PFC功能。
· ECN功能提供端到端的拥塞控制。设备检测到拥塞后,对报文的ECN域进行标记。接收端收到ECN标记的报文后,向发送端发送拥塞通知报文,使发送端降低流量发送速率。ECN分为手工指定WRED参数来实现的静态ECN,和AI组件实现的AI ECN功能:
¡ 如果配置静态ECN功能,则在本例中,我们在报文转发路径的所有端口均开启ECN功能。ECN功能配置的high-limit值(queue queue-id [ drop-level drop-level ] low-limit low-limit high-limit high-limit [ discard-probability discard-prob ])需要小于PFC反压帧触发门限值,以使ECN功能先生效。
¡ 如果Spine设备与Leaf设备都支持AI ECN功能,则可以开启指定队列的AI ECN功能。在智能无损网络中配置AI ECN功能时,需要先配置RoCEv2流量NetAnalysis功能,由NetAnalysis技术对现网的流量特征进行深度分析。关键配置包括:
- 使用netanalysis rocev2 mode命令配置RoCEv2流量NetAnalysis功能的工作模式;
- 使用netanalysis rocev2 statistics命令开启RoCEv2流量的NetAnalysis统计功能;
- 使用netanalysis rocev2 ai-ecn enable命令开启RoCEv2流量的AI ECN功能。
PFC和ECN参数请参考推荐值(国产芯片设备S12500G-AF/S12500CR/S6850-G)。
Leaf和Spine均使能iNOF,与存储、服务器互联的接口需要使能lldp和dcbx等功能。
需要在Spine上配置iNOF zone,并按照规划将存储、服务器的ip添加到相应的iNOF zone中以用于访问控制。
请确认存储及服务器的软件支持SNSD功能并配置正确,否则服务器和存储不能通过iNOF信息自动建立链接,也会导致存储网络的iNOF快速感知功能失效。
本文仅涉及交换机配置,存储以及存储服务器的配置,请以使用产品的资料为准。
静态ECN功能与AIECN功能选择一种配置即可。如果Spine设备与Leaf设备都支持AI ECN功能,则建议配置AI ECN功能。
AI ECN功能受License限制,请在使用本功能前安装有效的License。有关License的详细介绍,请参见“基础配置指导”中的“License管理”。
配置PFC功能时,必须配置接口信任报文自带的802.1p优先级或DSCP优先级(qos trust { dot1p | dscp }),并且转发路径上所有端口的802.1p优先级与本地优先级映射关系以及DSCP优先级与802.1p优先级映射关系必须一致,否则PFC功能将无法正常工作。对于本组网中的二层接口,建议配置接口信任报文自带的802.1p优先级(qos trust dot1p),对于三层接口,建议配置接口信任报文自带的DSCP优先级(qos trust dscp)。
对于接收到的以太网报文,设备将根据优先级信任模式和报文的802.1Q标签状态,设备将采用不同的方式为其标记调度优先级。当设备连接不同网络时,所有进入设备的报文,其外部优先级字段(包括DSCP和IP)都被映射为802.1p优先级,再根据802.1p优先级映射为内部优先级;设备根据内部优先级进行队列调度的QoS处理。
关于优先级映射的详细介绍,请参见产品配套的“ACL和QoS配置指导”中的“优先级映射”。
(1) 全局使能LLDP功能
# 全局使能LLDP功能。
<Leaf1> system-view
[Leaf1] lldp global enable
(2) VLAN和接口配置
# 创建VLAN。
[Leaf1] vlan 100
[Leaf1-vlan100] quit
# 创建vlan虚接口。
[Leaf1] interface Vlan-interface 100
# 配置vlan虚接口地址,作为业务服务器RDMA网卡接口的网关。
[Leaf1-Vlan-interface100] ip address 100.1.1.254 24
# 配置vlan虚接口mac地址。
[Leaf1-Vlan-interface100] mac-address 0000-5e00-0001
[Leaf1-Vlan-interface100] quit
# 进入批量接口配置视图,配置与业务服务器网卡对接的接口。
[Leaf1] interface range Twenty-FiveGigE 2/0/1 to Twenty-FiveGigE 2/0/8
# 将接口的链路类型修改为trunk。
[Leaf1-if-range] port link-type trunk
# 禁止vlan 1通过这些trunk接口。
[Leaf1-if-range] undo port trunk permit vlan 1
# 允许vlan 100通过这些trunk接口。
[Leaf1-if-range] port trunk permit vlan 100
# 配置为stp edge-port。
[Leaf1-if-range] stp edged-port
# 允许lldp发布dot1-tlv的tlv类型。
[Leaf1-if-range] lldp tlv-enable dot1-tlv dcbx
# 端口信任802.1p优先级。
[Leaf1-if-range] qos trust dot1p
[Leaf1-if-range] quit
# 进入批量接口配置视图,配置与Spine对接的接口。
[Leaf1] interface range HundredGigE 2/0/49 to HundredGigE 2/0/52
# 将以太接口切换为三层工作模式。
[Leaf1-if-range] port link-mode route
The configuration of the interface will be restored to the default. Continue? [Y
/N]:y
# 端口信任DSCP优先级。
[Leaf1-if-range] qos trust dscp
[Leaf1-if-range] quit
# 配置接口IP地址。
[Leaf1] interface HundredGigE 2/0/49
[Leaf1-HundredGigE2/0/49] ip address 172.16.24.1 30
[Leaf1-HundredGigE2/0/49] quit
[Leaf1] interface HundredGigE 2/0/50
[Leaf1-HundredGigE2/0/50] ip address 172.16.24.5 30
[Leaf1-HundredGigE2/0/50] quit
其它接口配置方法类似,后略。
(3) 配置BGP路由协议。
# 创建接口LoopBack 0。
[Leaf1] interface LoopBack 0
# 配置LoopBack 0的ip,作为全局的Router ID
[Leaf1-LoopBack0] ip address 91.1.1.1 32
[Leaf1-LoopBack0] quit
# 配置全局Router ID
[Leaf1] router-id 91.1.1.1
# 启动BGP实例default,指定该BGP实例的本地AS号,并进入BGP实例视图
[Leaf1-bgp-default] bgp 65512
# 配置BGP的Router ID
[Leaf1-bgp-default] router-id 91.1.1.1
# 将Spine设备添加为对等体
[Leaf1-bgp-default] peer 172.16.24.2 as-number 65512
[Leaf1-bgp-default] peer 172.16.24.6 as-number 65512
…
# 进入BGP ipv4单播地址族视图
[Leaf1-bgp-default] address-family ipv4 unicast
# 配置进行BGP负载分担的路由条数为16
[Leaf1-bgp-default-ipv4] balance 16
# 发布Loopback0接口地址的路由
[Leaf1-bgp-default-ipv4] network 91.1.1.1 255.255.255.255
# 发布业务服务器接入网段的路由
[Leaf1-bgp-default-ipv4] network 100.1.1.0 255.255.255.0
# 发布与Spine互联接口的网段路由
[Leaf1-bgp-default-ipv4] network 172.16.24.0 255.255.255.252
[Leaf1-bgp-default-ipv4] network 172.16.24.4 255.255.255.252
…
# 允许本地路由器与对等体交换路由信息
[Leaf1-bgp-default-ipv4] peer 172.16.24.2 enable
[Leaf1-bgp-default-ipv4] peer 172.16.24.6 enable
…
[Leaf1-bgp-default-ipv4] quit
# 进入BGP iNOF地址族视图
[Leaf1-bgp-default] address-family inof
# 配置Leaf角色为客户机
[Leaf1-bgp-default-inof] role reflect-client
# 允许本地路由器与对等体交换路由信息
[Leaf1-bgp-default-inof] peer 172.16.24.2 enable
[Leaf1-bgp-default-inof] peer 172.16.24.6 enable
…
[Leaf1-bgp-default-inof]quit
[Leaf1-bgp-default]quit
(4) 配置静态ECN功能(本功能与AI ECN功能选择一种配置即可)
# 配置队列5和队列6最多可使用的共享区域的大小为100%。队列5为RDMA应用报文队列,队列6为CNP报文所在队列。
[Leaf1] buffer egress cell queue 5 shared ratio 100
[Leaf1] buffer egress cell queue 6 shared ratio 100
[Leaf1] buffer apply
# 全局使能ECN拥塞标记功能。
[Leaf1] qos wred ecn enable
# 进入批量接口配置视图,配置与业务服务器网卡对接的接口。
[Leaf1] interface range Twenty-FiveGigE 2/0/1 to Twenty-FiveGigE 2/0/8
# 配置队列5的WRED平均长度的下限为500,平均长度的上限为1200,丢弃概率为20%。
[Leaf1-if-range] qos wred queue 5 low-limit 500 high-limit 1200 discard-probability 20
# 开启接口的WFQ队列,并按照每次轮询可发送的报文的字节数进行计算,配置队列5具有较高调度权重60,队列6、7采用严格优先级调度。
[Leaf1-if-range] qos wfq byte-count
[Leaf1-if-range] qos wfq ef group 1 byte-count 60
[Leaf1-if-range] qos wfq cs6 group sp
[Leaf1-if-range] qos wfq cs7 group sp
# 对队列6的报文进行流量整形,正常流速为12500000kbps(建议配置为接口带宽的一半)。
[Leaf1-if-range] qos gts queue 6 cir 12500000
[Leaf1-if-range] quit
# 进入批量接口配置视图,配置与Spine对接的接口。
[Leaf1] interface range HundredGigE 2/0/49 to HundredGigE 2/0/52
# 配置队列5的WRED平均长度的下限为600,平均长度的上限为2000,丢弃概率为20%。
[Leaf1-if-range] qos wred queue 5 low-limit 600 high-limit 2000 discard-probability 20
# 开启接口的WFQ队列,并按照每次轮询可发送的报文的字节数进行计算,配置队列5具有较高调度权重60,队列6、7采用严格优先级调度。
[Leaf1-if-range] qos wfq byte-count
[Leaf1-if-range] qos wfq ef group 1 byte-count 60
[Leaf1-if-range] qos wfq cs6 group sp
[Leaf1-if-range] qos wfq cs7 group sp
# 对队列6的报文进行流量整形,正常流速为50000000kbps(建议配置为接口带宽的一半)。
[Leaf1-if-range] qos gts queue 6 cir 50000000
[Leaf1-if-range] quit
![]()
对于S6850-G系列交换机,支持在接口视图配置WRED的各种参数。端口WRED方式可以只配置RoCE队列,不同接口可以配置不同的参数,使用更为灵活。对于支持该功能的产品和版本,推荐采用端口WRED方式。
(5) 配置AI ECN功能(S6850-G仅R8108Pxx及以上版本支持,本功能与静态ECN功能选择一种配置即可)
# 配置RoCEv2流量NetAnalysis功能的工作模式。为了保证能够正确分析RoCEv2流量,当同一个RDMA客户端和服务器端存在多条路径时,建议在客户端和服务器端接入的节点设备上均配置双向模式,在所有的中间节点设备上均配置单向模式。
[Leaf1] netanalysis rocev2 mode bidir
This operation will erase all the netanalysis configuration.
Continue?[Y/N]:y
# 开启RoCEv2流量的NetAnalysis统计功能。
[Leaf1] netanalysis rocev2 statistics global
# 开启RoCEv2流量的AI ECN功能。
[Leaf1] netanalysis rocev2 ai-ecn enable
# 配置AI ECN功能的模式为分布式模式。
[Leaf1] ai-service
[Leaf1-ai-service] ai ai-ecn enable mode distributed
# 开启队列5、6的AI ECN功能。
[Leaf1-ai-service] ai-ecn
[Leaf1-ai-service-ai-ecn] queue 5 enable
[Leaf1-ai-service-ai-ecn] queue 6 enable
[Leaf1-ai-service-ai-ecn] quit
[Leaf1-ai-service] quit
(6) 配置PFC功能和PFC死锁检测功能。
# 全局配置5队列的PFC死锁检测周期为10。
[Leaf1] priority-flow-control deadlock cos 5 interval 10
# 全局配置PFC死锁检测的精度为high。
[Leaf1] priority-flow-control deadlock precision high
# 进入批量接口配置视图,配置与业务服务器网卡对接的接口。
[Leaf1] interface range Twenty-FiveGigE 2/0/1 to Twenty-FiveGigE 2/0/8
# 开启与对端自动协商是否开启PFC功能。
[Leaf1-if-range] priority-flow-control auto
# 开启指定5队列的PFC功能。
[Leaf1-if-range] priority-flow-control no-drop dot1p 5
# 开启接口的PFC死锁检测功能。
[Leaf1-if-range] priority-flow-control deadlock enable
# 配置PFC的反压帧触发门限为3500,反压帧停止门限与触发门限间的偏移量为51,Headroom缓存门限为2000,PFC预留门限为30。
[Leaf1-if-range] priority-flow-control dot1p 5 headroom 2000
[Leaf1-if-range] priority-flow-control dot1p 5 reserved-buffer 30
[Leaf1-if-range] priority-flow-control dot1p 5 ingress-buffer static 3500
[Leaf1-if-range] priority-flow-control dot1p 5 ingress-threshold-offset 51
[Leaf1-if-range] quit
# 进入批量接口配置视图,配置与Spine对接的接口。
[Leaf1] interface range HundredGigE 2/0/49 to HundredGigE 2/0/52
# 开启与对端自动协商是否开启PFC功能。
[Leaf1-if-range] priority-flow-control auto
# 开启指定5队列的PFC功能。
[Leaf1-if-range] priority-flow-control no-drop dot1p 5
# 开启接口的PFC死锁检测功能。
[Leaf1-if-range] priority-flow-control deadlock enable
# 配置PFC的反压帧触发门限为4000,反压帧停止门限与触发门限间的偏移量为51,Headroom缓存门限为3000,PFC预留门限为30。
[Leaf1-if-range] priority-flow-control dot1p 5 headroom 3000
[Leaf1-if-range] priority-flow-control dot1p 5 reserved-buffer 30
[Leaf1-if-range] priority-flow-control dot1p 5 ingress-buffer static 4000
[Leaf1-if-range] priority-flow-control dot1p 5 ingress-threshold-offset 51
[Leaf1-if-range] quit
(7) 配置iNOF功能
# 全局使能iNOF功能,并进入iNOF视图。
[Leaf1] inof enable
[Leaf1-inof] quit
(1) 全局使能LLDP功能
# 全局使能LLDP功能。
<Leaf2> system-view
[Leaf2] lldp global enable
(2) VLAN和接口配置
# 创建VLAN。
[Leaf2] vlan 200
[Leaf2-vlan200] quit
# 创建vlan虚接口。
[Leaf2] interface Vlan-interface 200
# 配置vlan虚接口地址,作为业务服务器RDMA网卡接口的网关。
[Leaf2-Vlan-interface200] ip address 200.1.1.254 24
# 配置vlan虚接口mac地址。
[Leaf2-Vlan-interface200] mac-address 0000-5e00-0001
[Leaf2-Vlan-interface200] quit
# 进入批量接口配置视图,配置与业务服务器网卡对接的接口。
[Leaf2] interface range Twenty-FiveGigE 2/0/1 to Twenty-FiveGigE 2/0/8
# 将接口的链路类型修改为trunk。
[Leaf2-if-range] port link-type trunk
# 禁止vlan 1通过这些trunk接口。
[Leaf2-if-range] undo port trunk permit vlan 1
# 允许vlan 200通过这些trunk接口。
[Leaf2-if-range] port trunk permit vlan 200
# 配置为stp edge-port。
[Leaf2-if-range] stp edged-port
# 允许lldp发布dot1-tlv的tlv类型。
[Leaf2-if-range] lldp tlv-enable dot1-tlv dcbx
# 端口信任802.1p优先级。
[Leaf2-if-range] qos trust dot1p
[Leaf2-if-range] quit
# 进入批量接口配置视图,配置与Spine对接的接口。
[Leaf2] interface range HundredGigE 2/0/49 to HundredGigE 2/0/52
# 将以太接口切换为三层工作模式。
[Leaf2-if-range] port link-mode route
The configuration of the interface will be restored to the default. Continue? [Y
/N]:y
# 端口信任DSCP优先级。
[Leaf2-if-range] qos trust dscp
[Leaf2-if-range] quit
# 配置接口IP地址。
[Leaf2] interface HundredGigE 2/0/49
[Leaf2-HundredGigE2/0/49] ip address 172.16.25.1 30
[Leaf2-HundredGigE2/0/49] quit
[Leaf2] interface HundredGigE 2/0/50
[Leaf2-HundredGigE2/0/50] ip address 172.16.25.5 30
[Leaf2-HundredGigE2/0/50] quit
其它接口配置方法类似,后略。
(3) 配置BGP路由协议。
# 创建接口LoopBack 0。
[Leaf2] interface LoopBack 0
# 配置LoopBack 0的ip,作为全局的Router ID
[Leaf2-LoopBack0] ip address 91.1.1.2 32
[Leaf2-LoopBack0] quit
# 配置全局Router ID
[Leaf2] router-id 91.1.1.2
# 启动BGP实例default,指定该BGP实例的本地AS号,并进入BGP实例视图
[Leaf2-bgp-default] bgp 65513
# 配置BGP的Router ID
[Leaf2-bgp-default] router-id 91.1.1.2
# 将Spine设备添加为对等体
[Leaf2-bgp-default] peer 172.16.25.2 as-number 65513
[Leaf2-bgp-default] peer 172.16.25.6 as-number 65513
…
# 进入BGP ipv4单播地址族视图
[Leaf2-bgp-default] address-family ipv4 unicast
# 配置进行BGP负载分担的路由条数为16
[Leaf2-bgp-default-ipv4] balance 16
# 发布Loopback0接口地址的路由
[Leaf2-bgp-default-ipv4] network 91.1.1.2 255.255.255.255
# 发布业务服务器接入网段的路由
[Leaf2-bgp-default-ipv4] network 200.1.1.0 255.255.255.0
# 发布与Spine互联接口的网段路由
[Leaf2-bgp-default-ipv4] network 172.16.25.0 255.255.255.252
[Leaf2-bgp-default-ipv4] network 172.16.25.4 255.255.255.252
…
# 允许本地路由器与对等体交换路由信息
[Leaf2-bgp-default-ipv4] peer 172.16.25.2 enable
[Leaf2-bgp-default-ipv4] peer 172.16.25.6 enable
…
[Leaf2-bgp-default-ipv4] quit
# 进入BGP iNOF地址族视图
[Leaf2-bgp-default] address-family inof
# 配置Leaf角色为客户机
[Leaf2-bgp-default-inof] role reflect-client
# 允许本地路由器与对等体交换路由信息
[Leaf2-bgp-default-inof] peer 172.16.24.2 enable
[Leaf2-bgp-default-inof] peer 172.16.24.6 enable
…
[Leaf2-bgp-default-inof]quit
[Leaf2-bgp-default]quit
(4) 配置静态ECN功能(本功能与AI ECN功能选择一种配置即可)
# 配置队列5和队列6最多可使用的共享区域的大小为100%。队列5为RDMA应用报文队列,队列6为CNP报文所在队列。
[Leaf2] buffer egress cell queue 5 shared ratio 100
[Leaf2] buffer egress cell queue 6 shared ratio 100
[Leaf2] buffer apply
# 全局使能ECN拥塞标记功能。
[Leaf2] qos wred ecn enable
# 进入批量接口配置视图,配置与业务服务器网卡对接的接口。
[Leaf2] interface range Twenty-FiveGigE 2/0/1 to Twenty-FiveGigE 2/0/8
# 配置队列5的WRED平均长度的下限为500,平均长度的上限为1200,丢弃概率为20%。
[Leaf2-if-range] qos wred queue 5 low-limit 500 high-limit 1200 discard-probability 20
# 开启接口的WFQ队列,并按照每次轮询可发送的报文的字节数进行计算,配置队列5具有较高调度权重60,队列6、7采用严格优先级调度。
[Leaf2-if-range] qos wfq byte-count
[Leaf2-if-range] qos wfq ef group 1 byte-count 60
[Leaf2-if-range] qos wfq cs6 group sp
[Leaf2-if-range] qos wfq cs7 group sp
# 对队列6的报文进行流量整形,正常流速为12500000kbps(建议配置为接口带宽的一半)。
[Leaf2-if-range] qos gts queue 6 cir 12500000
[Leaf2-if-range] quit
# 进入批量接口配置视图,配置与Spine对接的接口。
[Leaf2] interface range HundredGigE 2/0/49 to HundredGigE 2/0/52
# 配置队列5的WRED平均长度的下限为600,平均长度的上限为2000,丢弃概率为20%。
[Leaf2-if-range] qos wred queue 5 low-limit 600 high-limit 2000 discard-probability 20
# 开启接口的WFQ队列,并按照每次轮询可发送的报文的字节数进行计算,配置队列5具有较高调度权重60,队列6、7采用严格优先级调度。
[Leaf2-if-range] qos wfq byte-count
[Leaf2-if-range] qos wfq ef group 1 byte-count 60
[Leaf2-if-range] qos wfq cs6 group sp
[Leaf2-if-range] qos wfq cs7 group sp
# 对队列6的报文进行流量整形,正常流速为50000000kbps(建议配置为接口带宽的一半)。
[Leaf2-if-range] qos gts queue 6 cir 50000000
[Leaf2-if-range] quit
![]()
对于S6850-G系列交换机,支持在接口视图配置WRED的各种参数。端口WRED方式可以只配置RoCE队列,不同接口可以配置不同的参数,使用更为灵活。对于支持该功能的产品和版本,推荐采用端口WRED方式。
(5) 配置AI ECN功能(S6850-G仅R8108Pxx及以上版本支持,本功能与静态ECN功能选择一种配置即可)
# 配置RoCEv2流量NetAnalysis功能的工作模式。为了保证能够正确分析RoCEv2流量,当同一个RDMA客户端和服务器端存在多条路径时,建议在客户端和服务器端接入的节点设备上均配置双向模式,在所有的中间节点设备上均配置单向模式。
[Leaf2] netanalysis rocev2 mode bidir
This operation will erase all the netanalysis configuration.
Continue?[Y/N]:y
# 开启RoCEv2流量的NetAnalysis统计功能。
[Leaf2] netanalysis rocev2 statistics global
# 开启RoCEv2流量的AI ECN功能。
[Leaf2] netanalysis rocev2 ai-ecn enable
# 配置AI ECN功能的模式为分布式模式。
[Leaf2] ai-service
[Leaf2-ai-service] ai ai-ecn enable mode distributed
# 开启队列5、6的AI ECN功能。
[Leaf2-ai-service] ai-ecn
[Leaf2-ai-service-ai-ecn] queue 5 enable
[Leaf2-ai-service-ai-ecn] queue 6 enable
[Leaf2-ai-service-ai-ecn] quit
[Leaf2-ai-service] quit
(6) 配置PFC功能和PFC死锁检测功能。
# 全局配置5队列的PFC死锁检测周期为10。
[Leaf2] priority-flow-control deadlock cos 5 interval 10
# 全局配置PFC死锁检测的精度为high。
[Leaf2] priority-flow-control deadlock precision high
# 进入批量接口配置视图,配置与业务服务器网卡对接的接口。
[Leaf2] interface range Twenty-FiveGigE 2/0/1 to Twenty-FiveGigE 2/0/8
# 开启与对端自动协商是否开启PFC功能。
[Leaf2-if-range] priority-flow-control auto
# 开启指定5队列的PFC功能。
[Leaf2-if-range] priority-flow-control no-drop dot1p 5
# 开启接口的PFC死锁检测功能。
[Leaf2-if-range] priority-flow-control deadlock enable
# 配置PFC的反压帧触发门限为3500,反压帧停止门限与触发门限间的偏移量为51,Headroom缓存门限为2000,PFC预留门限为30。
[Leaf2-if-range] priority-flow-control dot1p 5 headroom 2000
[Leaf2-if-range] priority-flow-control dot1p 5 reserved-buffer 30
[Leaf2-if-range] priority-flow-control dot1p 5 ingress-buffer static 3500
[Leaf2-if-range] priority-flow-control dot1p 5 ingress-threshold-offset 51
[Leaf2-if-range] quit
# 进入批量接口配置视图,配置与Spine对接的接口。
[Leaf2] interface range HundredGigE 2/0/49 to HundredGigE 2/0/52
# 开启与对端自动协商是否开启PFC功能。
[Leaf2-if-range] priority-flow-control auto
# 开启指定5队列的PFC功能。
[Leaf2-if-range] priority-flow-control no-drop dot1p 5
# 开启接口的PFC死锁检测功能。
[Leaf2-if-range] priority-flow-control deadlock enable
# 配置PFC的反压帧触发门限为4000,反压帧停止门限与触发门限间的偏移量为51,Headroom缓存门限为3000,PFC预留门限为30。
[Leaf2-if-range] priority-flow-control dot1p 5 headroom 3000
[Leaf2-if-range] priority-flow-control dot1p 5 reserved-buffer 30
[Leaf2-if-range] priority-flow-control dot1p 5 ingress-buffer static 4000
[Leaf2-if-range] priority-flow-control dot1p 5 ingress-threshold-offset 51
[Leaf2-if-range] quit
(7) 配置iNOF功能
# 全局使能iNOF功能,并进入iNOF视图。
[Leaf2] inof enable
[Leaf2-inof] quit
(1) 全局使能LLDP功能
# 全局使能LLDP功能。
<Spine1> system-view
[Spine1] lldp global enable
(2) VLAN和接口配置
# 创建VLAN。
[Spine1] vlan 101
[Spine1-vlan101] quit
# 创建vlan虚接口。
[Spine1] interface Vlan-interface 101
# 配置vlan虚接口地址,作为业务服务器RDMA网卡接口的网关。
[Spine1-Vlan-interface101] ip address 101.1.1.254 24
# 配置vlan虚接口mac地址。
[Spine1-Vlan-interface101] mac-address 0000-5e00-0001
[Spine1-Vlan-interface101] quit
# 进入批量接口配置视图,配置与存储网卡对接的接口。
[Spine1] interface range Twenty-FiveGigE 2/0/1 to Twenty-FiveGigE 2/0/8
# 将接口的链路类型修改为trunk。
[Spine1-if-range] port link-type trunk
# 禁止vlan 1通过这些trunk接口。
[Spine1-if-range] undo port trunk permit vlan 1
# 允许vlan 101通过这些trunk接口。
[Spine1-if-range] port trunk permit vlan 101
# 配置为stp edge-port。
[Spine1-if-range] stp edged-port
# 允许lldp发布dot1-tlv的tlv类型。
[Spine1-if-range] lldp tlv-enable dot1-tlv dcbx
# 端口信任802.1p优先级。
[Spine1-if-range] qos trust dot1p
[Spine1-if-range] quit
# 进入批量接口配置视图,配置与Leaf对接的接口。
[Spine1] interface range HundredGigE 2/0/49 to HundredGigE 2/0/52
# 将以太接口切换为三层工作模式。
[Spine1-if-range] port link-mode route
The configuration of the interface will be restored to the default. Continue? [Y
/N]:y
# 端口信任DSCP优先级。
[Spine1-if-range] qos trust dscp
[Spine1-if-range] quit
# 配置接口IP地址。
[Spine1] interface HundredGigE 2/0/49
[Spine1-HundredGigE2/0/49] ip address 172.16.24.2 30
[Spine1-HundredGigE2/0/49] quit
[Spine1] interface HundredGigE 2/0/50
[Spine1-HundredGigE2/0/50] ip address 172.16.24.6 30
[Spine1-HundredGigE2/0/50] quit
其它接口配置方法类似,后略。
(3) 配置BGP路由协议。
# 创建接口LoopBack 0。
[Spine1] interface LoopBack 0
# 配置LoopBack 0的IP,作为全局的Router ID
[Spine1-LoopBack0] ip address 92.1.1.1 32
[Spine1-LoopBack0] quit
# 配置全局Router ID
[Spine1] router-id 92.1.1.1
# 启动BGP实例default,指定该BGP实例的本地AS号,并进入BGP实例视图
[Spine1-bgp-default] bgp 65512
# 配置BGP的Router ID
[Spine1-bgp-default] router-id 92.1.1.1
# 将Leaf设备添加为对等体
[Spine1-bgp-default] peer 172.16.24.1 as-number 65512
[Spine1-bgp-default] peer 172.16.24.5 as-number 65512
…
# 进入BGP ipv4单播地址族视图
[Spine1-bgp-default] address-family ipv4 unicast
# 配置进行BGP负载分担的路由条数为16
[Spine1-bgp-default-ipv4] balance 16
# 发布Loopback0接口地址的路由。
[Spine1-bgp-default-ipv4] network 92.1.1.1 255.255.255.255
# 发布存储网卡接入网段的路由。
[Spine1-bgp-default-ipv4] network 101.1.1.0 255.255.255.0
# 发布与Leaf互联接口的网段路由
[Spine1-bgp-default-ipv4] network 172.16.24.0 255.255.255.252
[Spine1-bgp-default-ipv4] network 172.16.24.4 255.255.255.252
…
# 允许本地路由器与对等体交换路由信息,配置对等体为路由反射器的客户机。
[Spine1-bgp-default-ipv4] peer 172.16.24.1 enable
[Spine1-bgp-default-ipv4] peer 172.16.24.5 enable
[Spine1-bgp-default-ipv4] peer 172.16.24.1 reflect-client
[Spine1-bgp-default-ipv4] peer 172.16.24.5 reflect-client
…
[Spine1-bgp-default-ipv4] quit
# 进入BGP iNOF地址族视图。
[Spine1-bgp-default] address-family inof
# 配置Spine角色为反射器。
[Spine1-bgp-default-inof] role reflector
# 允许本地路由器与对等体交换路由信息,配置对等体为路由反射器的客户机。
[Spine1-bgp-default-inof] peer 172.16.24.1 enable
[Spine1-bgp-default-inof] peer 172.16.24.5 enable
[Spine1-bgp-default-inof] peer 172.16.24.1 reflect-client
[Spine1-bgp-default-inof] peer 172.16.24.5 reflect-client
…
[Spine1-bgp-default-inof]quit
[Spine1-bgp-default]quit
![]()
使用EBGP作为传递iNOF信息的路由协议时,iNOF地址族不需要配置role reflector,IPv4和iNOF地址族不需要配置peer {ipv4-address | ipv6-address } reflect-client。
(4) 配置静态ECN功能(本功能与AI ECN功能选择一种配置即可)
# 配置队列5和队列6最多可使用的共享区域的大小为100%。队列5为RDMA应用报文队列,队列6为CNP报文所在队列。
[Spine1] buffer egress cell queue 5 shared ratio 100
[Spine1] buffer egress cell queue 6 shared ratio 100
[Spine1] buffer apply
# 全局使能ECN拥塞标记功能。
[Spine1] qos wred ecn enable
# 进入批量接口配置视图,配置与存储网卡对接的接口。
[Spine1] interface range Twenty-FiveGigE 2/0/1 to Twenty-FiveGigE 2/0/8
# 配置队列5的WRED平均长度的下限为500,平均长度的上限为1200,丢弃概率为20%。
[Spine1-if-range] qos wred queue 5 low-limit 500 high-limit 1200 discard-probability 20
# 开启接口的WFQ队列,并按照每次轮询可发送的报文的字节数进行计算,配置队列5具有较高调度权重60,队列6、7采用严格优先级调度。
[Spine1-if-range] qos wfq byte-count
[Spine1-if-range] qos wfq ef group 1 byte-count 60
[Spine1-if-range] qos wfq cs6 group sp
[Spine1-if-range] qos wfq cs7 group sp
# 对队列6的报文进行流量整形,正常流速为12500000kbps(建议配置为接口带宽的一半)。
[Spine1-if-range] qos gts queue 6 cir 12500000
[Spine1-if-range] quit
# 进入批量接口配置视图,配置与Leaf对接的接口。
[Spine1] interface range HundredGigE 2/0/49 to HundredGigE 2/0/52
# 配置队列5的WRED平均长度的下限为600,平均长度的上限为2000,丢弃概率为20%。
[Spine1-if-range] qos wred queue 5 low-limit 600 high-limit 2000 discard-probability 20
# 开启接口的WFQ队列,并按照每次轮询可发送的报文的字节数进行计算,配置队列5具有较高调度权重60,队列6、7采用严格优先级调度。
[Spine1-if-range] qos wfq byte-count
[Spine1-if-range] qos wfq ef group 1 byte-count 60
[Spine1-if-range] qos wfq cs6 group sp
[Spine1-if-range] qos wfq cs7 group sp
# 对队列6的报文进行流量整形,正常流速为50000000kbps(建议配置为接口带宽的一半)。
[Spine1-if-range] qos gts queue 6 cir 50000000
[Spine1-if-range] quit
![]()
对于S6850-G系列交换机,支持在接口视图配置WRED的各种参数。端口WRED方式可以只配置RoCE队列,不同接口可以配置不同的参数,使用更为灵活。对于支持该功能的产品和版本,推荐采用端口WRED方式。
(5) 配置AI ECN功能(S6850-G仅R8108Pxx及以上版本支持,本功能与静态ECN功能选择一种配置即可)
# 配置RoCEv2流量NetAnalysis功能的工作模式。为了保证能够正确分析RoCEv2流量,当同一个RDMA客户端和服务器端存在多条路径时,建议在客户端和服务器端接入的节点设备上均配置双向模式,在所有的中间节点设备上均配置单向模式。
[Spine1] netanalysis rocev2 mode bidir
This operation will erase all the netanalysis configuration.
Continue?[Y/N]:y
# 开启RoCEv2流量的NetAnalysis统计功能。
[Spine1] netanalysis rocev2 statistics global
# 开启RoCEv2流量的AI ECN功能。
[Spine1] netanalysis rocev2 ai-ecn enable
# 配置AI ECN功能的模式为分布式模式。
[Spine1] ai-service
[Spine1-ai-service] ai ai-ecn enable mode distributed
# 开启队列5、6的AI ECN功能。
[Spine1-ai-service] ai-ecn
[Spine1-ai-service-ai-ecn] queue 5 enable
[Spine1-ai-service-ai-ecn] queue 6 enable
[Spine1-ai-service-ai-ecn] quit
[Spine1-ai-service] quit
(6) 配置PFC功能和PFC死锁检测功能。
# 全局配置5队列的PFC死锁检测周期为10。
[Spine1] priority-flow-control deadlock cos 5 interval 10
# 全局配置PFC死锁检测的精度为high。
[Spine1] priority-flow-control deadlock precision high
# 进入批量接口配置视图,配置与存储网卡对接的接口。
[Spine1] interface range Twenty-FiveGigE 2/0/1 to Twenty-FiveGigE 2/0/8
# 开启与对端自动协商是否开启PFC功能。
[Spine1-if-range] priority-flow-control auto
# 开启指定5队列的PFC功能。
[Spine1-if-range] priority-flow-control no-drop dot1p 5
# 开启接口的PFC死锁检测功能。
[Spine1-if-range] priority-flow-control deadlock enable
# 配置PFC的反压帧触发门限为3500,反压帧停止门限与触发门限间的偏移量为51,Headroom缓存门限为2000,PFC预留门限为30。
[Spine1-if-range] priority-flow-control dot1p 5 headroom 2000
[Spine1-if-range] priority-flow-control dot1p 5 reserved-buffer 30
[Spine1-if-range] priority-flow-control dot1p 5 ingress-buffer static 3500
[Spine1-if-range] priority-flow-control dot1p 5 ingress-threshold-offset 51
[Spine1-if-range] quit
# 进入批量接口配置视图,配置与Leaf对接的接口。
[Spine1] interface range HundredGigE 2/0/49 to HundredGigE 2/0/52
# 开启与对端自动协商是否开启PFC功能。
[Spine1-if-range] priority-flow-control auto
# 开启指定5队列的PFC功能。
[Spine1-if-range] priority-flow-control no-drop dot1p 5
# 开启接口的PFC死锁检测功能。
[Spine1-if-range] priority-flow-control deadlock enable
# 配置PFC的反压帧触发门限为4000,反压帧停止门限与触发门限间的偏移量为51,Headroom缓存门限为3000,PFC预留门限为30。
[Spine1-if-range] priority-flow-control dot1p 5 headroom 3000
[Spine1-if-range] priority-flow-control dot1p 5 reserved-buffer 30
[Spine1-if-range] priority-flow-control dot1p 5 ingress-buffer static 4000
[Spine1-if-range] priority-flow-control dot1p 5 ingress-threshold-offset 51
[Spine1-if-range] quit
(7) 配置iNOF功能
# 全局使能iNOF功能,并进入iNOF视图。
[Spine1] inof enable
# 将允许相互访问的iNOF主机加入到相同域中
[Spine1-inof] zone H1toS1
[Spine1-inof-zone-H1toS1] host 100.1.1.1
[Spine1-inof-zone-H1toS1] host 101.1.1.1
[Spine1-inof-zone-H1toS1] host 100.1.1.2
[Spine1-inof-zone-H1toS1] host 101.1.1.2
[Spine1-inof-zone-H1toS1] quit
[Spine1-inof] zone H2toS1
[Spine1-inof-zone-H2toS1] host 100.1.1.3
[Spine1-inof-zone-H2toS1] host 101.1.1.1
[Spine1-inof-zone-H2toS1] host 100.1.1.4
[Spine1-inof-zone-H2toS1] host 101.1.1.2
[Spine1-inof-zone-H2toS1] quit
[Spine1-inof] quit
(1) 全局使能LLDP功能
# 全局使能LLDP功能。
<Spine2> system-view
[Spine2] lldp global enable
(2) VLAN和接口配置
# 创建VLAN。
[Spine2] vlan 201
[Spine2-vlan201] quit
# 创建vlan虚接口。
[Spine2] interface Vlan-interface 201
# 配置vlan虚接口地址,作为业务服务器RDMA网卡接口的网关。
[Spine2-Vlan-interface101] ip address 201.1.1.254 24
# 配置vlan虚接口mac地址。
[Spine2-Vlan-interface101] mac-address 0000-5e00-0001
[Spine2-Vlan-interface101] quit
# 进入批量接口配置视图,配置与存储网卡对接的接口。
[Spine2] interface range Twenty-FiveGigE 2/0/1 to Twenty-FiveGigE 2/0/8
# 将接口的链路类型修改为trunk。
[Spine2-if-range] port link-type trunk
# 禁止vlan 1通过这些trunk接口。
[Spine2-if-range] undo port trunk permit vlan 1
# 允许vlan 201通过这些trunk接口。
[Spine2-if-range] port trunk permit vlan 201
# 配置为stp edge-port。
[Spine2-if-range] stp edged-port
# 允许lldp发布dot1-tlv的tlv类型。
[Spine2-if-range] lldp tlv-enable dot1-tlv dcbx
# 端口信任802.1p优先级。
[Spine2-if-range] qos trust dot1p
[Spine2-if-range] quit
# 进入批量接口配置视图,配置与Leaf对接的接口。
[Spine2] interface range HundredGigE 2/0/49 to HundredGigE 2/0/52
# 将以太接口切换为三层工作模式。
[Spine2-if-range] port link-mode route
The configuration of the interface will be restored to the default. Continue? [Y
/N]:y
# 端口信任DSCP优先级。
[Spine2-if-range] qos trust dscp
[Spine2-if-range] quit
# 配置接口IP地址。
[Spine2] interface HundredGigE 2/0/49
[Spine2-HundredGigE2/0/49] ip address 172.16.25.2 30
[Spine2-HundredGigE2/0/49] quit
[Spine2] interface HundredGigE 2/0/50
[Spine2-HundredGigE2/0/50] ip address 172.16.25.6 30
[Spine2-HundredGigE2/0/50] quit
其它接口配置方法类似,后略。
(3) 配置BGP路由协议。
# 创建接口LoopBack 0。
[Spine2] interface LoopBack 0
# 配置LoopBack 0的IP,作为全局的Router ID
[Spine2-LoopBack0] ip address 92.1.1.2 32
[Spine2-LoopBack0] quit
# 配置全局Router ID
[Spine2] router-id 92.1.1.2
# 启动BGP实例default,指定该BGP实例的本地AS号,并进入BGP实例视图
[Spine2-bgp-default] bgp 65513
# 配置BGP的Router ID
[Spine2-bgp-default] router-id 92.1.1.2
# 将Leaf设备添加为对等体
[Spine2-bgp-default] peer 172.16.25.1 as-number 65513
[Spine2-bgp-default] peer 172.16.25.5 as-number 65513
…
# 进入BGP ipv4单播地址族视图
[Spine2-bgp-default] address-family ipv4 unicast
# 配置进行BGP负载分担的路由条数为16
[Spine2-bgp-default-ipv4] balance 16
# 发布Loopback0接口地址的路由。
[Spine2-bgp-default-ipv4] network 92.1.1.2 255.255.255.255
# 发布存储网卡接入网段的路由。
[Spine2-bgp-default-ipv4] network 201.1.1.0 255.255.255.0
# 发布与Leaf互联接口的网段路由
[Spine2-bgp-default-ipv4] network 172.16.25.0 255.255.255.252
[Spine2-bgp-default-ipv4] network 172.16.25.4 255.255.255.252
…
# 允许本地路由器与对等体交换路由信息,配置对等体为路由反射器的客户机。
[Spine2-bgp-default-ipv4] peer 172.16.25.1 enable
[Spine2-bgp-default-ipv4] peer 172.16.25.5 enable
[Spine2-bgp-default-ipv4] peer 172.16.25.1 reflect-client
[Spine2-bgp-default-ipv4] peer 172.16.25.5 reflect-client
…
[Spine2-bgp-default-ipv4] quit
# 进入BGP iNOF地址族视图。
[Spine2-bgp-default] address-family inof
# 配置Spine角色为反射器。
[Spine2-bgp-default-inof] role reflector
# 允许本地路由器与对等体交换路由信息,配置对等体为路由反射器的客户机。
[Spine2-bgp-default-inof] peer 172.16.25.1 enable
[Spine2-bgp-default-inof] peer 172.16.25.5 enable
[Spine2-bgp-default-inof] peer 172.16.25.1 reflect-client
[Spine2-bgp-default-inof] peer 172.16.25.5 reflect-client
…
[Spine2-bgp-default-inof]quit
[Spine2-bgp-default]quit
![]()
使用EBGP作为传递iNOF信息的路由协议时,iNOF地址族不需要配置role reflector,IPv4和iNOF地址族不需要配置peer {ipv4-address | ipv6-address } reflect-client。
(4) 配置静态ECN功能(本功能与AI ECN功能选择一种配置即可)
# 配置队列5和队列6最多可使用的共享区域的大小为100%。队列5为RDMA应用报文队列,队列6为CNP报文所在队列。
[Spine2] buffer egress cell queue 5 shared ratio 100
[Spine2] buffer egress cell queue 6 shared ratio 100
[Spine2] buffer apply
# 全局使能ECN拥塞标记功能。
[Spine2] qos wred ecn enable
# 进入批量接口配置视图,配置与存储网卡对接的接口。
[Spine2] interface range Twenty-FiveGigE 2/0/1 to Twenty-FiveGigE 2/0/8
# 配置队列5的WRED平均长度的下限为500,平均长度的上限为1200,丢弃概率为20%。
[Spine2-if-range] qos wred queue 5 low-limit 500 high-limit 1200 discard-probability 20
# 开启接口的WFQ队列,并按照每次轮询可发送的报文的字节数进行计算,配置队列5具有较高调度权重60,队列6、7采用严格优先级调度。
[Spine2-if-range] qos wfq byte-count
[Spine2-if-range] qos wfq ef group 1 byte-count 60
[Spine2-if-range] qos wfq cs6 group sp
[Spine2-if-range] qos wfq cs7 group sp
# 对队列6的报文进行流量整形,正常流速为12500000kbps(建议配置为接口带宽的一半)。
[Spine2-if-range] qos gts queue 6 cir 12500000
[Spine2-if-range] quit
# 进入批量接口配置视图,配置与Leaf对接的接口。
[Spine2] interface range HundredGigE 2/0/49 to HundredGigE 2/0/52
# 配置队列5的WRED平均长度的下限为600,平均长度的上限为2000,丢弃概率为20%。
[Spine2-if-range] qos wred queue 5 low-limit 600 high-limit 2000 discard-probability 20
# 开启接口的WFQ队列,并按照每次轮询可发送的报文的字节数进行计算,配置队列5具有较高调度权重60,队列6、7采用严格优先级调度。
[Spine2-if-range] qos wfq byte-count
[Spine2-if-range] qos wfq ef group 1 byte-count 60
[Spine2-if-range] qos wfq cs6 group sp
[Spine2-if-range] qos wfq cs7 group sp
# 对队列6的报文进行流量整形,正常流速为50000000kbps(建议配置为接口带宽的一半)。
[Spine2-if-range] qos gts queue 6 cir 50000000
[Spine2-if-range] quit
![]()
对于S6850-G系列交换机,支持在接口视图配置WRED的各种参数。端口WRED方式可以只配置RoCE队列,不同接口可以配置不同的参数,使用更为灵活。对于支持该功能的产品和版本,推荐采用端口WRED方式。
(5) 配置AI ECN功能(S6850-G仅R8108Pxx及以上版本支持,本功能与静态ECN功能选择一种配置即可)
# 配置RoCEv2流量NetAnalysis功能的工作模式。为了保证能够正确分析RoCEv2流量,当同一个RDMA客户端和服务器端存在多条路径时,建议在客户端和服务器端接入的节点设备上均配置双向模式,在所有的中间节点设备上均配置单向模式。
[Spine2] netanalysis rocev2 mode bidir
This operation will erase all the netanalysis configuration.
Continue?[Y/N]:y
# 开启RoCEv2流量的NetAnalysis统计功能。
[Spine2] netanalysis rocev2 statistics global
# 开启RoCEv2流量的AI ECN功能。
[Spine2] netanalysis rocev2 ai-ecn enable
# 配置AI ECN功能的模式为分布式模式。
[Spine2] ai-service
[Spine2-ai-service] ai ai-ecn enable mode distributed
# 开启队列5、6的AI ECN功能。
[Spine2-ai-service] ai-ecn
[Spine2-ai-service-ai-ecn] queue 5 enable
[Spine2-ai-service-ai-ecn] queue 6 enable
[Spine2-ai-service-ai-ecn] quit
[Spine2-ai-service] quit
(6) 配置PFC功能和PFC死锁检测功能。
# 全局配置5队列的PFC死锁检测周期为10。
[Spine2] priority-flow-control deadlock cos 5 interval 10
# 全局配置PFC死锁检测的精度为high。
[Spine2] priority-flow-control deadlock precision high
# 进入批量接口配置视图,配置与存储网卡对接的接口。
[Spine2] interface range Twenty-FiveGigE 2/0/1 to Twenty-FiveGigE 2/0/8
# 开启与对端自动协商是否开启PFC功能。
[Spine2-if-range] priority-flow-control auto
# 开启指定5队列的PFC功能。
[Spine2-if-range] priority-flow-control no-drop dot1p 5
# 开启接口的PFC死锁检测功能。
[Spine2-if-range] priority-flow-control deadlock enable
# 配置PFC的反压帧触发门限为3500,反压帧停止门限与触发门限间的偏移量为51,Headroom缓存门限为2000,PFC预留门限为30。
[Spine2-if-range] priority-flow-control dot1p 5 headroom 2000
[Spine2-if-range] priority-flow-control dot1p 5 reserved-buffer 30
[Spine2-if-range] priority-flow-control dot1p 5 ingress-buffer static 3500
[Spine2-if-range] priority-flow-control dot1p 5 ingress-threshold-offset 51
[Spine2-if-range] quit
# 进入批量接口配置视图,配置与Leaf对接的接口。
[Spine2] interface range HundredGigE 2/0/49 to HundredGigE 2/0/52
# 开启与对端自动协商是否开启PFC功能。
[Spine2-if-range] priority-flow-control auto
# 开启指定5队列的PFC功能。
[Spine2-if-range] priority-flow-control no-drop dot1p 5
# 开启接口的PFC死锁检测功能。
[Spine2-if-range] priority-flow-control deadlock enable
# 配置PFC的反压帧触发门限为4000,反压帧停止门限与触发门限间的偏移量为51,Headroom缓存门限为3000,PFC预留门限为30。
[Spine2-if-range] priority-flow-control dot1p 5 headroom 3000
[Spine2-if-range] priority-flow-control dot1p 5 reserved-buffer 30
[Spine2-if-range] priority-flow-control dot1p 5 ingress-buffer static 4000
[Spine2-if-range] priority-flow-control dot1p 5 ingress-threshold-offset 51
[Spine2-if-range] quit
(7) 配置iNOF功能
# 全局使能iNOF功能,并进入iNOF视图。
[Spine2] inof enable
# 将允许相互访问的iNOF主机加入到相同域中
[Spine2-inof] zone H1toS1
[Spine2-inof-zone-H1toS1] host 100.1.1.1
[Spine2-inof-zone-H1toS1] host 101.1.1.1
[Spine2-inof-zone-H1toS1] host 100.1.1.2
[Spine2-inof-zone-H1toS1] host 101.1.1.2
[Spine2-inof-zone-H1toS1] quit
[Spine2-inof] zone H2toS1
[Spine2-inof-zone-H2toS1] host 100.1.1.3
[Spine2-inof-zone-H2toS1] host 101.1.1.1
[Spine2-inof-zone-H2toS1] host 100.1.1.4
[Spine2-inof-zone-H2toS1] host 101.1.1.2
[Spine2-inof-zone-H2toS1] quit
[Spine2-inof] quit
· 查看接口WRED参数(ECN水线)配置
display qos wred interface
· 查看接口的PFC信息
display priority-flow-control interface
· 查看设备所有接口丢包计数、ECN拥塞标记计数的汇总信息
display packet-drop summary
· 查看接口丢包计数、ECN拥塞标记计数等信息
display packet-drop interface
· 查看iNOF域的相关信息
display inof configuration zone
· 查看iNOF网络中接入主机的信息
display inof information host
以二层框盒组网为例,集中式存储的RoCE高性能存储网络典型组网如下图所示。
本节以每个平面使用Leaf-Spine的两层组网为例,Leaf使用S6850-G系列盒式交换机,Spine使用S12500G-AF系列框式交换机。
在该组网中,服务器和存储均采用VLAN接入,使用25G带宽链路,分别接入到两个平面的交换机;Leaf和Spine之间采用路由口互联,使用多条100G带宽链路,形成等价路由。
存储、存储服务器和交换机均支持iNOF(Intelligent Lossless NVMe Over Fabric,智能无损存储网络),从而可以快速感知网络服务器和磁盘设备的加入和离开。
本组网中要求实现RDMA应用报文使用队列5进行无损传输。
![]()
本文以一个平面1台Leaf设备示例,实际组网时一个平面可能存在多台Leaf,各Leaf设备的配置相似,此处不再一一列出。
图5-4 集中式存储典型组网
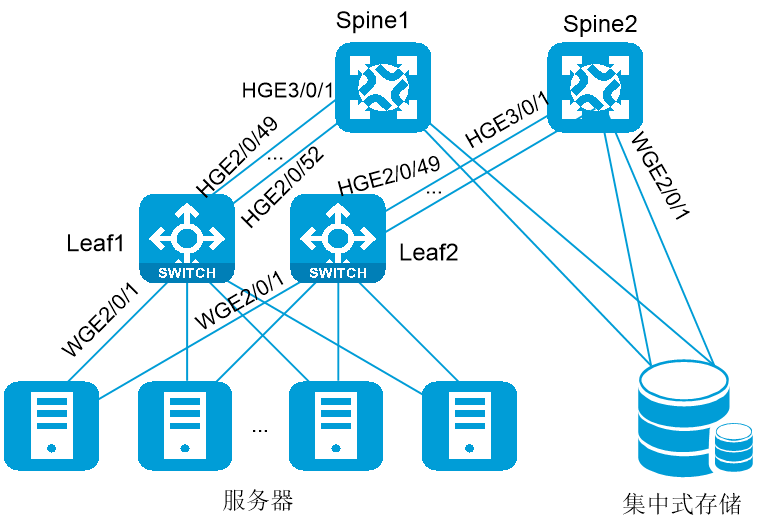
表5-3 服务器/存储接入口IP规划
|
设备 |
接口 |
IP地址/VLAN |
设备 |
接口 |
IP地址/VLAN |
|
Leaf1 |
WGE2/0/1 |
100 |
Leaf2 |
WGE2/0/1 |
200 |
|
… |
100 |
… |
200 |
||
|
WGE2/0/8 |
100 |
WGE2/0/8 |
200 |
||
|
Vlan-int100 |
100.1.1.254/24 |
Vlan-int201 |
200.1.1.254/24 |
||
|
LoopBack 0 |
91.1.1.1/32 |
LoopBack 0 |
91.1.1.2/32 |
||
|
Spine1 |
WGE2/0/1 |
101 |
Spine2 |
WGE2/0/1 |
201 |
|
… |
101 |
… |
201 |
||
|
WGE2/0/8 |
101 |
WGE2/0/8 |
201 |
||
|
Vlan-int101 |
101.1.1.254/24 |
Vlan-int200 |
201.1.1.254/24 |
||
|
LoopBack 0 |
92.1.1.1/32 |
LoopBack 0 |
92.1.1.2/32 |
表5-4 Leaf-Spine互联接口IP规划
|
设备 |
接口 |
IP地址/VLAN |
设备 |
接口 |
IP地址/VLAN |
|
Leaf1 |
HGE2/0/49 |
172.16.24.1/30 |
Spine1 |
HGE3/0/1 |
172.16.24.2/30 |
|
HGE2/0/50 |
172.16.24.5/30 |
HGE3/0/2 |
172.16.24.6/30 |
||
|
HGE2/0/52 |
172.16.24.9/30 |
HGE3/0/3 |
172.16.24.10/30 |
||
|
HGE2/0/52 |
172.16.24.13/30 |
HGE3/0/4 |
172.16.24.14/30 |
||
|
Leaf2 |
HGE2/0/49 |
172.16.25.1/30 |
Spine2 |
HGE3/0/1 |
172.16.25.2/30 |
|
HGE2/0/50 |
172.16.25.5/30 |
HGE3/0/2 |
172.16.25.6/30 |
||
|
HGE2/0/51 |
172.16.25.9/30 |
HGE3/0/3 |
172.16.25.10/30 |
||
|
HGE2/0/52 |
172.16.25.13/30 |
HGE3/0/4 |
172.16.25.14/30 |
![]()
· Leaf上服务器接入口的配置相似,配置仅以少量接口为例。
· Spine上存储接入口的配置相似,配置仅以少量接口为例。
· Leaf与Spine之间互联接口的配置相似,配置仅以少量接口为例。
· 本文以一个平面1台Leaf设备示例,实际组网时一个平面可能存在多台Leaf,各Leaf设备的配置相似,此处不再一一列出。
每个平面采用Leaf-Spine的两层组网形式。
使用IBGP作为路由互通协议:
· 通过BGP的IPv4地址族进行RDMA业务转发,发布Loopback口的地址(也作为router-id)、Leaf与Spine互联接口的网段、服务器/存储接入口的网段。
· 通过BGP的iNOF地址族传递存储、服务器的iNOF信息,Spine配置为路由反射器。
· 存储和服务器配置网关或路由,保证相互路由可达。
![]()
请按照业务需求和组网规模选择合适的路由协议,使用iNOF功能时,必须配置BGP的iNOF地址族用于iNOF信息传递,RDMA业务流量使用的路由协议没有限制。
为实现RDMA应用报文的无损传输,我们需要部署PFC功能和ECN功能:
· PFC功能基于优先级队列对报文进行流量控制。RDMA报文携带802.1P优先级5,我们对802.1P优先级为5的报文开启PFC功能。
RDMA报文转发路径的所有端口都需要配置PFC功能。
· ECN功能提供端到端的拥塞控制。设备检测到拥塞后,对报文的ECN域进行标记。接收端收到ECN标记的报文后,向发送端发送拥塞通知报文,使发送端降低流量发送速率。ECN分为手工指定WRED参数来实现的静态ECN,和AI组件实现的AI ECN功能:
¡ 如果配置静态ECN功能,则在本例中,我们在报文转发路径的所有端口均开启ECN功能。ECN功能配置的high-limit值(queue queue-id [ drop-level drop-level ] low-limit low-limit high-limit high-limit [ discard-probability discard-prob ])需要小于PFC反压帧触发门限值,以使ECN功能先生效。
¡ 如果Spine设备与Leaf设备都支持AI ECN功能,则可以开启指定队列的AI ECN功能。在智能无损网络中配置AI ECN功能时,需要先配置RoCEv2流量NetAnalysis功能,由NetAnalysis技术对现网的流量特征进行深度分析。关键配置包括:
- 使用netanalysis rocev2 mode命令配置RoCEv2流量NetAnalysis功能的工作模式;
- 使用netanalysis rocev2 statistics命令开启RoCEv2流量的NetAnalysis统计功能;
- 使用netanalysis rocev2 ai-ecn enable命令开启RoCEv2流量的AI ECN功能。
PFC和ECN参数请参考推荐值(国产芯片设备S12500G-AF/S12500CR/S6850-G)。
Leaf和Spine均使能iNOF,与存储、服务器互联的接口需要使能lldp和dcbx等功能。
需要在Spine上配置iNOF zone,并按照规划将存储、服务器的ip添加到相应的iNOF zone中以用于访问控制。
请确认存储及服务器的软件支持SNSD功能并配置正确,否则服务器和存储不能通过iNOF信息自动建立链接,也会导致存储网络的iNOF快速感知功能失效。
本文仅涉及交换机配置,存储以及存储服务器的配置,请以使用产品的资料为准。
静态ECN功能与AIECN功能选择一种配置即可。如果Spine设备与Leaf设备都支持AI ECN功能,则建议配置AI ECN功能。
AI ECN功能受License限制,请在使用本功能前安装有效的License。有关License的详细介绍,请参见“基础配置指导”中的“License管理”。
配置PFC功能时,必须配置接口信任报文自带的802.1p优先级或DSCP优先级(qos trust { dot1p | dscp }),并且转发路径上所有端口的802.1p优先级与本地优先级映射关系以及DSCP优先级与802.1p优先级映射关系必须一致,否则PFC功能将无法正常工作。对于本组网中的二层接口,建议配置接口信任报文自带的802.1p优先级(qos trust dot1p),对于三层接口,建议配置接口信任报文自带的DSCP优先级(qos trust dscp)。
对于接收到的以太网报文,设备将根据优先级信任模式和报文的802.1Q标签状态,设备将采用不同的方式为其标记调度优先级。当设备连接不同网络时,所有进入设备的报文,其外部优先级字段(包括DSCP和IP)都被映射为802.1p优先级,再根据802.1p优先级映射为内部优先级;设备根据内部优先级进行队列调度的QoS处理。
关于优先级映射的详细介绍,请参见产品配套的“ACL和QoS配置指导”中的“优先级映射”。
(1) 全局使能LLDP功能
# 全局使能LLDP功能。
<Leaf1> system-view
[Leaf1] lldp global enable
(2) VLAN和接口配置
# 创建VLAN。
[Leaf1] vlan 100
[Leaf1-vlan100] quit
# 创建vlan虚接口。
[Leaf1] interface Vlan-interface 100
# 配置vlan虚接口地址,作为业务服务器RDMA网卡接口的网关。
[Leaf1-Vlan-interface100] ip address 100.1.1.254 24
# 配置vlan虚接口mac地址。
[Leaf1-Vlan-interface100] mac-address 0000-5e00-0001
[Leaf1-Vlan-interface100] quit
# 进入批量接口配置视图,配置与业务服务器网卡对接的接口。
[Leaf1] interface range Twenty-FiveGigE 2/0/1 to Twenty-FiveGigE 2/0/8
# 将接口的链路类型修改为trunk。
[Leaf1-if-range] port link-type trunk
# 禁止vlan 1通过这些trunk接口。
[Leaf1-if-range] undo port trunk permit vlan 1
# 允许vlan 100通过这些trunk接口。
[Leaf1-if-range] port trunk permit vlan 100
# 配置为stp edge-port。
[Leaf1-if-range] stp edged-port
# 允许lldp发布dot1-tlv的tlv类型。
[Leaf1-if-range] lldp tlv-enable dot1-tlv dcbx
# 端口信任802.1p优先级。
[Leaf1-if-range] qos trust dot1p
[Leaf1-if-range] quit
# 进入批量接口配置视图,配置与Spine对接的接口。
[Leaf1] interface range HundredGigE 2/0/49 to HundredGigE 2/0/52
# 将以太接口切换为三层工作模式。
[Leaf1-if-range] port link-mode route
The configuration of the interface will be restored to the default. Continue? [Y
/N]:y
# 端口信任DSCP优先级。
[Leaf1-if-range] qos trust dscp
[Leaf1-if-range] quit
# 配置接口IP地址。
[Leaf1] interface HundredGigE 2/0/49
[Leaf1-HundredGigE2/0/49] ip address 172.16.24.1 30
[Leaf1-HundredGigE2/0/49] quit
[Leaf1] interface HundredGigE 2/0/50
[Leaf1-HundredGigE2/0/50] ip address 172.16.24.5 30
[Leaf1-HundredGigE2/0/50] quit
其它接口配置方法类似,后略。
(3) 配置BGP路由协议。
# 创建接口LoopBack 0。
[Leaf1] interface LoopBack 0
# 配置LoopBack 0的ip,作为全局的Router ID
[Leaf1-LoopBack0] ip address 91.1.1.1 32
[Leaf1-LoopBack0] quit
# 配置全局Router ID
[Leaf1] router-id 91.1.1.1
# 启动BGP实例default,指定该BGP实例的本地AS号,并进入BGP实例视图
[Leaf1-bgp-default] bgp 65512
# 配置BGP的Router ID
[Leaf1-bgp-default] router-id 91.1.1.1
# 将Spine设备添加为对等体
[Leaf1-bgp-default] peer 172.16.24.2 as-number 65512
[Leaf1-bgp-default] peer 172.16.24.6 as-number 65512
…
# 进入BGP ipv4单播地址族视图
[Leaf1-bgp-default] address-family ipv4 unicast
# 配置进行BGP负载分担的路由条数为16
[Leaf1-bgp-default-ipv4] balance 16
# 发布Loopback0接口地址的路由
[Leaf1-bgp-default-ipv4] network 91.1.1.1 255.255.255.255
# 发布业务服务器接入网段的路由
[Leaf1-bgp-default-ipv4] network 100.1.1.0 255.255.255.0
# 发布与Spine互联接口的网段路由
[Leaf1-bgp-default-ipv4] network 172.16.24.0 255.255.255.252
[Leaf1-bgp-default-ipv4] network 172.16.24.4 255.255.255.252
…
# 允许本地路由器与对等体交换路由信息
[Leaf1-bgp-default-ipv4] peer 172.16.24.2 enable
[Leaf1-bgp-default-ipv4] peer 172.16.24.6 enable
…
[Leaf1-bgp-default-ipv4] quit
# 进入BGP iNOF地址族视图
[Leaf1-bgp-default] address-family inof
# 配置Leaf角色为客户机
[Leaf1-bgp-default-inof] role reflect-client
# 允许本地路由器与对等体交换路由信息
[Leaf1-bgp-default-inof] peer 172.16.24.2 enable
[Leaf1-bgp-default-inof] peer 172.16.24.6 enable
…
[Leaf1-bgp-default-inof]quit
[Leaf1-bgp-default]quit
(4) 配置静态ECN功能(本功能与AI ECN功能选择一种配置即可)
# 配置队列5和队列6最多可使用的共享区域的大小为100%。队列5为RDMA应用报文队列,队列6为CNP报文所在队列。
[Leaf1] buffer egress cell queue 5 shared ratio 100
[Leaf1] buffer egress cell queue 6 shared ratio 100
[Leaf1] buffer apply
# 全局使能ECN拥塞标记功能。
[Leaf1] qos wred ecn enable
# 进入批量接口配置视图,配置与业务服务器网卡对接的接口。
[Leaf1] interface range Twenty-FiveGigE 2/0/1 to Twenty-FiveGigE 2/0/8
# 配置队列5的WRED平均长度的下限为500,平均长度的上限为1200,丢弃概率为20%。
[Leaf1-if-range] qos wred queue 5 low-limit 500 high-limit 1200 discard-probability 20
# 开启接口的WFQ队列,并按照每次轮询可发送的报文的字节数进行计算,配置队列5具有较高调度权重60,队列6、7采用严格优先级调度。
[Leaf1-if-range] qos wfq byte-count
[Leaf1-if-range] qos wfq ef group 1 byte-count 60
[Leaf1-if-range] qos wfq cs6 group sp
[Leaf1-if-range] qos wfq cs7 group sp
# 对队列6的报文进行流量整形,正常流速为12500000kbps(建议配置为接口带宽的一半)。
[Leaf1-if-range] qos gts queue 6 cir 12500000
[Leaf1-if-range] quit
# 进入批量接口配置视图,配置与Spine对接的接口。
[Leaf1] interface range HundredGigE 2/0/49 to HundredGigE 2/0/52
# 配置队列5的WRED平均长度的下限为600,平均长度的上限为2000,丢弃概率为20%。
[Leaf1-if-range] qos wred queue 5 low-limit 600 high-limit 2000 discard-probability 20
# 开启接口的WFQ队列,并按照每次轮询可发送的报文的字节数进行计算,配置队列5具有较高调度权重60,队列6、7采用严格优先级调度。
[Leaf1-if-range] qos wfq byte-count
[Leaf1-if-range] qos wfq ef group 1 byte-count 60
[Leaf1-if-range] qos wfq cs6 group sp
[Leaf1-if-range] qos wfq cs7 group sp
# 对队列6的报文进行流量整形,正常流速为50000000kbps(建议配置为接口带宽的一半)。
[Leaf1-if-range] qos gts queue 6 cir 50000000
[Leaf1-if-range] quit
![]()
对于S12500G-AF/S6850-G系列交换机,支持在接口视图配置WRED的各种参数。端口WRED方式可以只配置RoCE队列,不同接口可以配置不同的参数,使用更为灵活。对于支持该功能的产品和版本,推荐采用端口WRED方式。
(5) 配置AI ECN功能(S6850-G仅R8108Pxx及以上版本支持,本功能与静态ECN功能选择一种配置即可)
# 配置RoCEv2流量NetAnalysis功能的工作模式。为了保证能够正确分析RoCEv2流量,当同一个RDMA客户端和服务器端存在多条路径时,建议在客户端和服务器端接入的节点设备上均配置双向模式,在所有的中间节点设备上均配置单向模式。
[Leaf1] netanalysis rocev2 mode bidir
This operation will erase all the netanalysis configuration.
Continue?[Y/N]:y
# 开启RoCEv2流量的NetAnalysis统计功能。
[Leaf1] netanalysis rocev2 statistics global
# 开启RoCEv2流量的AI ECN功能。
[Leaf1] netanalysis rocev2 ai-ecn enable
# 加载AI模型文件。指定的模型文件必须已经被保存在设备的存储空间上,有关AI模型文件,请联系技术支持获取。
[Leaf1] ai-service
[Leaf1-ai-service] model load flash:/ai-ecn.cambricon
# 配置AI ECN功能的模式为分布式模式。
[Leaf1-ai-service] ai ai-ecn enable mode distributed
# 开启队列5、6的AI ECN功能。
[Leaf1-ai-service] ai-ecn
[Leaf1-ai-service-ai-ecn] queue 5 enable
[Leaf1-ai-service-ai-ecn] queue 6 enable
[Leaf1-ai-service-ai-ecn] quit
[Leaf1-ai-service] quit
(6) 配置PFC功能和PFC死锁检测功能。
# 全局配置5队列的PFC死锁检测周期为10。
[Leaf1] priority-flow-control deadlock cos 5 interval 10
# 全局配置PFC死锁检测的精度为high。
[Leaf1] priority-flow-control deadlock precision high
# 进入批量接口配置视图,配置与业务服务器网卡对接的接口。
[Leaf1] interface range Twenty-FiveGigE 2/0/1 to Twenty-FiveGigE 2/0/8
# 开启与对端自动协商是否开启PFC功能。
[Leaf1-if-range] priority-flow-control auto
# 开启指定5队列的PFC功能。
[Leaf1-if-range] priority-flow-control no-drop dot1p 5
# 开启接口的PFC死锁检测功能。
[Leaf1-if-range] priority-flow-control deadlock enable
# 配置PFC的反压帧触发门限为3500,反压帧停止门限与触发门限间的偏移量为51,Headroom缓存门限为2000,PFC预留门限为30。
[Leaf1-if-range] priority-flow-control dot1p 5 headroom 2000
[Leaf1-if-range] priority-flow-control dot1p 5 reserved-buffer 30
[Leaf1-if-range] priority-flow-control dot1p 5 ingress-buffer static 3500
[Leaf1-if-range] priority-flow-control dot1p 5 ingress-threshold-offset 51
[Leaf1-if-range] quit
# 进入批量接口配置视图,配置与Spine对接的接口。
[Leaf1] interface range HundredGigE 3/0/1 to HundredGigE 3/0/4
# 开启与对端自动协商是否开启PFC功能。
[Leaf1-if-range] priority-flow-control auto
# 开启指定5队列的PFC功能。
[Leaf1-if-range] priority-flow-control no-drop dot1p 5
# 开启接口的PFC死锁检测功能。
[Leaf1-if-range] priority-flow-control deadlock enable
# 配置PFC的反压帧触发门限为4000,反压帧停止门限与触发门限间的偏移量为51,Headroom缓存门限为3000,PFC预留门限为30。
[Leaf1-if-range] priority-flow-control dot1p 5 headroom 3000
[Leaf1-if-range] priority-flow-control dot1p 5 reserved-buffer 30
[Leaf1-if-range] priority-flow-control dot1p 5 ingress-buffer static 4000
[Leaf1-if-range] priority-flow-control dot1p 5 ingress-threshold-offset 51
[Leaf1-if-range] quit
(7) 配置iNOF功能
# 全局使能iNOF功能,并进入iNOF视图。
[Leaf1] inof enable
[Leaf1-inof] quit
(1) 全局使能LLDP功能
# 全局使能LLDP功能。
<Leaf2> system-view
[Leaf2] lldp global enable
(2) VLAN和接口配置
# 创建VLAN。
[Leaf2] vlan 200
[Leaf2-vlan200] quit
# 创建vlan虚接口。
[Leaf2] interface Vlan-interface 200
# 配置vlan虚接口地址,作为业务服务器RDMA网卡接口的网关。
[Leaf2-Vlan-interface200] ip address 200.1.1.254 24
# 配置vlan虚接口mac地址。
[Leaf2-Vlan-interface200] mac-address 0000-5e00-0001
[Leaf2-Vlan-interface200] quit
# 进入批量接口配置视图,配置与业务服务器网卡对接的接口。
[Leaf2] interface range Twenty-FiveGigE 2/0/1 to Twenty-FiveGigE 2/0/8
# 将接口的链路类型修改为trunk。
[Leaf2-if-range] port link-type trunk
# 禁止vlan 1通过这些trunk接口。
[Leaf2-if-range] undo port trunk permit vlan 1
# 允许vlan 200通过这些trunk接口。
[Leaf2-if-range] port trunk permit vlan 200
# 配置为stp edge-port。
[Leaf2-if-range] stp edged-port
# 允许lldp发布dot1-tlv的tlv类型。
[Leaf2-if-range] lldp tlv-enable dot1-tlv dcbx
# 端口信任802.1p优先级。
[Leaf2-if-range] qos trust dot1p
[Leaf2-if-range] quit
# 进入批量接口配置视图,配置与Spine对接的接口。
[Leaf2] interface range HundredGigE 2/0/49 to HundredGigE 2/0/52
# 将以太接口切换为三层工作模式。
[Leaf2-if-range] port link-mode route
The configuration of the interface will be restored to the default. Continue? [Y
/N]:y
# 端口信任DSCP优先级。
[Leaf2-if-range] qos trust dscp
[Leaf2-if-range] quit
# 配置接口IP地址。
[Leaf2] interface HundredGigE 2/0/49
[Leaf2-HundredGigE2/0/49] ip address 172.16.25.1 30
[Leaf2-HundredGigE2/0/49] quit
[Leaf2] interface HundredGigE 2/0/50
[Leaf2-HundredGigE2/0/50] ip address 172.16.25.5 30
[Leaf2-HundredGigE2/0/50] quit
其它接口配置方法类似,后略。
(3) 配置BGP路由协议。
# 创建接口LoopBack 0。
[Leaf2] interface LoopBack 0
# 配置LoopBack 0的ip,作为全局的Router ID
[Leaf2-LoopBack0] ip address 91.1.1.2 32
[Leaf2-LoopBack0] quit
# 配置全局Router ID
[Leaf2] router-id 91.1.1.2
# 启动BGP实例default,指定该BGP实例的本地AS号,并进入BGP实例视图
[Leaf2-bgp-default] bgp 65513
# 配置BGP的Router ID
[Leaf2-bgp-default] router-id 91.1.1.2
# 将Spine设备添加为对等体
[Leaf2-bgp-default] peer 172.16.25.2 as-number 65513
[Leaf2-bgp-default] peer 172.16.25.6 as-number 65513
…
# 进入BGP ipv4单播地址族视图
[Leaf2-bgp-default] address-family ipv4 unicast
# 配置进行BGP负载分担的路由条数为16
[Leaf2-bgp-default-ipv4] balance 16
# 发布Loopback0接口地址的路由
[Leaf2-bgp-default-ipv4] network 91.1.1.2 255.255.255.255
# 发布业务服务器接入网段的路由
[Leaf2-bgp-default-ipv4] network 200.1.1.0 255.255.255.0
# 发布与Spine互联接口的网段路由
[Leaf2-bgp-default-ipv4] network 172.16.25.0 255.255.255.252
[Leaf2-bgp-default-ipv4] network 172.16.25.4 255.255.255.252
…
# 允许本地路由器与对等体交换路由信息
[Leaf2-bgp-default-ipv4] peer 172.16.25.2 enable
[Leaf2-bgp-default-ipv4] peer 172.16.25.6 enable
…
[Leaf2-bgp-default-ipv4] quit
# 进入BGP iNOF地址族视图
[Leaf2-bgp-default] address-family inof
# 配置Leaf角色为客户机
[Leaf2-bgp-default-inof] role reflect-client
# 允许本地路由器与对等体交换路由信息
[Leaf2-bgp-default-inof] peer 172.16.24.2 enable
[Leaf2-bgp-default-inof] peer 172.16.24.6 enable
…
[Leaf2-bgp-default-inof]quit
[Leaf2-bgp-default]quit
(4) 配置静态ECN功能(本功能与AI ECN功能选择一种配置即可)
# 配置队列5和队列6最多可使用的共享区域的大小为100%。队列5为RDMA应用报文队列,队列6为CNP报文所在队列。
[Leaf2] buffer egress cell queue 5 shared ratio 100
[Leaf2] buffer egress cell queue 6 shared ratio 100
[Leaf2] buffer apply
# 全局使能ECN拥塞标记功能。
[Leaf2] qos wred ecn enable
# 进入批量接口配置视图,配置与业务服务器网卡对接的接口。
[Leaf2] interface range Twenty-FiveGigE 2/0/1 to Twenty-FiveGigE 2/0/8
# 配置队列5的WRED平均长度的下限为500,平均长度的上限为1200,丢弃概率为20%。
[Leaf2-if-range] qos wred queue 5 low-limit 500 high-limit 1200 discard-probability 20
# 开启接口的WFQ队列,并按照每次轮询可发送的报文的字节数进行计算,配置队列5具有较高调度权重60,队列6、7采用严格优先级调度。
[Leaf2-if-range] qos wfq byte-count
[Leaf2-if-range] qos wfq ef group 1 byte-count 60
[Leaf2-if-range] qos wfq cs6 group sp
[Leaf2-if-range] qos wfq cs7 group sp
# 对队列6的报文进行流量整形,正常流速为12500000kbps(建议配置为接口带宽的一半)。
[Leaf2-if-range] qos gts queue 6 cir 12500000
[Leaf2-if-range] quit
# 进入批量接口配置视图,配置与Spine对接的接口。
[Leaf2] interface range HundredGigE 2/0/49 to HundredGigE 2/0/52
# 配置队列5的WRED平均长度的下限为600,平均长度的上限为2000,丢弃概率为20%。
[Leaf2-if-range] qos wred queue 5 low-limit 600 high-limit 2000 discard-probability 20
# 开启接口的WFQ队列,并按照每次轮询可发送的报文的字节数进行计算,配置队列5具有较高调度权重60,队列6、7采用严格优先级调度。
[Leaf2-if-range] qos wfq byte-count
[Leaf2-if-range] qos wfq ef group 1 byte-count 60
[Leaf2-if-range] qos wfq cs6 group sp
[Leaf2-if-range] qos wfq cs7 group sp
# 对队列6的报文进行流量整形,正常流速为50000000kbps(建议配置为接口带宽的一半)。
[Leaf2-if-range] qos gts queue 6 cir 50000000
[Leaf2-if-range] quit
![]()
对于S12500G-AF/S6850-G系列交换机,支持在接口视图配置WRED的各种参数。端口WRED方式可以只配置RoCE队列,不同接口可以配置不同的参数,使用更为灵活。对于支持该功能的产品和版本,推荐采用端口WRED方式。
(5) 配置AI ECN功能(S6850-G仅R8108Pxx及以上版本支持,本功能与静态ECN功能选择一种配置即可)
# 配置RoCEv2流量NetAnalysis功能的工作模式。为了保证能够正确分析RoCEv2流量,当同一个RDMA客户端和服务器端存在多条路径时,建议在客户端和服务器端接入的节点设备上均配置双向模式,在所有的中间节点设备上均配置单向模式。
[Leaf2] netanalysis rocev2 mode bidir
This operation will erase all the netanalysis configuration.
Continue?[Y/N]:y
# 开启RoCEv2流量的NetAnalysis统计功能。
[Leaf2] netanalysis rocev2 statistics global
# 开启RoCEv2流量的AI ECN功能。
[Leaf2] netanalysis rocev2 ai-ecn enable
# 加载AI模型文件。指定的模型文件必须已经被保存在设备的存储空间上,有关AI模型文件,请联系技术支持获取。
[Leaf2] ai-service
[Leaf2-ai-service] model load flash:/ai-ecn.cambricon
# 配置AI ECN功能的模式为分布式模式。
[Leaf2-ai-service] ai ai-ecn enable mode distributed
# 开启队列5、6的AI ECN功能。
[Leaf2-ai-service] ai-ecn
[Leaf2-ai-service-ai-ecn] queue 5 enable
[Leaf2-ai-service-ai-ecn] queue 6 enable
[Leaf2-ai-service-ai-ecn] quit
[Leaf2-ai-service] quit
(6) 配置PFC功能和PFC死锁检测功能。
# 全局配置5队列的PFC死锁检测周期为10。
[Leaf2] priority-flow-control deadlock cos 5 interval 10
# 全局配置PFC死锁检测的精度为high。
[Leaf2] priority-flow-control deadlock precision high
# 进入批量接口配置视图,配置与业务服务器网卡对接的接口。
[Leaf2] interface range Twenty-FiveGigE 2/0/1 to Twenty-FiveGigE 2/0/8
# 开启与对端自动协商是否开启PFC功能。
[Leaf2-if-range] priority-flow-control auto
# 开启指定5队列的PFC功能。
[Leaf2-if-range] priority-flow-control no-drop dot1p 5
# 开启接口的PFC死锁检测功能。
[Leaf2-if-range] priority-flow-control deadlock enable
# 配置PFC的反压帧触发门限为3500,反压帧停止门限与触发门限间的偏移量为51,Headroom缓存门限为2000,PFC预留门限为30。
[Leaf2-if-range] priority-flow-control dot1p 5 headroom 2000
[Leaf2-if-range] priority-flow-control dot1p 5 reserved-buffer 30
[Leaf2-if-range] priority-flow-control dot1p 5 ingress-buffer static 3500
[Leaf2-if-range] priority-flow-control dot1p 5 ingress-threshold-offset 51
[Leaf2-if-range] quit
# 进入批量接口配置视图,配置与Spine对接的接口。
[Leaf2] interface range HundredGigE 3/0/1 to HundredGigE 3/0/4
# 开启与对端自动协商是否开启PFC功能。
[Leaf2-if-range] priority-flow-control auto
# 开启指定5队列的PFC功能。
[Leaf2-if-range] priority-flow-control no-drop dot1p 5
# 开启接口的PFC死锁检测功能。
[Leaf2-if-range] priority-flow-control deadlock enable
# 配置PFC的反压帧触发门限为4000,反压帧停止门限与触发门限间的偏移量为51,Headroom缓存门限为3000,PFC预留门限为30。
[Leaf2-if-range] priority-flow-control dot1p 5 headroom 3000
[Leaf2-if-range] priority-flow-control dot1p 5 reserved-buffer 30
[Leaf2-if-range] priority-flow-control dot1p 5 ingress-buffer static 4000
[Leaf2-if-range] priority-flow-control dot1p 5 ingress-threshold-offset 51
[Leaf2-if-range] quit
(7) 配置iNOF功能
# 全局使能iNOF功能,并进入iNOF视图。
[Leaf2] inof enable
[Leaf2-inof] quit
(1) 全局使能LLDP功能
# 全局使能LLDP功能。
<Spine1> system-view
[Spine1] lldp global enable
(2) VLAN和接口配置
# 创建VLAN。
[Spine1] vlan 101
[Spine1-vlan101] quit
# 创建vlan虚接口。
[Spine1] interface Vlan-interface 101
# 配置vlan虚接口地址,作为业务服务器RDMA网卡接口的网关。
[Spine1-Vlan-interface101] ip address 101.1.1.254 24
# 配置vlan虚接口mac地址。
[Spine1-Vlan-interface101] mac-address 0000-5e00-0001
[Spine1-Vlan-interface101] quit
# 进入批量接口配置视图,配置与存储网卡对接的接口。
[Spine1] interface range Twenty-FiveGigE 2/0/1 to Twenty-FiveGigE 2/0/8
# 将接口的链路类型修改为trunk。
[Spine1-if-range] port link-type trunk
# 禁止vlan 1通过这些trunk接口。
[Spine1-if-range] undo port trunk permit vlan 1
# 允许vlan 101通过这些trunk接口。
[Spine1-if-range] port trunk permit vlan 101
# 配置为stp edge-port。
[Spine1-if-range] stp edged-port
# 允许lldp发布dot1-tlv的tlv类型。
[Spine1-if-range] lldp tlv-enable dot1-tlv dcbx
# 端口信任802.1p优先级。
[Spine1-if-range] qos trust dot1p
[Spine1-if-range] quit
# 进入批量接口配置视图,配置与Leaf对接的接口。
[Spine1] interface range HundredGigE 3/0/1 to HundredGigE 3/0/4
# 将以太接口切换为三层工作模式。
[Spine1-if-range] port link-mode route
The configuration of the interface will be restored to the default. Continue? [Y
/N]:y
# 端口信任DSCP优先级。
[Spine1-if-range] qos trust dscp
[Spine1-if-range] quit
# 配置接口IP地址。
[Spine1] interface HundredGigE 3/0/1
[Spine1-HundredGigE3/0/1] ip address 172.16.24.2 30
[Spine1-HundredGigE3/0/1] quit
[Spine1] interface HundredGigE 3/0/2
[Spine1-HundredGigE3/0/2] ip address 172.16.24.6 30
[Spine1-HundredGigE3/0/2] quit
其它接口配置方法类似,后略。
(3) 配置BGP路由协议。
# 创建接口LoopBack 0。
[Spine1] interface LoopBack 0
# 配置LoopBack 0的IP,作为全局的Router ID
[Spine1-LoopBack0] ip address 92.1.1.1 32
[Spine1-LoopBack0] quit
# 配置全局Router ID
[Spine1] router-id 92.1.1.1
# 启动BGP实例default,指定该BGP实例的本地AS号,并进入BGP实例视图
[Spine1-bgp-default] bgp 65512
# 配置BGP的Router ID
[Spine1-bgp-default] router-id 92.1.1.1
# 将Leaf设备添加为对等体
[Spine1-bgp-default] peer 172.16.24.1 as-number 65512
[Spine1-bgp-default] peer 172.16.24.5 as-number 65512
…
# 进入BGP ipv4单播地址族视图
[Spine1-bgp-default] address-family ipv4 unicast
# 配置进行BGP负载分担的路由条数为16
[Spine1-bgp-default-ipv4] balance 16
# 发布Loopback0接口地址的路由。
[Spine1-bgp-default-ipv4] network 92.1.1.1 255.255.255.255
# 发布存储网卡接入网段的路由。
[Spine1-bgp-default-ipv4] network 101.1.1.0 255.255.255.0
# 发布与Leaf互联接口的网段路由
[Spine1-bgp-default-ipv4] network 172.16.24.0 255.255.255.252
[Spine1-bgp-default-ipv4] network 172.16.24.4 255.255.255.252
…
# 允许本地路由器与对等体交换路由信息,配置对等体为路由反射器的客户机。
[Spine1-bgp-default-ipv4] peer 172.16.24.1 enable
[Spine1-bgp-default-ipv4] peer 172.16.24.5 enable
[Spine1-bgp-default-ipv4] peer 172.16.24.1 reflect-client
[Spine1-bgp-default-ipv4] peer 172.16.24.5 reflect-client
…
[Spine1-bgp-default-ipv4] quit
# 进入BGP iNOF地址族视图。
[Spine1-bgp-default] address-family inof
# 配置Spine角色为反射器。
[Spine1-bgp-default-inof] role reflector
# 允许本地路由器与对等体交换路由信息,配置对等体为路由反射器的客户机。
[Spine1-bgp-default-inof] peer 172.16.24.1 enable
[Spine1-bgp-default-inof] peer 172.16.24.5 enable
[Spine1-bgp-default-inof] peer 172.16.24.1 reflect-client
[Spine1-bgp-default-inof] peer 172.16.24.5 reflect-client
…
[Spine1-bgp-default-inof]quit
[Spine1-bgp-default]quit
![]()
使用EBGP作为传递iNOF信息的路由协议时,iNOF地址族不需要配置role reflector,IPv4和iNOF地址族不需要配置peer {ipv4-address | ipv6-address } reflect-client。
(4) 配置静态ECN功能(本功能与AI ECN功能选择一种配置即可)
# 配置队列5和队列6最多可使用的共享区域的大小为100%。队列5为RDMA应用报文队列,队列6为CNP报文所在队列。
[Spine1] buffer egress cell queue 5 shared ratio 100
[Spine1] buffer egress cell queue 6 shared ratio 100
[Spine1] buffer apply
# 全局使能ECN拥塞标记功能。
[Spine1] qos wred ecn enable
# 创建WRED表,并进入WRED表视图
[Spine1] qos wred queue table ECN
# 配置WRED参数。注意:使用WRED表配置WRED参数时,推荐将非无损队列参数中的high-limit配置为可配置的最大值,low-limit配置为最大值减1,使其WRED功能和ECN功能实际不生效
[Spine1-wred-table-queue-ECN] queue 0 low-limit 69631 high-limit 69632
[Spine1-wred-table-queue-ECN] queue 1 low-limit 69631 high-limit 69632
[Spine1-wred-table-queue-ECN] queue 2 low-limit 69631 high-limit 69632
[Spine1-wred-table-queue-ECN] queue 3 low-limit 69631 high-limit 69632
[Spine1-wred-table-queue-ECN] queue 4 low-limit 69631 high-limit 69632
[Spine1-wred-table-queue-ECN] queue 6 low-limit 69631 high-limit 69632
[Spine1-wred-table-queue-ECN] queue 7 low-limit 69631 high-limit 69632
[Spine1-wred-table-queue-ECN] queue 5 low-limit 600 high-limit 2000 [Spine1-wred-table-queue-ECN] discard-probability 20
[Spine1-wred-table-queue-ECN] quit
# 设置内联口ECN参数.注意:仅框式设备需要配置
[Spine1] qos wred apply ECN fabric
# 进入批量接口配置视图,配置与存储网卡对接的接口。
[Spine1] interface range Twenty-FiveGigE 2/0/1 to Twenty-FiveGigE 2/0/8
# 配置队列5的WRED平均长度的下限为500,平均长度的上限为1200,丢弃概率为20%。
[Spine1-if-range] qos wred queue 5 low-limit 500 high-limit 1200 discard-probability 20
# 开启接口的WFQ队列,并按照每次轮询可发送的报文的字节数进行计算,配置队列5具有较高调度权重60,队列6、7采用严格优先级调度。
[Spine1-if-range] qos wfq byte-count
[Spine1-if-range] qos wfq ef group 1 byte-count 60
[Spine1-if-range] qos wfq cs6 group sp
[Spine1-if-range] qos wfq cs7 group sp
# 对队列6的报文进行流量整形,正常流速为12500000kbps(建议配置为接口带宽的一半)。
[Spine1-if-range] qos gts queue 6 cir 12500000
[Spine1-if-range] quit
# 进入批量接口配置视图,配置与Leaf对接的接口。
[Spine1] interface range HundredGigE 3/0/1 to HundredGigE 3/0/4
# 配置队列5的WRED平均长度的下限为600,平均长度的上限为2000,丢弃概率为20%。
[Spine1-if-range] qos wred queue 5 low-limit 600 high-limit 2000 discard-probability 20
# 开启接口的WFQ队列,并按照每次轮询可发送的报文的字节数进行计算,配置队列5具有较高调度权重60,队列6、7采用严格优先级调度。
[Spine1-if-range] qos wfq byte-count
[Spine1-if-range] qos wfq ef group 1 byte-count 60
[Spine1-if-range] qos wfq cs6 group sp
[Spine1-if-range] qos wfq cs7 group sp
# 对队列6的报文进行流量整形,正常流速为50000000kbps(建议配置为接口带宽的一半)。
[Spine1-if-range] qos gts queue 6 cir 50000000
[Spine1-if-range] quit
![]()
对于S12500G-AF/S6850-G系列交换机,支持在接口视图配置WRED的各种参数。端口WRED方式可以只配置RoCE队列,不同接口可以配置不同的参数,使用更为灵活。对于支持该功能的产品和版本,推荐采用端口WRED方式。
(5) 配置AI ECN功能(S12500G-AF仅R8053Pxx及以上版本支持,本功能与静态ECN功能选择一种配置即可)
# 配置RoCEv2流量NetAnalysis功能的工作模式。为了保证能够正确分析RoCEv2流量,当同一个RDMA客户端和服务器端存在多条路径时,建议在客户端和服务器端接入的节点设备上均配置双向模式,在所有的中间节点设备上均配置单向模式。
[Spine1] netanalysis rocev2 mode bidir
This operation will erase all the netanalysis configuration.
Continue?[Y/N]:y
# 开启RoCEv2流量的NetAnalysis统计功能。
[Spine1] netanalysis rocev2 statistics global
# 开启RoCEv2流量的AI ECN功能。
[Spine1] netanalysis rocev2 ai-ecn enable
# 配置AI ECN功能的模式为分布式模式。
[Spine1] ai-service
[Spine1-ai-service] ai ai-ecn enable mode distributed
# 开启队列5、6的AI ECN功能。
[Spine1-ai-service] ai-ecn
[Spine1-ai-service-ai-ecn] queue 5 enable
[Spine1-ai-service-ai-ecn] queue 6 enable
[Spine1-ai-service-ai-ecn] quit
[Spine1-ai-service] quit
(6) 配置PFC功能和PFC死锁检测功能。
# 全局配置5队列的PFC死锁检测周期为10。
[Spine1] priority-flow-control deadlock cos 5 interval 10
# 全局配置PFC死锁检测的精度为high。
[Spine1] priority-flow-control deadlock precision high
# 使能内联口队列5的PFC功能。注意:仅框式设备需要配置
[Spine1] priority-flow-control inner-port enable
# 配置内联口的5队列的PFC的反压帧触发门限为4000,反压帧停止门限与触发门限间的偏移量为51,Headroom缓存门限为3000,PFC预留门限为30。注意:仅框式设备需要配置
[Spine1] priority-flow-control inner-port no-drop dot1p 5 ingress-buffer static 4000 ingress-threshold-offset 51 headroom 3000 reserved-buffer 30
# 进入批量接口配置视图,配置与存储网卡对接的接口。
[Spine1] interface range Twenty-FiveGigE 2/0/1 to Twenty-FiveGigE 2/0/8
# 开启与对端自动协商是否开启PFC功能。
[Spine1-if-range] priority-flow-control auto
# 开启指定5队列的PFC功能。
[Spine1-if-range] priority-flow-control no-drop dot1p 5
# 开启接口的PFC死锁检测功能。
[Spine1-if-range] priority-flow-control deadlock enable
# 配置PFC的反压帧触发门限为3500,反压帧停止门限与触发门限间的偏移量为51,Headroom缓存门限为2000,PFC预留门限为30。
[Spine1-if-range] priority-flow-control dot1p 5 headroom 2000
[Spine1-if-range] priority-flow-control dot1p 5 reserved-buffer 30
[Spine1-if-range] priority-flow-control dot1p 5 ingress-buffer static 3500
[Spine1-if-range] priority-flow-control dot1p 5 ingress-threshold-offset 51
[Spine1-if-range] quit
# 进入批量接口配置视图,配置与Leaf对接的接口。
[Spine1] interface range HundredGigE 3/0/1 to HundredGigE 3/0/4
# 开启与对端自动协商是否开启PFC功能。
[Spine1-if-range] priority-flow-control auto
# 开启指定5队列的PFC功能。
[Spine1-if-range] priority-flow-control no-drop dot1p 5
# 开启接口的PFC死锁检测功能。
[Spine1-if-range] priority-flow-control deadlock enable
# 配置PFC的反压帧触发门限为4000,反压帧停止门限与触发门限间的偏移量为51,Headroom缓存门限为3000,PFC预留门限为30。
[Spine1-if-range] priority-flow-control dot1p 5 headroom 3000
[Spine1-if-range] priority-flow-control dot1p 5 reserved-buffer 30
[Spine1-if-range] priority-flow-control dot1p 5 ingress-buffer static 4000
[Spine1-if-range] priority-flow-control dot1p 5 ingress-threshold-offset 51
[Spine1-if-range] quit
(7) 配置iNOF功能
# 全局使能iNOF功能,并进入iNOF视图。
[Spine1] inof enable
# 将允许相互访问的iNOF主机加入到相同域中
[Spine1-inof] zone H1toS1
[Spine1-inof-zone-H1toS1] host 100.1.1.1
[Spine1-inof-zone-H1toS1] host 101.1.1.1
[Spine1-inof-zone-H1toS1] host 100.1.1.2
[Spine1-inof-zone-H1toS1] host 101.1.1.2
[Spine1-inof-zone-H1toS1] quit
[Spine1-inof] zone H2toS1
[Spine1-inof-zone-H2toS1] host 100.1.1.3
[Spine1-inof-zone-H2toS1] host 101.1.1.1
[Spine1-inof-zone-H2toS1] host 100.1.1.4
[Spine1-inof-zone-H2toS1] host 101.1.1.2
[Spine1-inof-zone-H2toS1] quit
[Spine1-inof] quit
(1) 全局使能LLDP功能
# 全局使能LLDP功能。
<Spine2> system-view
[Spine2] lldp global enable
(2) VLAN和接口配置
# 创建VLAN。
[Spine2] vlan 201
[Spine2-vlan201] quit
# 创建vlan虚接口。
[Spine2] interface Vlan-interface 201
# 配置vlan虚接口地址,作为业务服务器RDMA网卡接口的网关。
[Spine2-Vlan-interface101] ip address 201.1.1.254 24
# 配置vlan虚接口mac地址。
[Spine2-Vlan-interface101] mac-address 0000-5e00-0001
[Spine2-Vlan-interface101] quit
# 进入批量接口配置视图,配置与存储网卡对接的接口。
[Spine2] interface range Twenty-FiveGigE 2/0/1 to Twenty-FiveGigE 2/0/8
# 将接口的链路类型修改为trunk。
[Spine2-if-range] port link-type trunk
# 禁止vlan 1通过这些trunk接口。
[Spine2-if-range] undo port trunk permit vlan 1
# 允许vlan 201通过这些trunk接口。
[Spine2-if-range] port trunk permit vlan 201
# 配置为stp edge-port。
[Spine2-if-range] stp edged-port
# 允许lldp发布dot1-tlv的tlv类型。
[Spine2-if-range] lldp tlv-enable dot1-tlv dcbx
# 端口信任802.1p优先级。
[Spine2-if-range] qos trust dot1p
[Spine2-if-range] quit
# 进入批量接口配置视图,配置与Leaf对接的接口。
[Spine2] interface range HundredGigE 3/0/1 to HundredGigE 3/0/4
# 将以太接口切换为三层工作模式。
[Spine2-if-range] port link-mode route
The configuration of the interface will be restored to the default. Continue? [Y
/N]:y
# 端口信任DSCP优先级。
[Spine2-if-range] qos trust dscp
[Spine2-if-range] quit
# 配置接口IP地址。
[Spine2] interface HundredGigE 3/0/1
[Spine2-HundredGigE3/0/1] ip address 172.16.25.2 30
[Spine2-HundredGigE3/0/1] quit
[Spine2] interface HundredGigE 3/0/2
[Spine2-HundredGigE3/0/2] ip address 172.16.25.6 30
[Spine2-HundredGigE3/0/2] quit
其它接口配置方法类似,后略。
(3) 配置BGP路由协议。
# 创建接口LoopBack 0。
[Spine2] interface LoopBack 0
# 配置LoopBack 0的IP,作为全局的Router ID
[Spine2-LoopBack0] ip address 92.1.1.2 32
[Spine2-LoopBack0] quit
# 配置全局Router ID
[Spine2] router-id 92.1.1.2
# 启动BGP实例default,指定该BGP实例的本地AS号,并进入BGP实例视图
[Spine2-bgp-default] bgp 65513
# 配置BGP的Router ID
[Spine2-bgp-default] router-id 92.1.1.2
# 将Leaf设备添加为对等体
[Spine2-bgp-default] peer 172.16.25.1 as-number 65513
[Spine2-bgp-default] peer 172.16.25.5 as-number 65513
…
# 进入BGP ipv4单播地址族视图
[Spine2-bgp-default] address-family ipv4 unicast
# 配置进行BGP负载分担的路由条数为16
[Spine2-bgp-default-ipv4] balance 16
# 发布Loopback0接口地址的路由。
[Spine2-bgp-default-ipv4] network 92.1.1.2 255.255.255.255
# 发布存储网卡接入网段的路由。
[Spine2-bgp-default-ipv4] network 201.1.1.0 255.255.255.0
# 发布与Leaf互联接口的网段路由
[Spine2-bgp-default-ipv4] network 172.16.25.0 255.255.255.252
[Spine2-bgp-default-ipv4] network 172.16.25.4 255.255.255.252
…
# 允许本地路由器与对等体交换路由信息,配置对等体为路由反射器的客户机。
[Spine2-bgp-default-ipv4] peer 172.16.25.1 enable
[Spine2-bgp-default-ipv4] peer 172.16.25.5 enable
[Spine2-bgp-default-ipv4] peer 172.16.25.1 reflect-client
[Spine2-bgp-default-ipv4] peer 172.16.25.5 reflect-client
…
[Spine2-bgp-default-ipv4] quit
# 进入BGP iNOF地址族视图。
[Spine2-bgp-default] address-family inof
# 配置Spine角色为反射器。
[Spine2-bgp-default-inof] role reflector
# 允许本地路由器与对等体交换路由信息,配置对等体为路由反射器的客户机。
[Spine2-bgp-default-inof] peer 172.16.25.1 enable
[Spine2-bgp-default-inof] peer 172.16.25.5 enable
[Spine2-bgp-default-inof] peer 172.16.25.1 reflect-client
[Spine2-bgp-default-inof] peer 172.16.25.5 reflect-client
…
[Spine2-bgp-default-inof]quit
[Spine2-bgp-default]quit
![]()
使用EBGP作为传递iNOF信息的路由协议时,iNOF地址族不需要配置role reflector,IPv4和iNOF地址族不需要配置peer {ipv4-address | ipv6-address } reflect-client。
(4) 配置静态ECN功能(本功能与AI ECN功能选择一种配置即可)
# 配置队列5和队列6最多可使用的共享区域的大小为100%。队列5为RDMA应用报文队列,队列6为CNP报文所在队列。
[Spine2] buffer egress cell queue 5 shared ratio 100
[Spine2] buffer egress cell queue 6 shared ratio 100
[Spine2] buffer apply
# 全局使能ECN拥塞标记功能。
[Spine2] qos wred ecn enable
# 创建WRED表,并进入WRED表视图
[Spine2] qos wred queue table ECN
# 配置WRED参数。注意:使用WRED表配置WRED参数时,推荐将非无损队列参数中的high-limit配置为可配置的最大值,low-limit配置为最大值减1,使其WRED功能和ECN功能实际不生效
[Spine2-wred-table-queue-ECN] queue 0 low-limit 69631 high-limit 69632
[Spine2-wred-table-queue-ECN] queue 1 low-limit 69631 high-limit 69632
[Spine2-wred-table-queue-ECN] queue 2 low-limit 69631 high-limit 69632
[Spine2-wred-table-queue-ECN] queue 3 low-limit 69631 high-limit 69632
[Spine2-wred-table-queue-ECN] queue 4 low-limit 69631 high-limit 69632
[Spine2-wred-table-queue-ECN] queue 6 low-limit 69631 high-limit 69632
[Spine2-wred-table-queue-ECN] queue 7 low-limit 69631 high-limit 69632
[Spine2-wred-table-queue-ECN] queue 5 low-limit 600 high-limit 2000 [Spine2-wred-table-queue-ECN] discard-probability 20
[Spine2-wred-table-queue-ECN] quit
# 设置内联口ECN参数.注意:仅框式设备需要配置
[Spine2] qos wred apply ECN fabric
# 进入批量接口配置视图,配置与存储网卡对接的接口。
[Spine2] interface range Twenty-FiveGigE 2/0/1 to Twenty-FiveGigE 2/0/8
# 配置队列5的WRED平均长度的下限为500,平均长度的上限为1200,丢弃概率为20%。
[Spine2-if-range] qos wred queue 5 low-limit 500 high-limit 1200 discard-probability 20
# 开启接口的WFQ队列,并按照每次轮询可发送的报文的字节数进行计算,配置队列5具有较高调度权重60,队列6、7采用严格优先级调度。
[Spine2-if-range] qos wfq byte-count
[Spine2-if-range] qos wfq ef group 1 byte-count 60
[Spine2-if-range] qos wfq cs6 group sp
[Spine2-if-range] qos wfq cs7 group sp
# 对队列6的报文进行流量整形,正常流速为12500000kbps(建议配置为接口带宽的一半)。
[Spine2-if-range] qos gts queue 6 cir 12500000
[Spine2-if-range] quit
# 进入批量接口配置视图,配置与Leaf对接的接口。
[Spine2] interface range HundredGigE 3/0/1 to HundredGigE 3/0/4
# 配置队列5的WRED平均长度的下限为600,平均长度的上限为2000,丢弃概率为20%。
[Spine2-if-range] qos wred queue 5 low-limit 600 high-limit 2000 discard-probability 20
# 开启接口的WFQ队列,并按照每次轮询可发送的报文的字节数进行计算,配置队列5具有较高调度权重60,队列6、7采用严格优先级调度。
[Spine2-if-range] qos wfq byte-count
[Spine2-if-range] qos wfq ef group 1 byte-count 60
[Spine2-if-range] qos wfq cs6 group sp
[Spine2-if-range] qos wfq cs7 group sp
# 对队列6的报文进行流量整形,正常流速为50000000kbps(建议配置为接口带宽的一半)。
[Spine2-if-range] qos gts queue 6 cir 50000000
[Spine2-if-range] quit
![]()
对于S12500G-AF/S6850-G系列交换机,支持在接口视图配置WRED的各种参数。端口WRED方式可以只配置RoCE队列,不同接口可以配置不同的参数,使用更为灵活。对于支持该功能的产品和版本,推荐采用端口WRED方式。
(5) 配置AI ECN功能(S12500G-AF仅R8053Pxx及以上版本支持,本功能与静态ECN功能选择一种配置即可)
# 配置RoCEv2流量NetAnalysis功能的工作模式。为了保证能够正确分析RoCEv2流量,当同一个RDMA客户端和服务器端存在多条路径时,建议在客户端和服务器端接入的节点设备上均配置双向模式,在所有的中间节点设备上均配置单向模式。
[Spine2] netanalysis rocev2 mode bidir
This operation will erase all the netanalysis configuration.
Continue?[Y/N]:y
# 开启RoCEv2流量的NetAnalysis统计功能。
[Spine2] netanalysis rocev2 statistics global
# 开启RoCEv2流量的AI ECN功能。
[Spine2] netanalysis rocev2 ai-ecn enable
# 配置AI ECN功能的模式为分布式模式。
[Spine2] ai-service
[Spine2-ai-service] ai ai-ecn enable mode distributed
# 开启队列5、6的AI ECN功能。
[Spine2-ai-service] ai-ecn
[Spine2-ai-service-ai-ecn] queue 5 enable
[Spine2-ai-service-ai-ecn] queue 6 enable
[Spine2-ai-service-ai-ecn] quit
[Spine2-ai-service] quit
(6) 配置PFC功能和PFC死锁检测功能。
# 全局配置5队列的PFC死锁检测周期为10。
[Spine2] priority-flow-control deadlock cos 5 interval 10
# 全局配置PFC死锁检测的精度为high。
[Spine2] priority-flow-control deadlock precision high
# 使能内联口队列5的PFC功能。注意:仅框式设备需要配置
[Spine1] priority-flow-control inner-port enable
# 配置内联口的5队列的PFC的反压帧触发门限为4000,反压帧停止门限与触发门限间的偏移量为51,Headroom缓存门限为3000,PFC预留门限为30。注意:仅框式设备需要配置
[Spine1] priority-flow-control inner-port no-drop dot1p 5 ingress-buffer static 4000 ingress-threshold-offset 51 headroom 3000 reserved-buffer 30
# 进入批量接口配置视图,配置与存储网卡对接的接口。
[Spine2] interface range Twenty-FiveGigE 2/0/1 to Twenty-FiveGigE 2/0/8
# 开启与对端自动协商是否开启PFC功能。
[Spine2-if-range] priority-flow-control auto
# 开启指定5队列的PFC功能。
[Spine2-if-range] priority-flow-control no-drop dot1p 5
# 开启接口的PFC死锁检测功能。
[Spine2-if-range] priority-flow-control deadlock enable
# 配置PFC的反压帧触发门限为3500,反压帧停止门限与触发门限间的偏移量为51,Headroom缓存门限为2000,PFC预留门限为30。
[Spine2-if-range] priority-flow-control dot1p 5 headroom 2000
[Spine2-if-range] priority-flow-control dot1p 5 reserved-buffer 30
[Spine2-if-range] priority-flow-control dot1p 5 ingress-buffer static 3500
[Spine2-if-range] priority-flow-control dot1p 5 ingress-threshold-offset 51
[Spine2-if-range] quit
# 进入批量接口配置视图,配置与Leaf对接的接口。
[Spine2] interface range HundredGigE 3/0/1 to HundredGigE 3/0/4
# 开启与对端自动协商是否开启PFC功能。
[Spine2-if-range] priority-flow-control auto
# 开启指定5队列的PFC功能。
[Spine2-if-range] priority-flow-control no-drop dot1p 5
# 开启接口的PFC死锁检测功能。
[Spine2-if-range] priority-flow-control deadlock enable
# 配置PFC的反压帧触发门限为4000,反压帧停止门限与触发门限间的偏移量为51,Headroom缓存门限为3000,PFC预留门限为30。
[Spine2-if-range] priority-flow-control dot1p 5 headroom 3000
[Spine2-if-range] priority-flow-control dot1p 5 reserved-buffer 30
[Spine2-if-range] priority-flow-control dot1p 5 ingress-buffer static 4000
[Spine2-if-range] priority-flow-control dot1p 5 ingress-threshold-offset 51
[Spine2-if-range] quit
(7) 配置iNOF功能
# 全局使能iNOF功能,并进入iNOF视图。
[Spine2] inof enable
# 将允许相互访问的iNOF主机加入到相同域中
[Spine2-inof] zone H1toS1
[Spine2-inof-zone-H1toS1] host 100.1.1.1
[Spine2-inof-zone-H1toS1] host 101.1.1.1
[Spine2-inof-zone-H1toS1] host 100.1.1.2
[Spine2-inof-zone-H1toS1] host 101.1.1.2
[Spine2-inof-zone-H1toS1] quit
[Spine2-inof] zone H2toS1
[Spine2-inof-zone-H2toS1] host 100.1.1.3
[Spine2-inof-zone-H2toS1] host 101.1.1.1
[Spine2-inof-zone-H2toS1] host 100.1.1.4
[Spine2-inof-zone-H2toS1] host 101.1.1.2
[Spine2-inof-zone-H2toS1] quit
[Spine2-inof] quit
· 查看接口WRED参数(ECN水线)配置
display qos wred interface
· 查看接口的PFC信息
display priority-flow-control interface
· 查看设备所有接口丢包计数、ECN拥塞标记计数的汇总信息
display packet-drop summary
· 查看接口丢包计数、ECN拥塞标记计数等信息
display packet-drop interface
· 查看iNOF域的相关信息
display inof configuration zone
· 查看iNOF网络中接入主机的信息
display inof information host
以二层框盒组网为例,集中式存储的RoCE高性能存储网络典型组网如下图所示。
本节以每个平面使用Leaf-Spine的两层组网为例,Leaf和Spine均使用S12500G-AF系列框式交换机。
在该组网中,服务器和存储均采用VLAN接入,使用25G带宽链路,分别接入到两个平面的交换机;Leaf和Spine之间采用路由口互联,使用多条100G带宽链路,形成等价路由。
存储、存储服务器和交换机均支持iNOF(Intelligent Lossless NVMe Over Fabric,智能无损存储网络),从而可以快速感知网络服务器和磁盘设备的加入和离开。
本组网中要求实现RDMA应用报文使用队列5进行无损传输。
![]()
本文以一个平面1台Leaf设备示例,实际组网时一个平面可能存在多台Leaf,各Leaf设备的配置相似,此处不再一一列出。
图5-5 集中式存储典型组网
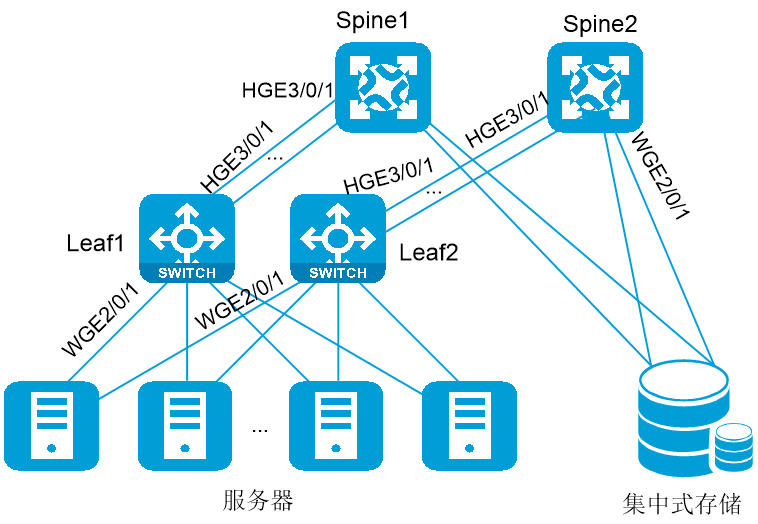
表5-5 服务器/存储接入口IP规划
|
设备 |
接口 |
IP地址/VLAN |
设备 |
接口 |
IP地址/VLAN |
|
Leaf1 |
WGE2/0/1 |
100 |
Leaf2 |
WGE2/0/1 |
200 |
|
… |
100 |
… |
200 |
||
|
WGE2/0/8 |
100 |
WGE2/0/8 |
200 |
||
|
Vlan-int100 |
100.1.1.254/24 |
Vlan-int201 |
200.1.1.254/24 |
||
|
LoopBack 0 |
91.1.1.1/32 |
LoopBack 0 |
91.1.1.2/32 |
||
|
Spine1 |
WGE2/0/1 |
101 |
Spine2 |
WGE2/0/1 |
201 |
|
… |
101 |
… |
201 |
||
|
WGE2/0/8 |
101 |
WGE2/0/8 |
201 |
||
|
Vlan-int101 |
101.1.1.254/24 |
Vlan-int200 |
201.1.1.254/24 |
||
|
LoopBack 0 |
92.1.1.1/32 |
LoopBack 0 |
92.1.1.2/32 |
表5-6 Leaf-Spine互联接口IP规划
|
设备 |
接口 |
IP地址/VLAN |
设备 |
接口 |
IP地址/VLAN |
|
Leaf1 |
HGE3/0/1 |
172.16.24.1/30 |
Spine1 |
HGE3/0/1 |
172.16.24.2/30 |
|
HGE3/0/2 |
172.16.24.5/30 |
HGE3/0/2 |
172.16.24.6/30 |
||
|
HGE3/0/3 |
172.16.24.9/30 |
HGE3/0/3 |
172.16.24.10/30 |
||
|
HGE3/0/4 |
172.16.24.13/30 |
HGE3/0/4 |
172.16.24.14/30 |
||
|
Leaf2 |
HGE3/0/1 |
172.16.25.1/30 |
Spine2 |
HGE3/0/1 |
172.16.25.2/30 |
|
HGE3/0/2 |
172.16.25.5/30 |
HGE3/0/2 |
172.16.25.6/30 |
||
|
HGE3/0/3 |
172.16.25.9/30 |
HGE3/0/3 |
172.16.25.10/30 |
||
|
HGE3/0/4 |
172.16.25.13/30 |
HGE3/0/4 |
172.16.25.14/30 |
![]()
· Leaf上服务器接入口的配置相似,配置仅以少量接口为例。
· Spine上存储接入口的配置相似,配置仅以少量接口为例。
· Leaf与Spine之间互联接口的配置相似,配置仅以少量接口为例。
· 本文以一个平面1台Leaf设备示例,实际组网时一个平面可能存在多台Leaf,各Leaf设备的配置相似,此处不再一一列出。
每个平面采用Leaf-Spine的两层组网形式。
使用IBGP作为路由互通协议:
· 通过BGP的IPv4地址族进行RDMA业务转发,发布Loopback口的地址(也作为router-id)、Leaf与Spine互联接口的网段、服务器/存储接入口的网段。
· 通过BGP的iNOF地址族传递存储、服务器的iNOF信息,Spine配置为路由反射器。
· 存储和服务器配置网关或路由,保证相互路由可达。
![]()
请按照业务需求和组网规模选择合适的路由协议,使用iNOF功能时,必须配置BGP的iNOF地址族用于iNOF信息传递,RDMA业务流量使用的路由协议没有限制。
为实现RDMA应用报文的无损传输,我们需要部署PFC功能和ECN功能:
· PFC功能基于优先级队列对报文进行流量控制。RDMA报文携带802.1P优先级5,我们对802.1P优先级为5的报文开启PFC功能。
RDMA报文转发路径的所有端口都需要配置PFC功能。
· ECN功能提供端到端的拥塞控制。设备检测到拥塞后,对报文的ECN域进行标记。接收端收到ECN标记的报文后,向发送端发送拥塞通知报文,使发送端降低流量发送速率。ECN分为手工指定WRED参数来实现的静态ECN,和AI组件实现的AI ECN功能:
¡ 如果配置静态ECN功能,则在本例中,我们在报文转发路径的所有端口均开启ECN功能。ECN功能配置的high-limit值(queue queue-id [ drop-level drop-level ] low-limit low-limit high-limit high-limit [ discard-probability discard-prob ])需要小于PFC反压帧触发门限值,以使ECN功能先生效。
¡ 如果Spine设备与Leaf设备都支持AI ECN功能,则可以开启指定队列的AI ECN功能。在智能无损网络中配置AI ECN功能时,需要先配置RoCEv2流量NetAnalysis功能,由NetAnalysis技术对现网的流量特征进行深度分析。关键配置包括:
- 使用netanalysis rocev2 mode命令配置RoCEv2流量NetAnalysis功能的工作模式;
- 使用netanalysis rocev2 statistics命令开启RoCEv2流量的NetAnalysis统计功能;
- 使用netanalysis rocev2 ai-ecn enable命令开启RoCEv2流量的AI ECN功能。
PFC和ECN参数请参考推荐值(国产芯片设备S12500G-AF/S12500CR/S6850-G)。
Leaf和Spine均使能iNOF,与存储、服务器互联的接口需要使能lldp和dcbx等功能。
需要在Spine上配置iNOF zone,并按照规划将存储、服务器的ip添加到相应的iNOF zone中以用于访问控制。
请确认存储及服务器的软件支持SNSD功能并配置正确,否则服务器和存储不能通过iNOF信息自动建立链接,也会导致存储网络的iNOF快速感知功能失效。
本文仅涉及交换机配置,存储以及存储服务器的配置,请以使用产品的资料为准。
静态ECN功能与AIECN功能选择一种配置即可。如果Spine设备与Leaf设备都支持AI ECN功能,则建议配置AI ECN功能。
AI ECN功能受License限制,请在使用本功能前安装有效的License。有关License的详细介绍,请参见“基础配置指导”中的“License管理”。
配置PFC功能时,必须配置接口信任报文自带的802.1p优先级或DSCP优先级(qos trust { dot1p | dscp }),并且转发路径上所有端口的802.1p优先级与本地优先级映射关系以及DSCP优先级与802.1p优先级映射关系必须一致,否则PFC功能将无法正常工作。对于本组网中的二层接口,建议配置接口信任报文自带的802.1p优先级(qos trust dot1p),对于三层接口,建议配置接口信任报文自带的DSCP优先级(qos trust dscp)。
对于接收到的以太网报文,设备将根据优先级信任模式和报文的802.1Q标签状态,设备将采用不同的方式为其标记调度优先级。当设备连接不同网络时,所有进入设备的报文,其外部优先级字段(包括DSCP和IP)都被映射为802.1p优先级,再根据802.1p优先级映射为内部优先级;设备根据内部优先级进行队列调度的QoS处理。
关于优先级映射的详细介绍,请参见产品配套的“ACL和QoS配置指导”中的“优先级映射”。
(1) 全局使能LLDP功能
# 全局使能LLDP功能。
<Leaf1> system-view
[Leaf1] lldp global enable
# 进入优先级映射表配置视图。
[Leaf1] qos map-table dot1p-lp
# 修改优先级映射表。
[Leaf1-maptbl-dot1p-lp] import 0 export 0
[Leaf1-maptbl-dot1p-lp] import 1 export 1
[Leaf1-maptbl-dot1p-lp] import 2 export 2
[Leaf1-maptbl-dot1p-lp] quit
(2) VLAN和接口配置
# 创建VLAN。
[Leaf1] vlan 100
[Leaf1-vlan100] quit
# 创建vlan虚接口。
[Leaf1] interface Vlan-interface 100
# 配置vlan虚接口地址,作为业务服务器RDMA网卡接口的网关。
[Leaf1-Vlan-interface100] ip address 100.1.1.254 24
# 配置vlan虚接口mac地址。
[Leaf1-Vlan-interface100] mac-address 0000-5e00-0001
[Leaf1-Vlan-interface100] quit
# 进入批量接口配置视图,配置与业务服务器网卡对接的接口。
[Leaf1] interface range Twenty-FiveGigE 2/0/1 to Twenty-FiveGigE 2/0/8
# 将接口的链路类型修改为trunk。
[Leaf1-if-range] port link-type trunk
# 禁止vlan 1通过这些trunk接口。
[Leaf1-if-range] undo port trunk permit vlan 1
# 允许vlan 100通过这些trunk接口。
[Leaf1-if-range] port trunk permit vlan 100
# 配置为stp edge-port。
[Leaf1-if-range] stp edged-port
# 允许lldp发布dot1-tlv的tlv类型。
[Leaf1-if-range] lldp tlv-enable dot1-tlv dcbx
# 端口信任802.1p优先级。
[Leaf1-if-range] qos trust dot1p
[Leaf1-if-range] quit
# 进入批量接口配置视图,配置与Spine对接的接口。
[Leaf1] interface range HundredGigE 3/0/1 to HundredGigE 3/0/4
# 将以太接口切换为三层工作模式。
[Leaf1-if-range] port link-mode route
The configuration of the interface will be restored to the default. Continue? [Y
/N]:y
# 端口信任DSCP优先级。
[Leaf1-if-range] qos trust dscp
[Leaf1-if-range] quit
# 配置接口IP地址。
[Leaf1] interface HundredGigE 3/0/1
[Leaf1-HundredGigE3/0/1] ip address 172.16.24.1 30
[Leaf1-HundredGigE3/0/1] quit
[Leaf1] interface HundredGigE 3/0/2
[Leaf1-HundredGigE3/0/2] ip address 172.16.24.5 30
[Leaf1-HundredGigE3/0/2] quit
其它接口配置方法类似,后略。
(3) 配置BGP路由协议。
# 创建接口LoopBack 0。
[Leaf1] interface LoopBack 0
# 配置LoopBack 0的ip,作为全局的Router ID
[Leaf1-LoopBack0] ip address 91.1.1.1 32
[Leaf1-LoopBack0] quit
# 配置全局Router ID
[Leaf1] router-id 91.1.1.1
# 启动BGP实例default,指定该BGP实例的本地AS号,并进入BGP实例视图
[Leaf1-bgp-default] bgp 65512
# 配置BGP的Router ID
[Leaf1-bgp-default] router-id 91.1.1.1
# 将Spine设备添加为对等体
[Leaf1-bgp-default] peer 172.16.24.2 as-number 65512
[Leaf1-bgp-default] peer 172.16.24.6 as-number 65512
…
# 进入BGP ipv4单播地址族视图
[Leaf1-bgp-default] address-family ipv4 unicast
# 配置进行BGP负载分担的路由条数为16
[Leaf1-bgp-default-ipv4] balance 16
# 发布Loopback0接口地址的路由
[Leaf1-bgp-default-ipv4] network 91.1.1.1 255.255.255.255
# 发布业务服务器接入网段的路由
[Leaf1-bgp-default-ipv4] network 100.1.1.0 255.255.255.0
# 发布与Spine互联接口的网段路由
[Leaf1-bgp-default-ipv4] network 172.16.24.0 255.255.255.252
[Leaf1-bgp-default-ipv4] network 172.16.24.4 255.255.255.252
…
# 允许本地路由器与对等体交换路由信息
[Leaf1-bgp-default-ipv4] peer 172.16.24.2 enable
[Leaf1-bgp-default-ipv4] peer 172.16.24.6 enable
…
[Leaf1-bgp-default-ipv4] quit
# 进入BGP iNOF地址族视图
[Leaf1-bgp-default] address-family inof
# 配置Leaf角色为客户机
[Leaf1-bgp-default-inof] role reflect-client
# 允许本地路由器与对等体交换路由信息
[Leaf1-bgp-default-inof] peer 172.16.24.2 enable
[Leaf1-bgp-default-inof] peer 172.16.24.6 enable
…
[Leaf1-bgp-default-inof]quit
[Leaf1-bgp-default]quit
(4) 配置静态ECN功能(本功能与AI ECN功能选择一种配置即可)
# 配置队列5和队列6最多可使用的共享区域的大小为100%。队列5为RDMA应用报文队列,队列6为CNP报文所在队列。
[Leaf1] buffer egress cell queue 5 shared ratio 100
[Leaf1] buffer egress cell queue 6 shared ratio 100
[Leaf1] buffer apply
# 全局使能ECN拥塞标记功能。
[Leaf1] qos wred ecn enable
# 创建WRED表,并进入WRED表视图
[Leaf1] qos wred queue table ECN
# 配置WRED参数。注意:使用WRED表配置WRED参数时,推荐将非无损队列参数中的high-limit配置为可配置的最大值,low-limit配置为最大值减1,使其WRED功能和ECN功能实际不生效
[Leaf1-wred-table-queue-ECN] queue 0 low-limit 69631 high-limit 69632
[Leaf1-wred-table-queue-ECN] queue 1 low-limit 69631 high-limit 69632
[Leaf1-wred-table-queue-ECN] queue 2 low-limit 69631 high-limit 69632
[Leaf1-wred-table-queue-ECN] queue 3 low-limit 69631 high-limit 69632
[Leaf1-wred-table-queue-ECN] queue 4 low-limit 69631 high-limit 69632
[Leaf1-wred-table-queue-ECN] queue 6 low-limit 69631 high-limit 69632
[Leaf1-wred-table-queue-ECN] queue 7 low-limit 69631 high-limit 69632
[Leaf1-wred-table-queue-ECN] queue 5 low-limit 600 high-limit 2000 [Leaf1-wred-table-queue-ECN] discard-probability 20
[Leaf1-wred-table-queue-ECN] quit
# 设置内联口ECN参数.注意:仅框式设备需要配置
[Spine1] qos wred apply ECN fabric
# 进入批量接口配置视图,配置与业务服务器网卡对接的接口。
[Leaf1] interface range Twenty-FiveGigE 2/0/1 to Twenty-FiveGigE 2/0/8
# 配置队列5的WRED平均长度的下限为500,平均长度的上限为1200,丢弃概率为20%。
[Leaf1-if-range] qos wred queue 5 low-limit 500 high-limit 1200 discard-probability 20
# 开启接口的WFQ队列,并按照每次轮询可发送的报文的字节数进行计算,配置队列5具有较高调度权重60,队列6、7采用严格优先级调度。
[Leaf1-if-range] qos wfq byte-count
[Leaf1-if-range] qos wfq ef group 1 byte-count 60
[Leaf1-if-range] qos wfq cs6 group sp
[Leaf1-if-range] qos wfq cs7 group sp
# 对队列6的报文进行流量整形,正常流速为12500000kbps(建议配置为接口带宽的一半)。
[Leaf1-if-range] qos gts queue 6 cir 12500000
[Leaf1-if-range] quit
# 进入批量接口配置视图,配置与Spine对接的接口。
[Leaf1] interface range HundredGigE 3/0/1 to HundredGigE 3/0/4
# 配置队列5的WRED平均长度的下限为600,平均长度的上限为2000,丢弃概率为20%。
[Leaf1-if-range] qos wred queue 5 low-limit 600 high-limit 2000 discard-probability 20
# 开启接口的WFQ队列,并按照每次轮询可发送的报文的字节数进行计算,配置队列5具有较高调度权重60,队列6、7采用严格优先级调度。
[Leaf1-if-range] qos wfq byte-count
[Leaf1-if-range] qos wfq ef group 1 byte-count 60
[Leaf1-if-range] qos wfq cs6 group sp
[Leaf1-if-range] qos wfq cs7 group sp
# 对队列6的报文进行流量整形,正常流速为50000000kbps(建议配置为接口带宽的一半)。
[Leaf1-if-range] qos gts queue 6 cir 50000000
[Leaf1-if-range] quit
![]()
对于S12500G-AF/S6850-G系列交换机,支持在接口视图配置WRED的各种参数。端口WRED方式可以只配置RoCE队列,不同接口可以配置不同的参数,使用更为灵活。对于支持该功能的产品和版本,推荐采用端口WRED方式。
(5) 配置AI ECN功能(S12500G-AF仅R8053Pxx及以上版本支持,本功能与静态ECN功能选择一种配置即可)
# 配置RoCEv2流量NetAnalysis功能的工作模式。为了保证能够正确分析RoCEv2流量,当同一个RDMA客户端和服务器端存在多条路径时,建议在客户端和服务器端接入的节点设备上均配置双向模式,在所有的中间节点设备上均配置单向模式。
[Leaf1] netanalysis rocev2 mode bidir
This operation will erase all the netanalysis configuration.
Continue?[Y/N]:y
# 开启RoCEv2流量的NetAnalysis统计功能。
[Leaf1] netanalysis rocev2 statistics global
# 开启RoCEv2流量的AI ECN功能。
[Leaf1] netanalysis rocev2 ai-ecn enable
# 配置AI ECN功能的模式为分布式模式。
[Leaf1] ai-service
[Leaf1-ai-service] ai ai-ecn enable mode distributed
# 开启队列5、6的AI ECN功能。
[Leaf1-ai-service] ai-ecn
[Leaf1-ai-service-ai-ecn] queue 5 enable
[Leaf1-ai-service-ai-ecn] queue 6 enable
[Leaf1-ai-service-ai-ecn] quit
[Leaf1-ai-service] quit
(6) 配置PFC功能和PFC死锁检测功能。
# 全局配置5队列的PFC死锁检测周期为10。
[Leaf1] priority-flow-control deadlock cos 5 interval 10
# 全局配置PFC死锁检测的精度为high。
[Leaf1] priority-flow-control deadlock precision high
# 使能内联口队列5的PFC功能。注意:仅框式设备需要配置
[Leaf1] priority-flow-control inner-port enable
# 配置内联口的5队列的PFC的反压帧触发门限为4000,反压帧停止门限与触发门限间的偏移量为51,Headroom缓存门限为3000,PFC预留门限为30。注意:仅框式设备需要配置
[Leaf1] priority-flow-control inner-port no-drop dot1p 5 ingress-buffer static 4000 ingress-threshold-offset 51 headroom 3000 reserved-buffer 30
# 进入批量接口配置视图,配置与业务服务器网卡对接的接口。
[Leaf1] interface range Twenty-FiveGigE 2/0/1 to Twenty-FiveGigE 2/0/8
# 开启与对端自动协商是否开启PFC功能。
[Leaf1-if-range] priority-flow-control auto
# 开启指定5队列的PFC功能。
[Leaf1-if-range] priority-flow-control no-drop dot1p 5
# 开启接口的PFC死锁检测功能。
[Leaf1-if-range] priority-flow-control deadlock enable
# 配置PFC的反压帧触发门限为3500,反压帧停止门限与触发门限间的偏移量为51,Headroom缓存门限为2000,PFC预留门限为30。
[Leaf1-if-range] priority-flow-control dot1p 5 headroom 2000
[Leaf1-if-range] priority-flow-control dot1p 5 reserved-buffer 30
[Leaf1-if-range] priority-flow-control dot1p 5 ingress-buffer static 3500
[Leaf1-if-range] priority-flow-control dot1p 5 ingress-threshold-offset 51
[Leaf1-if-range] quit
# 进入批量接口配置视图,配置与Spine对接的接口。
[Leaf1] interface range HundredGigE 3/0/1 to HundredGigE 3/0/4
# 开启与对端自动协商是否开启PFC功能。
[Leaf1-if-range] priority-flow-control auto
# 开启指定5队列的PFC功能。
[Leaf1-if-range] priority-flow-control no-drop dot1p 5
# 开启接口的PFC死锁检测功能。
[Leaf1-if-range] priority-flow-control deadlock enable
# 配置PFC的反压帧触发门限为4000,反压帧停止门限与触发门限间的偏移量为51,Headroom缓存门限为3000,PFC预留门限为30。
[Leaf1-if-range] priority-flow-control dot1p 5 headroom 3000
[Leaf1-if-range] priority-flow-control dot1p 5 reserved-buffer 30
[Leaf1-if-range] priority-flow-control dot1p 5 ingress-buffer static 4000
[Leaf1-if-range] priority-flow-control dot1p 5 ingress-threshold-offset 51
[Leaf1-if-range] quit
(7) 配置iNOF功能
# 全局使能iNOF功能,并进入iNOF视图。
[Leaf1] inof enable
[Leaf1-inof] quit
(1) 全局使能LLDP功能
# 全局使能LLDP功能。
<Leaf2> system-view
[Leaf2] lldp global enable
# 进入优先级映射表配置视图。
[Leaf2] qos map-table dot1p-lp
# 修改优先级映射表。
[Leaf2-maptbl-dot1p-lp] import 0 export 0
[Leaf2-maptbl-dot1p-lp] import 1 export 1
[Leaf2-maptbl-dot1p-lp] import 2 export 2
[Leaf2-maptbl-dot1p-lp] quit
(2) VLAN和接口配置
# 创建VLAN。
[Leaf2] vlan 200
[Leaf2-vlan200] quit
# 创建vlan虚接口。
[Leaf2] interface Vlan-interface 200
# 配置vlan虚接口地址,作为业务服务器RDMA网卡接口的网关。
[Leaf2-Vlan-interface200] ip address 200.1.1.254 24
# 配置vlan虚接口mac地址。
[Leaf2-Vlan-interface200] mac-address 0000-5e00-0001
[Leaf2-Vlan-interface200] quit
# 进入批量接口配置视图,配置与业务服务器网卡对接的接口。
[Leaf2] interface range Twenty-FiveGigE 2/0/1 to Twenty-FiveGigE 2/0/8
# 将接口的链路类型修改为trunk。
[Leaf2-if-range] port link-type trunk
# 禁止vlan 1通过这些trunk接口。
[Leaf2-if-range] undo port trunk permit vlan 1
# 允许vlan 200通过这些trunk接口。
[Leaf2-if-range] port trunk permit vlan 200
# 配置为stp edge-port。
[Leaf2-if-range] stp edged-port
# 允许lldp发布dot1-tlv的tlv类型。
[Leaf2-if-range] lldp tlv-enable dot1-tlv dcbx
# 端口信任802.1p优先级。
[Leaf2-if-range] qos trust dot1p
[Leaf2-if-range] quit
# 进入批量接口配置视图,配置与Spine对接的接口。
[Leaf2] interface range HundredGigE 3/0/1 to HundredGigE 3/0/4
# 将以太接口切换为三层工作模式。
[Leaf2-if-range] port link-mode route
The configuration of the interface will be restored to the default. Continue? [Y
/N]:y
# 端口信任DSCP优先级。
[Leaf2-if-range] qos trust dscp
[Leaf2-if-range] quit
# 配置接口IP地址。
[Leaf2] interface HundredGigE 3/0/1
[Leaf2-HundredGigE3/0/1] ip address 172.16.25.1 30
[Leaf2-HundredGigE3/0/1] quit
[Leaf2] interface HundredGigE 3/0/4
[Leaf2-HundredGigE3/0/4] ip address 172.16.25.5 30
[Leaf2-HundredGigE3/0/4] quit
其它接口配置方法类似,后略。
(3) 配置BGP路由协议。
# 创建接口LoopBack 0。
[Leaf2] interface LoopBack 0
# 配置LoopBack 0的ip,作为全局的Router ID
[Leaf2-LoopBack0] ip address 91.1.1.2 32
[Leaf2-LoopBack0] quit
# 配置全局Router ID
[Leaf2] router-id 91.1.1.2
# 启动BGP实例default,指定该BGP实例的本地AS号,并进入BGP实例视图
[Leaf2-bgp-default] bgp 65513
# 配置BGP的Router ID
[Leaf2-bgp-default] router-id 91.1.1.2
# 将Spine设备添加为对等体
[Leaf2-bgp-default] peer 172.16.25.2 as-number 65513
[Leaf2-bgp-default] peer 172.16.25.6 as-number 65513
…
# 进入BGP ipv4单播地址族视图
[Leaf2-bgp-default] address-family ipv4 unicast
# 配置进行BGP负载分担的路由条数为16
[Leaf2-bgp-default-ipv4] balance 16
# 发布Loopback0接口地址的路由
[Leaf2-bgp-default-ipv4] network 91.1.1.2 255.255.255.255
# 发布业务服务器接入网段的路由
[Leaf2-bgp-default-ipv4] network 200.1.1.0 255.255.255.0
# 发布与Spine互联接口的网段路由
[Leaf2-bgp-default-ipv4] network 172.16.25.0 255.255.255.252
[Leaf2-bgp-default-ipv4] network 172.16.25.4 255.255.255.252
…
# 允许本地路由器与对等体交换路由信息
[Leaf2-bgp-default-ipv4] peer 172.16.25.2 enable
[Leaf2-bgp-default-ipv4] peer 172.16.25.6 enable
…
[Leaf2-bgp-default-ipv4] quit
# 进入BGP iNOF地址族视图
[Leaf2-bgp-default] address-family inof
# 配置Leaf角色为客户机
[Leaf2-bgp-default-inof] role reflect-client
# 允许本地路由器与对等体交换路由信息
[Leaf2-bgp-default-inof] peer 172.16.24.2 enable
[Leaf2-bgp-default-inof] peer 172.16.24.6 enable
…
[Leaf2-bgp-default-inof]quit
[Leaf2-bgp-default]quit
(4) 配置静态ECN功能(本功能与AI ECN功能选择一种配置即可)
# 配置队列5和队列6最多可使用的共享区域的大小为100%。队列5为RDMA应用报文队列,队列6为CNP报文所在队列。
[Leaf2] buffer egress cell queue 5 shared ratio 100
[Leaf2] buffer egress cell queue 6 shared ratio 100
[Leaf2] buffer apply
# 全局使能ECN拥塞标记功能。
[Leaf2] qos wred ecn enable
# 创建WRED表,并进入WRED表视图
[Leaf2] qos wred queue table ECN
# 配置WRED参数。注意:使用WRED表配置WRED参数时,推荐将非无损队列参数中的high-limit配置为可配置的最大值,low-limit配置为最大值减1,使其WRED功能和ECN功能实际不生效
[Leaf2-wred-table-queue-ECN] queue 0 low-limit 69631 high-limit 69632
[Leaf2-wred-table-queue-ECN] queue 1 low-limit 69631 high-limit 69632
[Leaf2-wred-table-queue-ECN] queue 2 low-limit 69631 high-limit 69632
[Leaf2-wred-table-queue-ECN] queue 3 low-limit 69631 high-limit 69632
[Leaf2-wred-table-queue-ECN] queue 4 low-limit 69631 high-limit 69632
[Leaf2-wred-table-queue-ECN] queue 6 low-limit 69631 high-limit 69632
[Leaf2-wred-table-queue-ECN] queue 7 low-limit 69631 high-limit 69632
[Leaf2-wred-table-queue-ECN] queue 5 low-limit 600 high-limit 2000 [Leaf2-wred-table-queue-ECN] discard-probability 20
[Leaf2-wred-table-queue-ECN] quit
# 设置内联口ECN参数.注意:仅框式设备需要配置
[Leaf2] qos wred apply ECN fabric
# 进入批量接口配置视图,配置与业务服务器网卡对接的接口。
[Leaf2] interface range Twenty-FiveGigE 2/0/1 to Twenty-FiveGigE 2/0/8
# 配置队列5的WRED平均长度的下限为500,平均长度的上限为1200,丢弃概率为20%。
[Leaf2-if-range] qos wred queue 5 low-limit 500 high-limit 1200 discard-probability 20
# 开启接口的WFQ队列,并按照每次轮询可发送的报文的字节数进行计算,配置队列5具有较高调度权重60,队列6、7采用严格优先级调度。
[Leaf2-if-range] qos wfq byte-count
[Leaf2-if-range] qos wfq ef group 1 byte-count 60
[Leaf2-if-range] qos wfq cs6 group sp
[Leaf2-if-range] qos wfq cs7 group sp
# 对队列6的报文进行流量整形,正常流速为12500000kbps(建议配置为接口带宽的一半)。
[Leaf2-if-range] qos gts queue 6 cir 12500000
[Leaf2-if-range] quit
# 进入批量接口配置视图,配置与Spine对接的接口。
[Leaf2] interface range HundredGigE 3/0/1 to HundredGigE 3/0/4
# 配置队列5的WRED平均长度的下限为600,平均长度的上限为2000,丢弃概率为20%。
[Leaf2-if-range] qos wred queue 5 low-limit 600 high-limit 2000 discard-probability 20
# 开启接口的WFQ队列,并按照每次轮询可发送的报文的字节数进行计算,配置队列5具有较高调度权重60,队列6、7采用严格优先级调度。
[Leaf2-if-range] qos wfq byte-count
[Leaf2-if-range] qos wfq ef group 1 byte-count 60
[Leaf2-if-range] qos wfq cs6 group sp
[Leaf2-if-range] qos wfq cs7 group sp
# 对队列6的报文进行流量整形,正常流速为50000000kbps(建议配置为接口带宽的一半)。
[Leaf2-if-range] qos gts queue 6 cir 50000000
[Leaf2-if-range] quit
![]()
对于S12500G-AF/S6850-G系列交换机,支持在接口视图配置WRED的各种参数。端口WRED方式可以只配置RoCE队列,不同接口可以配置不同的参数,使用更为灵活。对于支持该功能的产品和版本,推荐采用端口WRED方式。
(5) 配置AI ECN功能(S12500G-AF仅R8053Pxx及以上版本支持,本功能与静态ECN功能选择一种配置即可)
# 配置RoCEv2流量NetAnalysis功能的工作模式。为了保证能够正确分析RoCEv2流量,当同一个RDMA客户端和服务器端存在多条路径时,建议在客户端和服务器端接入的节点设备上均配置双向模式,在所有的中间节点设备上均配置单向模式。
[Leaf2] netanalysis rocev2 mode bidir
This operation will erase all the netanalysis configuration.
Continue?[Y/N]:y
# 开启RoCEv2流量的NetAnalysis统计功能。
[Leaf2] netanalysis rocev2 statistics global
# 开启RoCEv2流量的AI ECN功能。
[Leaf2] netanalysis rocev2 ai-ecn enable
# 配置AI ECN功能的模式为分布式模式。
[Leaf2] ai-service
[Leaf2-ai-service] ai ai-ecn enable mode distributed
# 开启队列5、6的AI ECN功能。
[Leaf2-ai-service] ai-ecn
[Leaf2-ai-service-ai-ecn] queue 5 enable
[Leaf2-ai-service-ai-ecn] queue 6 enable
[Leaf2-ai-service-ai-ecn] quit
[Leaf2-ai-service] quit
(6) 配置PFC功能和PFC死锁检测功能。
# 全局配置5队列的PFC死锁检测周期为10。
[Leaf2] priority-flow-control deadlock cos 5 interval 10
# 全局配置PFC死锁检测的精度为high。
[Leaf2] priority-flow-control deadlock precision high
# 使能内联口队列5的PFC功能。注意:仅框式设备需要配置
[Leaf2] priority-flow-control inner-port enable
# 配置内联口的5队列的PFC的反压帧触发门限为4000,反压帧停止门限与触发门限间的偏移量为51,Headroom缓存门限为3000,PFC预留门限为30。注意:仅框式设备需要配置
[Leaf2] priority-flow-control inner-port no-drop dot1p 5 ingress-buffer static 4000 ingress-threshold-offset 51 headroom 3000 reserved-buffer 30
# 进入批量接口配置视图,配置与业务服务器网卡对接的接口。
[Leaf2] interface range Twenty-FiveGigE 2/0/1 to Twenty-FiveGigE 2/0/8
# 开启与对端自动协商是否开启PFC功能。
[Leaf2-if-range] priority-flow-control auto
# 开启指定5队列的PFC功能。
[Leaf2-if-range] priority-flow-control no-drop dot1p 5
# 开启接口的PFC死锁检测功能。
[Leaf2-if-range] priority-flow-control deadlock enable
# 配置PFC的反压帧触发门限为3500,反压帧停止门限与触发门限间的偏移量为51,Headroom缓存门限为2000,PFC预留门限为30。
[Leaf2-if-range] priority-flow-control dot1p 5 headroom 2000
[Leaf2-if-range] priority-flow-control dot1p 5 reserved-buffer 30
[Leaf2-if-range] priority-flow-control dot1p 5 ingress-buffer static 3500
[Leaf2-if-range] priority-flow-control dot1p 5 ingress-threshold-offset 51
[Leaf2-if-range] quit
# 进入批量接口配置视图,配置与Spine对接的接口。
[Leaf2] interface range HundredGigE 3/0/1 to HundredGigE 3/0/4
# 开启与对端自动协商是否开启PFC功能。
[Leaf2-if-range] priority-flow-control auto
# 开启指定5队列的PFC功能。
[Leaf2-if-range] priority-flow-control no-drop dot1p 5
# 开启接口的PFC死锁检测功能。
[Leaf2-if-range] priority-flow-control deadlock enable
# 配置PFC的反压帧触发门限为4000,反压帧停止门限与触发门限间的偏移量为51,Headroom缓存门限为3000,PFC预留门限为30。
[Leaf2-if-range] priority-flow-control dot1p 5 headroom 3000
[Leaf2-if-range] priority-flow-control dot1p 5 reserved-buffer 30
[Leaf2-if-range] priority-flow-control dot1p 5 ingress-buffer static 4000
[Leaf2-if-range] priority-flow-control dot1p 5 ingress-threshold-offset 51
[Leaf2-if-range] quit
(7) 配置iNOF功能
# 全局使能iNOF功能,并进入iNOF视图。
[Leaf2] inof enable
[Leaf2-inof] quit
(1) 全局使能LLDP功能
# 全局使能LLDP功能。
<Spine1> system-view
[Spine1] lldp global enable
(2) VLAN和接口配置
# 创建VLAN。
[Spine1] vlan 101
[Spine1-vlan101] quit
# 创建vlan虚接口。
[Spine1] interface Vlan-interface 101
# 配置vlan虚接口地址,作为业务服务器RDMA网卡接口的网关。
[Spine1-Vlan-interface101] ip address 101.1.1.254 24
# 配置vlan虚接口mac地址。
[Spine1-Vlan-interface101] mac-address 0000-5e00-0001
[Spine1-Vlan-interface101] quit
# 进入批量接口配置视图,配置与存储网卡对接的接口。
[Spine1] interface range Twenty-FiveGigE 2/0/1 to Twenty-FiveGigE 2/0/8
# 将接口的链路类型修改为trunk。
[Spine1-if-range] port link-type trunk
# 禁止vlan 1通过这些trunk接口。
[Spine1-if-range] undo port trunk permit vlan 1
# 允许vlan 101通过这些trunk接口。
[Spine1-if-range] port trunk permit vlan 101
# 配置为stp edge-port。
[Spine1-if-range] stp edged-port
# 允许lldp发布dot1-tlv的tlv类型。
[Spine1-if-range] lldp tlv-enable dot1-tlv dcbx
# 端口信任802.1p优先级。
[Spine1-if-range] qos trust dot1p
[Spine1-if-range] quit
# 进入批量接口配置视图,配置与Leaf对接的接口。
[Spine1] interface range HundredGigE 3/0/1 to HundredGigE 3/0/4
# 将以太接口切换为三层工作模式。
[Spine1-if-range] port link-mode route
The configuration of the interface will be restored to the default. Continue? [Y
/N]:y
# 端口信任DSCP优先级。
[Spine1-if-range] qos trust dscp
[Spine1-if-range] quit
# 配置接口IP地址。
[Spine1] interface HundredGigE 3/0/1
[Spine1-HundredGigE3/0/1] ip address 172.16.24.2 30
[Spine1-HundredGigE3/0/1] quit
[Spine1] interface HundredGigE 3/0/2
[Spine1-HundredGigE3/0/2] ip address 172.16.24.6 30
[Spine1-HundredGigE3/0/2] quit
其它接口配置方法类似,后略。
(3) 配置BGP路由协议。
# 创建接口LoopBack 0。
[Spine1] interface LoopBack 0
# 配置LoopBack 0的IP,作为全局的Router ID
[Spine1-LoopBack0] ip address 92.1.1.1 32
[Spine1-LoopBack0] quit
# 配置全局Router ID
[Spine1] router-id 92.1.1.1
# 启动BGP实例default,指定该BGP实例的本地AS号,并进入BGP实例视图
[Spine1-bgp-default] bgp 65512
# 配置BGP的Router ID
[Spine1-bgp-default] router-id 92.1.1.1
# 将Leaf设备添加为对等体
[Spine1-bgp-default] peer 172.16.24.1 as-number 65512
[Spine1-bgp-default] peer 172.16.24.5 as-number 65512
…
# 进入BGP ipv4单播地址族视图
[Spine1-bgp-default] address-family ipv4 unicast
# 配置进行BGP负载分担的路由条数为16
[Spine1-bgp-default-ipv4] balance 16
# 发布Loopback0接口地址的路由。
[Spine1-bgp-default-ipv4] network 92.1.1.1 255.255.255.255
# 发布存储网卡接入网段的路由。
[Spine1-bgp-default-ipv4] network 101.1.1.0 255.255.255.0
# 发布与Leaf互联接口的网段路由
[Spine1-bgp-default-ipv4] network 172.16.24.0 255.255.255.252
[Spine1-bgp-default-ipv4] network 172.16.24.4 255.255.255.252
…
# 允许本地路由器与对等体交换路由信息,配置对等体为路由反射器的客户机。
[Spine1-bgp-default-ipv4] peer 172.16.24.1 enable
[Spine1-bgp-default-ipv4] peer 172.16.24.5 enable
[Spine1-bgp-default-ipv4] peer 172.16.24.1 reflect-client
[Spine1-bgp-default-ipv4] peer 172.16.24.5 reflect-client
…
[Spine1-bgp-default-ipv4] quit
# 进入BGP iNOF地址族视图。
[Spine1-bgp-default] address-family inof
# 配置Spine角色为反射器。
[Spine1-bgp-default-inof] role reflector
# 允许本地路由器与对等体交换路由信息,配置对等体为路由反射器的客户机。
[Spine1-bgp-default-inof] peer 172.16.24.1 enable
[Spine1-bgp-default-inof] peer 172.16.24.5 enable
[Spine1-bgp-default-inof] peer 172.16.24.1 reflect-client
[Spine1-bgp-default-inof] peer 172.16.24.5 reflect-client
…
[Spine1-bgp-default-inof]quit
[Spine1-bgp-default]quit
![]()
使用EBGP作为传递iNOF信息的路由协议时,iNOF地址族不需要配置role reflector,IPv4和iNOF地址族不需要配置peer {ipv4-address | ipv6-address } reflect-client。
(4) 配置静态ECN功能(本功能与AI ECN功能选择一种配置即可)
# 配置队列5和队列6最多可使用的共享区域的大小为100%。队列5为RDMA应用报文队列,队列6为CNP报文所在队列。
[Spine1] buffer egress cell queue 5 shared ratio 100
[Spine1] buffer egress cell queue 6 shared ratio 100
[Spine1] buffer apply
# 全局使能ECN拥塞标记功能。
[Spine1] qos wred ecn enable
# 创建WRED表,并进入WRED表视图
[Spine1] qos wred queue table ECN
# 配置WRED参数。注意:使用WRED表配置WRED参数时,推荐将非无损队列参数中的high-limit配置为可配置的最大值,low-limit配置为最大值减1,使其WRED功能和ECN功能实际不生效
[Spine1-wred-table-queue-ECN] queue 0 low-limit 69631 high-limit 69632
[Spine1-wred-table-queue-ECN] queue 1 low-limit 69631 high-limit 69632
[Spine1-wred-table-queue-ECN] queue 2 low-limit 69631 high-limit 69632
[Spine1-wred-table-queue-ECN] queue 3 low-limit 69631 high-limit 69632
[Spine1-wred-table-queue-ECN] queue 4 low-limit 69631 high-limit 69632
[Spine1-wred-table-queue-ECN] queue 6 low-limit 69631 high-limit 69632
[Spine1-wred-table-queue-ECN] queue 7 low-limit 69631 high-limit 69632
[Spine1-wred-table-queue-ECN] queue 5 low-limit 600 high-limit 2000 [Spine1-wred-table-queue-ECN] discard-probability 20
[Spine1-wred-table-queue-ECN] quit
# 设置内联口ECN参数.注意:仅框式设备需要配置
[Spine1] qos wred apply ECN fabric
# 进入批量接口配置视图,配置与存储网卡对接的接口。
[Spine1] interface range Twenty-FiveGigE 2/0/1 to Twenty-FiveGigE 2/0/8
# 配置队列5的WRED平均长度的下限为500,平均长度的上限为1200,丢弃概率为20%。
[Spine1-if-range] qos wred queue 5 low-limit 500 high-limit 1200 discard-probability 20
# 开启接口的WFQ队列,并按照每次轮询可发送的报文的字节数进行计算,配置队列5具有较高调度权重60,队列6、7采用严格优先级调度。
[Spine1-if-range] qos wfq byte-count
[Spine1-if-range] qos wfq ef group 1 byte-count 60
[Spine1-if-range] qos wfq cs6 group sp
[Spine1-if-range] qos wfq cs7 group sp
# 对队列6的报文进行流量整形,正常流速为12500000kbps(建议配置为接口带宽的一半)。
[Spine1-if-range] qos gts queue 6 cir 12500000
[Spine1-if-range] quit
# 进入批量接口配置视图,配置与Leaf对接的接口。
[Spine1] interface range HundredGigE 3/0/1 to HundredGigE 3/0/4
# 配置队列5的WRED平均长度的下限为600,平均长度的上限为2000,丢弃概率为20%。
[Spine1-if-range] qos wred queue 5 low-limit 600 high-limit 2000 discard-probability 20
# 开启接口的WFQ队列,并按照每次轮询可发送的报文的字节数进行计算,配置队列5具有较高调度权重60,队列6、7采用严格优先级调度。
[Spine1-if-range] qos wfq byte-count
[Spine1-if-range] qos wfq ef group 1 byte-count 60
[Spine1-if-range] qos wfq cs6 group sp
[Spine1-if-range] qos wfq cs7 group sp
# 对队列6的报文进行流量整形,正常流速为50000000kbps(建议配置为接口带宽的一半)。
[Spine1-if-range] qos gts queue 6 cir 50000000
[Spine1-if-range] quit
![]()
对于S12500G-AF/S6850-G系列交换机,支持在接口视图配置WRED的各种参数。端口WRED方式可以只配置RoCE队列,不同接口可以配置不同的参数,使用更为灵活。对于支持该功能的产品和版本,推荐采用端口WRED方式。
(5) 配置AI ECN功能(S12500G-AF仅R8053Pxx及以上版本支持,本功能与静态ECN功能选择一种配置即可)
# 配置RoCEv2流量NetAnalysis功能的工作模式。为了保证能够正确分析RoCEv2流量,当同一个RDMA客户端和服务器端存在多条路径时,建议在客户端和服务器端接入的节点设备上均配置双向模式,在所有的中间节点设备上均配置单向模式。
[Spine1] netanalysis rocev2 mode bidir
This operation will erase all the netanalysis configuration.
Continue?[Y/N]:y
# 开启RoCEv2流量的NetAnalysis统计功能。
[Spine1] netanalysis rocev2 statistics global
# 开启RoCEv2流量的AI ECN功能。
[Spine1] netanalysis rocev2 ai-ecn enable
# 配置AI ECN功能的模式为分布式模式。
[Spine1] ai-service
[Spine1-ai-service] ai ai-ecn enable mode distributed
# 开启队列5、6的AI ECN功能。
[Spine1-ai-service] ai-ecn
[Spine1-ai-service-ai-ecn] queue 5 enable
[Spine1-ai-service-ai-ecn] queue 6 enable
[Spine1-ai-service-ai-ecn] quit
[Spine1-ai-service] quit
(6) 配置PFC功能和PFC死锁检测功能。
# 全局配置5队列的PFC死锁检测周期为10。
[Spine1] priority-flow-control deadlock cos 5 interval 10
# 全局配置PFC死锁检测的精度为high。
[Spine1] priority-flow-control deadlock precision high
# 使能内联口队列5的PFC功能。注意:仅框式设备需要配置
[Spine1] priority-flow-control inner-port enable
# 配置内联口的5队列的PFC的反压帧触发门限为4000,反压帧停止门限与触发门限间的偏移量为51,Headroom缓存门限为3000,PFC预留门限为30。注意:仅框式设备需要配置
[Spine1] priority-flow-control inner-port no-drop dot1p 5 ingress-buffer static 4000 ingress-threshold-offset 51 headroom 3000 reserved-buffer 30
# 进入批量接口配置视图,配置与存储网卡对接的接口。
[Spine1] interface range Twenty-FiveGigE 2/0/1 to Twenty-FiveGigE 2/0/8
# 开启与对端自动协商是否开启PFC功能。
[Spine1-if-range] priority-flow-control auto
# 开启指定5队列的PFC功能。
[Spine1-if-range] priority-flow-control no-drop dot1p 5
# 开启接口的PFC死锁检测功能。
[Spine1-if-range] priority-flow-control deadlock enable
# 配置PFC的反压帧触发门限为3500,反压帧停止门限与触发门限间的偏移量为51,Headroom缓存门限为2000,PFC预留门限为30。
[Spine1-if-range] priority-flow-control dot1p 5 headroom 2000
[Spine1-if-range] priority-flow-control dot1p 5 reserved-buffer 30
[Spine1-if-range] priority-flow-control dot1p 5 ingress-buffer static 3500
[Spine1-if-range] priority-flow-control dot1p 5 ingress-threshold-offset 51
[Spine1-if-range] quit
# 进入批量接口配置视图,配置与Leaf对接的接口。
[Spine1] interface range HundredGigE 3/0/1 to HundredGigE 3/0/4
# 开启与对端自动协商是否开启PFC功能。
[Spine1-if-range] priority-flow-control auto
# 开启指定5队列的PFC功能。
[Spine1-if-range] priority-flow-control no-drop dot1p 5
# 开启接口的PFC死锁检测功能。
[Spine1-if-range] priority-flow-control deadlock enable
# 配置PFC的反压帧触发门限为4000,反压帧停止门限与触发门限间的偏移量为51,Headroom缓存门限为3000,PFC预留门限为30。
[Spine1-if-range] priority-flow-control dot1p 5 headroom 3000
[Spine1-if-range] priority-flow-control dot1p 5 reserved-buffer 30
[Spine1-if-range] priority-flow-control dot1p 5 ingress-buffer static 4000
[Spine1-if-range] priority-flow-control dot1p 5 ingress-threshold-offset 51
[Spine1-if-range] quit
(7) 配置iNOF功能
# 全局使能iNOF功能,并进入iNOF视图。
[Spine1] inof enable
# 将允许相互访问的iNOF主机加入到相同域中
[Spine1-inof] zone H1toS1
[Spine1-inof-zone-H1toS1] host 100.1.1.1
[Spine1-inof-zone-H1toS1] host 101.1.1.1
[Spine1-inof-zone-H1toS1] host 100.1.1.2
[Spine1-inof-zone-H1toS1] host 101.1.1.2
[Spine1-inof-zone-H1toS1] quit
[Spine1-inof] zone H2toS1
[Spine1-inof-zone-H2toS1] host 100.1.1.3
[Spine1-inof-zone-H2toS1] host 101.1.1.1
[Spine1-inof-zone-H2toS1] host 100.1.1.4
[Spine1-inof-zone-H2toS1] host 101.1.1.2
[Spine1-inof-zone-H2toS1] quit
[Spine1-inof] quit
(1) 全局使能LLDP功能
# 全局使能LLDP功能。
<Spine2> system-view
[Spine2] lldp global enable
(2) VLAN和接口配置
# 创建VLAN。
[Spine2] vlan 201
[Spine2-vlan201] quit
# 创建vlan虚接口。
[Spine2] interface Vlan-interface 201
# 配置vlan虚接口地址,作为业务服务器RDMA网卡接口的网关。
[Spine2-Vlan-interface101] ip address 201.1.1.254 24
# 配置vlan虚接口mac地址。
[Spine2-Vlan-interface101] mac-address 0000-5e00-0001
[Spine2-Vlan-interface101] quit
# 进入批量接口配置视图,配置与存储网卡对接的接口。
[Spine2] interface range Twenty-FiveGigE 2/0/1 to Twenty-FiveGigE 2/0/8
# 将接口的链路类型修改为trunk。
[Spine2-if-range] port link-type trunk
# 禁止vlan 1通过这些trunk接口。
[Spine2-if-range] undo port trunk permit vlan 1
# 允许vlan 201通过这些trunk接口。
[Spine2-if-range] port trunk permit vlan 201
# 配置为stp edge-port。
[Spine2-if-range] stp edged-port
# 允许lldp发布dot1-tlv的tlv类型。
[Spine2-if-range] lldp tlv-enable dot1-tlv dcbx
# 端口信任802.1p优先级。
[Spine2-if-range] qos trust dot1p
[Spine2-if-range] quit
# 进入批量接口配置视图,配置与Leaf对接的接口。
[Spine2] interface range HundredGigE 3/0/1 to HundredGigE 3/0/4
# 将以太接口切换为三层工作模式。
[Spine2-if-range] port link-mode route
The configuration of the interface will be restored to the default. Continue? [Y
/N]:y
# 端口信任DSCP优先级。
[Spine2-if-range] qos trust dscp
[Spine2-if-range] quit
# 配置接口IP地址。
[Spine2] interface HundredGigE 3/0/1
[Spine2-HundredGigE3/0/1] ip address 172.16.25.2 30
[Spine2-HundredGigE3/0/1] quit
[Spine2] interface HundredGigE 3/0/2
[Spine2-HundredGigE3/0/2] ip address 172.16.25.6 30
[Spine2-HundredGigE3/0/2] quit
其它接口配置方法类似,后略。
(3) 配置BGP路由协议。
# 创建接口LoopBack 0。
[Spine2] interface LoopBack 0
# 配置LoopBack 0的IP,作为全局的Router ID
[Spine2-LoopBack0] ip address 92.1.1.2 32
[Spine2-LoopBack0] quit
# 配置全局Router ID
[Spine2] router-id 92.1.1.2
# 启动BGP实例default,指定该BGP实例的本地AS号,并进入BGP实例视图
[Spine2-bgp-default] bgp 65513
# 配置BGP的Router ID
[Spine2-bgp-default] router-id 92.1.1.2
# 将Leaf设备添加为对等体
[Spine2-bgp-default] peer 172.16.25.1 as-number 65513
[Spine2-bgp-default] peer 172.16.25.5 as-number 65513
…
# 进入BGP ipv4单播地址族视图
[Spine2-bgp-default] address-family ipv4 unicast
# 配置进行BGP负载分担的路由条数为16
[Spine2-bgp-default-ipv4] balance 16
# 发布Loopback0接口地址的路由。
[Spine2-bgp-default-ipv4] network 92.1.1.2 255.255.255.255
# 发布存储网卡接入网段的路由。
[Spine2-bgp-default-ipv4] network 201.1.1.0 255.255.255.0
# 发布与Leaf互联接口的网段路由
[Spine2-bgp-default-ipv4] network 172.16.25.0 255.255.255.252
[Spine2-bgp-default-ipv4] network 172.16.25.4 255.255.255.252
…
# 允许本地路由器与对等体交换路由信息,配置对等体为路由反射器的客户机。
[Spine2-bgp-default-ipv4] peer 172.16.25.1 enable
[Spine2-bgp-default-ipv4] peer 172.16.25.5 enable
[Spine2-bgp-default-ipv4] peer 172.16.25.1 reflect-client
[Spine2-bgp-default-ipv4] peer 172.16.25.5 reflect-client
…
[Spine2-bgp-default-ipv4] quit
# 进入BGP iNOF地址族视图。
[Spine2-bgp-default] address-family inof
# 配置Spine角色为反射器。
[Spine2-bgp-default-inof] role reflector
# 允许本地路由器与对等体交换路由信息,配置对等体为路由反射器的客户机。
[Spine2-bgp-default-inof] peer 172.16.25.1 enable
[Spine2-bgp-default-inof] peer 172.16.25.5 enable
[Spine2-bgp-default-inof] peer 172.16.25.1 reflect-client
[Spine2-bgp-default-inof] peer 172.16.25.5 reflect-client
…
[Spine2-bgp-default-inof]quit
[Spine2-bgp-default]quit
![]()
使用EBGP作为传递iNOF信息的路由协议时,iNOF地址族不需要配置role reflector,IPv4和iNOF地址族不需要配置peer {ipv4-address | ipv6-address } reflect-client。
(4) 配置静态ECN功能(本功能与AI ECN功能选择一种配置即可)。
# 配置队列5和队列6最多可使用的共享区域的大小为100%。队列5为RDMA应用报文队列,队列6为CNP报文所在队列。
[Spine2] buffer egress cell queue 5 shared ratio 100
[Spine2] buffer egress cell queue 6 shared ratio 100
[Spine2] buffer apply
# 全局使能ECN拥塞标记功能。
[Spine2] qos wred ecn enable
# 创建WRED表,并进入WRED表视图。
[Spine1] qos wred queue table ECN
# 配置WRED参数。注意:使用WRED表配置WRED参数时,推荐将非无损队列参数中的high-limit配置为可配置的最大值,low-limit配置为最大值减1,使其WRED功能和ECN功能实际不生效。
[Spine1-wred-table-queue-ECN] queue 0 low-limit 69631 high-limit 69632
[Spine1-wred-table-queue-ECN] queue 1 low-limit 69631 high-limit 69632
[Spine1-wred-table-queue-ECN] queue 2 low-limit 69631 high-limit 69632
[Spine1-wred-table-queue-ECN] queue 3 low-limit 69631 high-limit 69632
[Spine1-wred-table-queue-ECN] queue 4 low-limit 69631 high-limit 69632
[Spine1-wred-table-queue-ECN] queue 6 low-limit 69631 high-limit 69632
[Spine1-wred-table-queue-ECN] queue 7 low-limit 69631 high-limit 69632
[Spine1-wred-table-queue-ECN] queue 5 low-limit 600 high-limit 2000 [Spine1-wred-table-queue-ECN] discard-probability 20
[Spine1-wred-table-queue-ECN] quit
# 设置内联口ECN参数.注意:仅框式设备需要配置。
[Spine1] qos wred apply ECN fabric
# 进入批量接口配置视图,配置与存储网卡对接的接口。
[Spine2] interface range Twenty-FiveGigE 2/0/1 to Twenty-FiveGigE 2/0/8
# 配置队列5的WRED平均长度的下限为500,平均长度的上限为1200,丢弃概率为20%。
[Spine2-if-range] qos wred queue 5 low-limit 500 high-limit 1200 discard-probability 20
# 开启接口的WFQ队列,并按照每次轮询可发送的报文的字节数进行计算,配置队列5具有较高调度权重60,队列6、7采用严格优先级调度。
[Spine2-if-range] qos wfq byte-count
[Spine2-if-range] qos wfq ef group 1 byte-count 60
[Spine2-if-range] qos wfq cs6 group sp
[Spine2-if-range] qos wfq cs7 group sp
# 对队列6的报文进行流量整形,正常流速为12500000kbps(建议配置为接口带宽的一半)。
[Spine2-if-range] qos gts queue 6 cir 12500000
[Spine2-if-range] quit
# 进入批量接口配置视图,配置与Leaf对接的接口。
[Spine2] interface range HundredGigE 3/0/1 to HundredGigE 3/0/4
# 配置队列5的WRED平均长度的下限为600,平均长度的上限为2000,丢弃概率为20%。
[Spine2-if-range] qos wred queue 5 low-limit 600 high-limit 2000 discard-probability 20
# 开启接口的WFQ队列,并按照每次轮询可发送的报文的字节数进行计算,配置队列5具有较高调度权重60,队列6、7采用严格优先级调度。
[Spine2-if-range] qos wfq byte-count
[Spine2-if-range] qos wfq ef group 1 byte-count 60
[Spine2-if-range] qos wfq cs6 group sp
[Spine2-if-range] qos wfq cs7 group sp
# 对队列6的报文进行流量整形,正常流速为50000000kbps(建议配置为接口带宽的一半)。
[Spine2-if-range] qos gts queue 6 cir 50000000
[Spine2-if-range] quit
![]()
对于S12500G-AF/S6850-G系列交换机,支持在接口视图配置WRED的各种参数。端口WRED方式可以只配置RoCE队列,不同接口可以配置不同的参数,使用更为灵活。对于支持该功能的产品和版本,推荐采用端口WRED方式。
(5) 配置AI ECN功能(S12500G-AF仅R8053Pxx及以上版本支持,本功能与静态ECN功能选择一种配置即可)。
# 配置RoCEv2流量NetAnalysis功能的工作模式。为了保证能够正确分析RoCEv2流量,当同一个RDMA客户端和服务器端存在多条路径时,建议在客户端和服务器端接入的节点设备上均配置双向模式,在所有的中间节点设备上均配置单向模式。
[Spine2] netanalysis rocev2 mode bidir
This operation will erase all the netanalysis configuration.
Continue?[Y/N]:y
# 开启RoCEv2流量的NetAnalysis统计功能。
[Spine2] netanalysis rocev2 statistics global
# 开启RoCEv2流量的AI ECN功能。
[Spine2] netanalysis rocev2 ai-ecn enable
# 配置AI ECN功能的模式为分布式模式。
[Spine2] ai-service
[Spine2-ai-service] ai ai-ecn enable mode distributed
# 开启队列5、6的AI ECN功能。
[Spine2-ai-service] ai-ecn
[Spine2-ai-service-ai-ecn] queue 5 enable
[Spine2-ai-service-ai-ecn] queue 6 enable
[Spine2-ai-service-ai-ecn] quit
[Spine2-ai-service] quit
(6) 配置PFC功能和PFC死锁检测功能。
# 全局配置5队列的PFC死锁检测周期为10。
[Spine2] priority-flow-control deadlock cos 5 interval 10
# 全局配置PFC死锁检测的精度为high。
[Spine2] priority-flow-control deadlock precision high
# 使能内联口队列5的PFC功能。注意:仅框式设备需要配置。
[Spine1] priority-flow-control inner-port enable
# 配置内联口的5队列的PFC的反压帧触发门限为4000,反压帧停止门限与触发门限间的偏移量为51,Headroom缓存门限为3000,PFC预留门限为30。注意:仅框式设备需要配置
[Spine1] priority-flow-control inner-port no-drop dot1p 5 ingress-buffer static 4000 ingress-threshold-offset 51 headroom 3000 reserved-buffer 30
# 进入批量接口配置视图,配置与存储网卡对接的接口。
[Spine2] interface range Twenty-FiveGigE 2/0/1 to Twenty-FiveGigE 2/0/8
# 开启与对端自动协商是否开启PFC功能。
[Spine2-if-range] priority-flow-control auto
# 开启指定5队列的PFC功能。
[Spine2-if-range] priority-flow-control no-drop dot1p 5
# 开启接口的PFC死锁检测功能。
[Spine2-if-range] priority-flow-control deadlock enable
# 配置PFC的反压帧触发门限为3500,反压帧停止门限与触发门限间的偏移量为51,Headroom缓存门限为2000,PFC预留门限为30。
[Spine2-if-range] priority-flow-control dot1p 5 headroom 2000
[Spine2-if-range] priority-flow-control dot1p 5 reserved-buffer 30
[Spine2-if-range] priority-flow-control dot1p 5 ingress-buffer static 3500
[Spine2-if-range] priority-flow-control dot1p 5 ingress-threshold-offset 51
[Spine2-if-range] quit
# 进入批量接口配置视图,配置与Leaf对接的接口。
[Spine2] interface range HundredGigE 3/0/1 to HundredGigE 3/0/4
# 开启与对端自动协商是否开启PFC功能。
[Spine2-if-range] priority-flow-control auto
# 开启指定5队列的PFC功能。
[Spine2-if-range] priority-flow-control no-drop dot1p 5
# 开启接口的PFC死锁检测功能。
[Spine2-if-range] priority-flow-control deadlock enable
# 配置PFC的反压帧触发门限为4000,反压帧停止门限与触发门限间的偏移量为51,Headroom缓存门限为3000,PFC预留门限为30。
[Spine2-if-range] priority-flow-control dot1p 5 headroom 3000
[Spine2-if-range] priority-flow-control dot1p 5 reserved-buffer 30
[Spine2-if-range] priority-flow-control dot1p 5 ingress-buffer static 4000
[Spine2-if-range] priority-flow-control dot1p 5 ingress-threshold-offset 51
[Spine2-if-range] quit
(7) 配置iNOF功能
# 全局使能iNOF功能,并进入iNOF视图。
[Spine2] inof enable
# 将允许相互访问的iNOF主机加入到相同域中。
[Spine2-inof] zone H1toS1
[Spine2-inof-zone-H1toS1] host 100.1.1.1
[Spine2-inof-zone-H1toS1] host 101.1.1.1
[Spine2-inof-zone-H1toS1] host 100.1.1.2
[Spine2-inof-zone-H1toS1] host 101.1.1.2
[Spine2-inof-zone-H1toS1] quit
[Spine2-inof] zone H2toS1
[Spine2-inof-zone-H2toS1] host 100.1.1.3
[Spine2-inof-zone-H2toS1] host 101.1.1.1
[Spine2-inof-zone-H2toS1] host 100.1.1.4
[Spine2-inof-zone-H2toS1] host 101.1.1.2
[Spine2-inof-zone-H2toS1] quit
[Spine2-inof] quit
· 查看接口WRED参数(ECN水线)配置
display qos wred interface
· 查看接口的PFC信息。
display priority-flow-control interface
· 查看设备所有接口丢包计数、ECN拥塞标记计数的汇总信息。
display packet-drop summary
· 查看接口丢包计数、ECN拥塞标记计数等信息。
display packet-drop interface
· 查看iNOF域的相关信息。
display inof configuration zone
· 查看iNOF网络中接入主机的信息。
display inof information host
如图所示:
· 分布式存储场景前端网络RDMA网络采用Spine、Leaf两级架构,Spine设备为S9825-64D,Leaf设备为S9855-24B8D。
· Leaf设备作为服务器的网关,Spine、Leaf之间为三层ECMP网络,每组Leaf采用不同网段的网关,通过OSPF或者BGP发布网段路由在进行数据高速转发的同时支持转发路径的冗余备份。
· 同一组Leaf设备的成员设备之间运行M-LAG(Multichassis Link Aggregation,跨设备链路聚合),双活设备之间使用200G端口互联,为了保证可靠性横穿链路至少2*200G,Peer-link上不配置PFC。
· Leaf配置双活网关,双活网关配置相同的IP和MAC。
· 计算节点服务器网卡采用bond4工作模式(动态聚合模式),存储节点服务器网卡采用多IP非bond模式。
现要求实现RDMA应用报文使用队列5进行无损传输。
![]()
· 本文以2台Spine设备、8台Leaf设备示例。实际应用中Spine层部署2台S9825-64D设备、Leaf层部署16台S9855-24B8D设备(上行口使用8*400G,下行口使用16*200G)可以实现收敛比1:1的RDMA网络。
· 服务器网卡使用bond4工作模式时,其接入交换机需要配置动态聚合。
图5-6 数据中心分布式存储场景前端网络RDMA/TCP融合组网图
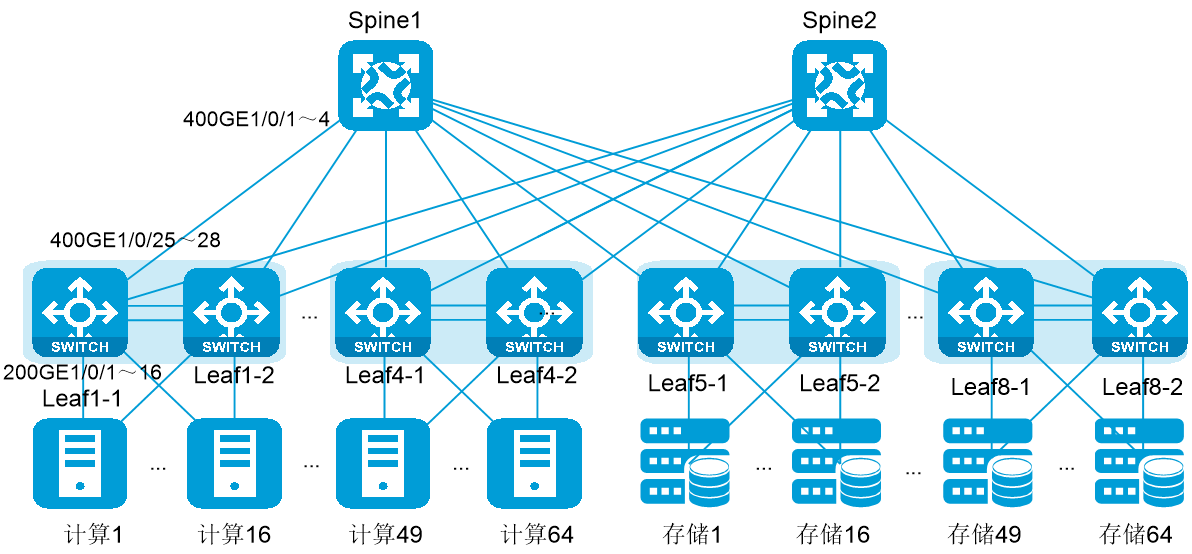
表5-7 接口和IP地址规划
|
设备 |
接口 |
IP地址 |
设备 |
接口 |
IP地址 |
|
Leaf1-1 |
200GE1/0/1~16 |
Vlan 100 |
Spine 1 |
400GE1/0/1 |
9.179.56.0/31 |
|
400GE1/0/25 |
9.179.56.1/31 |
… |
… |
||
|
… |
… |
400GE1/0/8 |
9.179.56.14/31 |
||
|
400GE1/0/28 |
9.179.56.7/31 |
400GE1/0/57 |
9.179.56.112/31 |
||
|
400GE1/0/29 |
9.179.56.129/31 |
… |
… |
||
|
… |
… |
400GE1/0/64 |
9.179.56.126/31 |
||
|
400GE1/0/32 |
9.179.56.135/31 |
|
|
||
|
200GE1/0/17~18 |
KeepAlive成员口 |
|
|
||
|
200GE1/0/19~20 |
Peer-Link成员口 |
|
|
||
|
Vlan-int100 |
9.179.64.1/26 |
|
|
||
|
Leaf1-2 |
200GE1/0/1~16 |
Vlan 100 |
Spine 2 |
400GE1/0/1 |
9.179.56.128/31 |
|
400GE1/0/25 |
9.179.56.9/31 |
… |
… |
||
|
… |
… |
400GE1/0/8 |
9.179.56.142/31 |
||
|
400GE1/0/28 |
9.179.56.15/31 |
400GE1/0/57 |
9.179.56.240/31 |
||
|
400GE1/0/29 |
9.179.56.137/31 |
… |
… |
||
|
… |
… |
400GE1/0/64 |
9.179.56.254/31 |
||
|
400GE1/0/32 |
9.179.56.143/31 |
|
|
||
|
200GE1/0/17~18 |
KeepAlive成员口 |
|
|
||
|
200GE1/0/19~20 |
Peer-Link成员口 |
|
|
||
|
Vlan-int100 |
9.179.64.1/26 |
|
|
||
|
Leaf 8-1 |
200GE1/0/1~16 |
Vlan 100 |
|
|
|
|
400GE1/0/25 |
9.179.56.113/31 |
|
|
|
|
|
… |
… |
|
|
|
|
|
400GE1/0/28 |
9.179.56.119/31 |
|
|
|
|
|
400GE1/0/29 |
9.179.56.241/31 |
|
|
|
|
|
… |
… |
|
|
|
|
|
400GE1/0/32 |
9.179.56.247/31 |
|
|
|
|
|
200GE1/0/17~18 |
KeepAlive成员口 |
|
|
|
|
|
200GE1/0/19~20 |
Peer-Link成员口 |
|
|
|
|
|
Vlan-int100 |
9.179.65.193/26 |
|
|
|
|
|
Leaf 8-2 |
200GE1/0/1~16 |
Vlan 100 |
|
|
|
|
400GE1/0/25 |
9.179.56.121/31 |
|
|
|
|
|
… |
… |
|
|
|
|
|
400GE1/0/28 |
9.179.56.127/31 |
|
|
|
|
|
400GE1/0/29 |
9.179.56.249/31 |
|
|
|
|
|
… |
… |
|
|
|
|
|
400GE1/0/32 |
9.179.56.255/31 |
|
|
|
|
|
200GE1/0/17~18 |
KeepAlive成员口 |
|
|
|
|
|
200GE1/0/19~20 |
Peer-Link成员口 |
|
|
|
|
|
Vlan-int100 |
9.179.65.193/26 |
|
|
|
![]()
Spine2端口编号规则与Spine1一样;Leaf1-2/8-1/8-2端口编号规则与Leaf1-1一样。为图形简洁起见,图中不再一一标注。
计算节点服务器网卡采用bond4工作模式,Leaf设备配置跨设备聚合口实现服务器双上行接入。
Leaf设备配置Monitor Link,当上行接口全部down时联动连接服务器的下行接口down,使流量可以切换至同组Leaf的另一台成员设备上,从而保护业务流量。因此,Leaf设备之间无需配置三层逃生链路。
服务器网卡采用多IP非bond模式,Leaf接入侧端口无需跨设备bond。
配置BGP路由协议。配置Spine设备的AS号为801。每组Leaf成员设备配置相同的AS号(本文配置为AS 5001、AS 5002…)。
为实现RDMA应用报文的无损传输,我们需要部署PFC功能和ECN功能:
· PFC功能基于优先级队列对报文进行流量控制。RDMA报文携带802.1P优先级5,我们对802.1P优先级为5的报文开启PFC功能。
RDMA报文转发路径的所有端口都需要配置PFC功能,因此我们在Spine设备与Leaf设备互连的端口、Leaf设备连接服务器的端口均开启PFC功能。
· ECN功能提供端到端的拥塞控制。设备检测到拥塞后,对报文的ECN域进行标记。接收端收到ECN标记的报文后,向发送端发送拥塞通知报文,使发送端降低流量发送速率。如果配置静态ECN功能,则在本例中,我们在Spine设备与Leaf设备互连的端口、Leaf设备连接服务器的端口均开启ECN功能。ECN功能配置的high-limit值(queue queue-id [ drop-level drop-level ] low-limit low-limit high-limit high-limit [ discard-probability discard-prob ])需要小于PFC反压帧触发门限值,以使ECN功能先生效。
配置PFC功能时,必须配置接口信任报文自带的802.1p优先级或DSCP优先级(qos trust { dot1p | dscp }),并且转发路径上所有端口的802.1p优先级与本地优先级映射关系以及DSCP优先级与802.1p优先级映射关系必须一致,否则PFC功能将无法正常工作。对于本组网中的二层或三层接口,建议配置接口信任报文自带的DSCP优先级(qos trust dscp)。
对于接收到的以太网报文,设备将根据优先级信任模式和报文的802.1Q标签状态,设备将采用不同的方式为其标记调度优先级。当设备连接不同网络时,所有进入设备的报文,其外部优先级字段(包括DSCP和IP)都被映射为802.1p优先级,再根据802.1p优先级映射为内部优先级;设备根据内部优先级进行队列调度的QoS处理。
关于优先级映射的详细介绍,请参见产品配套的“ACL和QoS配置指导”中的“优先级映射”。
(1) 配置Leaf1-1。
# 配置M-LAG的系统地址为0001-0001-0001。在开启M-LAG功能的一组设备上,M-LAG的系统MAC地址需要配置一致。
<Leaf1-1> system-view
[Leaf1-1] m-lag system-mac 1-1-1
# 配置M-LAG的系统优先级为123。在开启M-LAG功能的一组设备上,M-LAG的系统优先级需要配置一致。
[Leaf1-1] m-lag system-priority 123
# 配置M-LAG的系统编号为1。在开启M-LAG功能的一组设备上,不同设备上配置的M-LAG系统编号不能相同。
[Leaf1-1] m-lag system-number 1
# 创建路由聚合接口1,并配置该接口为动态聚合模式,绑定vpn实例kpl,加入物理成员口TwoHundredGigE 1/0/17、TwoHundredGigE 1/0/18。
[Leaf1-1] ip vpn-instance kpl
[Leaf1-1-vpn-instance-kpl] quit
[Leaf1-1] interface route-aggregation 1
[Leaf1-1-Route-Aggregation1] link-aggregation mode dynamic
[Leaf1-1-Route-Aggregation1] ip binding vpn-instance kpl
[Leaf1-1-Route-Aggregation1] ip address 192.1.1.1 24
[Leaf1-1-Route-Aggregation1] quit
[Leaf1-1] interface range TwoHundredGigE 1/0/17 TwoHundredGigE 1/0/18
[Leaf1-1-if-range] port link-mode route
[Leaf1-1-if-range] port link-aggregation group 1
[Leaf1-1-if-range] quit
[Leaf1-1] m-lag keepalive ip destination 192.1.1.2 source 192.1.1.1 vpn-instance kpl
# 创建二层聚合接口1000,并配置该接口为动态聚合模式,并配置该接口为peer-link接口,将物理端口TwoHundredGigE 1/0/19~20加入到聚合组1000中。
[Leaf1-1] interface bridge-aggregation 1000
[Leaf1-1-Bridge-Aggregation1000] link-aggregation mode dynamic
[Leaf1-1-Bridge-Aggregation1000] port m-lag peer-link 1
[Leaf1-1-Bridge-Aggregation1000] quit
[Leaf1-1] interface range TwoHundredGigE 1/0/19 to TwoHundredGigE 1/0/20
[Leaf1-1-if-range] port link-aggregation group 1000
[Leaf1-1-if-range] quit
(2) 配置Leaf1-2。
# 配置M-LAG的系统地址为0001-0001-0001。在开启M-LAG功能的一组设备上,M-LAG的系统MAC地址需要配置一致。
<Leaf1-2> system-view
[Leaf1-2] m-lag system-mac 1-1-1
# 配置M-LAG的系统优先级为123。在开启M-LAG功能的一组设备上,M-LAG的系统优先级需要配置一致。
[Leaf1-2] m-lag system-priority 123
# 配置M-LAG的系统编号为2。在开启M-LAG功能的一组设备上,不同设备上配置的M-LAG系统编号不能相同。
[Leaf1-2] m-lag system-number 2
# 创建路由聚合接口1,并配置该接口为动态聚合模式,绑定vpn实例kpl,加入物理成员口TwoHundredGigE 1/0/17、TwoHundredGigE 1/0/18。
[Leaf1-2] ip vpn-instance kpl
[Leaf1-2-vpn-instance-kpl] quit
[Leaf1-2] interface route-aggregation 1
[Leaf1-2-Route-Aggregation1] link-aggregation mode dynamic
[Leaf1-2-Route-Aggregation1] ip binding vpn-instance kpl
[Leaf1-2-Route-Aggregation1] ip address 192.1.1.2 24
[Leaf1-2-Route-Aggregation1] quit
[Leaf1-2] interface range TwoHundredGigE 1/0/17 TwoHundredGigE 1/0/18
[Leaf1-2-if-range] port link-mode route
[Leaf1-2-if-range] port link-aggregation group 1
[Leaf1-2-if-range] quit
[Leaf1-2] m-lag keepalive ip destination 192.1.1.1 source 192.1.1.2 vpn-instance kpl
# 创建二层聚合接口1000,并配置该接口为动态聚合模式,并配置该接口为peer-link接口,将物理端口TwoHundredGigE 1/0/19~20加入到聚合组1000中。
[Leaf1-2] interface bridge-aggregation 1000
[Leaf1-2-Bridge-Aggregation1000] link-aggregation mode dynamic
[Leaf1-2-Bridge-Aggregation1000] port m-lag peer-link 1
[Leaf1-2-Bridge-Aggregation1000] quit
[Leaf1-2] interface range TwoHundredGigE 1/0/19 to TwoHundredGigE 1/0/20
[Leaf1-2-if-range] port link-aggregation group 1000
[Leaf1-2-if-range] quit
(3) 配置Leaf 8-1/8-2。
配置与Leaf1-1/1-2类似,具体步骤略。
(1) 配置Leaf1-1。
# 创建Monitor Link组1,配置下行接口的回切延时为120秒。
<Leaf1-1> system-view
[Leaf1-1] monitor-link group 1
[Leaf1-1-mtlk-group1] downlink up-delay 120
[Leaf1-1-mtlk-group1] quit
# 配置所有上行Spine的接口为uplink口,所有下行服务器的接口为downlink口,以便Leaf设备上行口down时能够联动下行服务器的聚合成员口切换。
[Leaf1-1] interface range FourHundredGigE1/0/25 to FourHundredGigE1/0/32
[Leaf1-1-if-range] port monitor-link group 1 uplink
[Leaf1-1-if-range] quit
[Leaf1-1] interface range TwoHundredGigE1/0/1 to TwoHundredGigE1/0/16
[Leaf1-1-if-range] port monitor-link group 1 downlink
[Leaf1-1-if-range] quit
(2) 配置Leaf1-2/8-1/8-2。
Leaf1-2/8-1/8-2和Leaf1-1的配置相同,具体配置略。
(1) 配置Leaf1-1。
# 配置上行接口FourHundredGigE1/0/25~FourHundredGigE1/0/32工作在三层模式,并配置各接口的IP地址。
<Leaf1-1> system-view
[Leaf1-1] interface range FourHundredGigE1/0/25 to FourHundredGigE1/0/32
[Leaf1-1-if-range] link-mode route
[Leaf1-1-if-range] quit
[Leaf1-1] interface Fourhundredgige 1/0/25
[Leaf1-1-FourHundredGigE1/0/25] ip address 9.179.56.1 31
[Leaf1-1-FourHundredGigE1/0/25] quit
[Leaf1-1] interface Fourhundredgige 1/0/26
[Leaf1-1-FourHundredGigE1/0/26] ip address 9.179.56.3 31
[Leaf1-1-FourHundredGigE1/0/26] quit
[Leaf1-1] interface Fourhundredgige 1/0/27
[Leaf1-1-FourHundredGigE1/0/27] ip address 9.179.56.5 31
[Leaf1-1-FourHundredGigE1/0/27] quit
[Leaf1-1] interface Fourhundredgige 1/0/28
[Leaf1-1-FourHundredGigE1/0/28] ip address 9.179.56.7 31
[Leaf1-1-FourHundredGigE1/0/28] quit
[Leaf1-1] interface Fourhundredgige 1/0/29
[Leaf1-1-FourHundredGigE1/0/29] ip address 9.179.56.129 31
[Leaf1-1-FourHundredGigE1/0/29] quit
[Leaf1-1] interface Fourhundredgige 1/0/30
[Leaf1-1-FourHundredGigE1/0/30] ip address 9.179.56.131 31
[Leaf1-1-FourHundredGigE1/0/30] quit
[Leaf1-1] interface Fourhundredgige 1/0/31
[Leaf1-1-FourHundredGigE1/0/31] ip address 9.179.56.133 31
[Leaf1-1-FourHundredGigE1/0/31] quit
[Leaf1-1] interface Fourhundredgige 1/0/32
[Leaf1-1-FourHundredGigE1/0/32] ip address 9.179.56.135 31
[Leaf1-1-FourHundredGigE1/0/32] quit
(2) 配置Leaf1-2/8-1/8-2。
配置设备上行各接口工作在三层模式,并参考图5-6配置各接口的IP地址,具体步骤略。
(3) 配置Spine 1。
# 配置FourHundredGigE1/0/1~FourHundredGigE1/0/64工作在三层模式,并配置各接口的IP地址。
<Spine1> system-view
[Spine1] interface range FourHundredGigE1/0/1 to FourHundredGigE1/0/64
[Spine1-if-range] link-mode route
[Spine1-if-range] quit
[Spine1] interface Fourhundredgige 1/0/1
[Spine1-FourHundredGigE1/0/1] ip address 9.179.56.0 31
[Spine1-FourHundredGigE1/0/1] quit
[Spine1] interface Fourhundredgige 1/0/2
[Spine1-FourHundredGigE1/0/2] ip address 9.179.56.2 31
[Spine1-FourHundredGigE1/0/2] quit
[Spine1] interface Fourhundredgige 1/0/3
[Spine1-FourHundredGigE1/0/3] ip address 9.179.56.4 31
[Spine1-FourHundredGigE1/0/3] quit
[Spine1] interface Fourhundredgige 1/0/4
[Spine1-FourHundredGigE1/0/4] ip address 9.179.56.6 31
[Spine1-FourHundredGigE1/0/4] quit
[Spine1] interface Fourhundredgige 1/0/5
[Spine1-FourHundredGigE1/0/5] ip address 9.179.56.8 31
[Spine1-FourHundredGigE1/0/5] quit
[Spine1] interface Fourhundredgige 1/0/6
[Spine1-FourHundredGigE1/0/6] ip address 9.179.56.10 31
[Spine1-FourHundredGigE1/0/6] quit
[Spine1] interface Fourhundredgige 1/0/7
[Spine1-FourHundredGigE1/0/7] ip address 9.179.56.12 31
[Spine1-FourHundredGigE1/0/7] quit
[Spine1] interface Fourhundredgige 1/0/8
[Spine1-FourHundredGigE1/0/8] ip address 9.179.56.14 31
[Spine1-FourHundredGigE1/0/8] quit
[Spine1] interface Fourhundredgige 1/0/57
[Spine1-FourHundredGigE1/0/57] ip address 9.179.56.112 31
[Spine1-FourHundredGigE1/0/57] quit
[Spine1] interface Fourhundredgige 1/0/58
[Spine1-FourHundredGigE1/0/58] ip address 9.179.56.114 31
[Spine1-FourHundredGigE1/0/58] quit
[Spine1] interface Fourhundredgige 1/0/59
[Spine1-FourHundredGigE1/0/59] ip address 9.179.56.116 31
[Spine1-FourHundredGigE1/0/59] quit
[Spine1] interface Fourhundredgige 1/0/60
[Spine1-FourHundredGigE1/0/60] ip address 9.179.56.118 31
[Spine1-FourHundredGigE1/0/60] quit
[Spine1] interface Fourhundredgige 1/0/61
[Spine1-FourHundredGigE1/0/61] ip address 9.179.56.120 31
[Spine1-FourHundredGigE1/0/61] quit
[Spine1] interface Fourhundredgige 1/0/62
[Spine1-FourHundredGigE1/0/62] ip address 9.179.56.122 31
[Spine1-FourHundredGigE1/0/62] quit
[Spine1] interface Fourhundredgige 1/0/63
[Spine1-FourHundredGigE1/0/63] ip address 9.179.56.124 31
[Spine1-FourHundredGigE1/0/63] quit
[Spine1] interface Fourhundredgige 1/0/64
[Spine1-FourHundredGigE1/0/64] ip address 9.179.56.126 31
[Spine1-FourHundredGigE1/0/64] quit
(4) 配置Spine 2。
配置与Spine 1类似,请参考组网图所示的接口和IP地址进行配置,具体步骤略。
(1) 配置Leaf1-1。
# 创建VLAN 100,并配置IP地址及MAC地址,配置接入存储服务器的端口加入VLAN 100。
[Leaf1] vlan 100
[Leaf1] interface vlan-interface 100
[Leaf1-Vlan-interface100] ip address 9.179.64.1 26
[Leaf1-Vlan-interface100] mac-address 0000-5e00-0001
# 创建动态二层聚合接口1,将物理端口TwoHundredGigE 1/0/1加入聚合组1,并配置该接口为M-LAG接口1,配置二层聚合接口1链路类型为Trunk,允许VLAN 100通过,不允许VLAN 1通过,PVID为VLAN 100。
[Leaf1-1] interface bridge-aggregation 1
[Leaf1-1-Bridge-Aggregation1] link-aggregation mode dynamic
[Leaf1-1-Bridge-Aggregation1] quit
[Leaf1-1] interface TwoHundredGigE 1/0/1
[Leaf1-1-TwoHundredGigE1/0/1] port link-aggregation group 1
[Leaf1-1-TwoHundredGigE1/0/1] quit
[Leaf1-1] interface bridge-aggregation 1
[Leaf1-1-Bridge-Aggregation1] port m-lag group 1
[Leaf1-1-Bridge-Aggregation1] port link-type trunk
[Leaf1-1-Bridge-Aggregation1] undo port trunk permit vlan 1
[Leaf1-1-Bridge-Aggregation1] port trunk permit vlan 100
[Leaf1-1-Bridge-Aggregation1] port trunk pvid vlan 100
[Leaf1-1-Bridge-Aggregation1] quit
# 创建动态二层聚合接口2,将物理端口TwoHundredGigE 1/0/2加入聚合组2,并配置该接口为M-LAG接口2,配置二层聚合接口2链路类型为Trunk,允许VLAN 100通过,不允许VLAN 100通过,PVID为VLAN 100。
[Leaf1-1] interface bridge-aggregation 2
[Leaf1-1-Bridge-Aggregation2] link-aggregation mode dynamic
[Leaf1-1-Bridge-Aggregation2] quit
[Leaf1-1] interface TwoHundredGigE 1/0/2
[Leaf1-1-TwoHundredGigE1/0/2] port link-aggregation group 2
[Leaf1-1-TwoHundredGigE1/0/2] quit
[Leaf1-1] interface bridge-aggregation 2
[Leaf1-1-Bridge-Aggregation2] port m-lag group 2
[Leaf1-1-Bridge-Aggregation2] port link-type trunk
[Leaf1-1-Bridge-Aggregation2] undo port trunk permit vlan 1
[Leaf1-1-Bridge-Aggregation2] port trunk permit vlan 100
[Leaf1-1-Bridge-Aggregation2] port trunk pvid vlan 100
[Leaf1-1-Bridge-Aggregation2] quit
(2) 配置Leaf1-2。
Leaf1-2与Leaf1-1配置相同,具体步骤略。
(3) 配置Leaf 8-1。
# 创建VLAN 100,并配置IP地址及MAC地址,配置接入存储服务器的端口加入VLAN 100。
[Leaf8-1] vlan 100
[Leaf8-1] interface vlan-interface 100
[Leaf8-1-Vlan-interface100] ip address 9.179.65.193 26
[Leaf8-1-Vlan-interface100] mac-address 0000-5e00-0001
[Leaf8-1] interface range TwoHundredGigE 1/0/1 to TwoHundredGigE 1/0/16
[Leaf8-1-if-range] port access vlan 100
[Leaf8-1-if-range] quit
(4) 配置Leaf 8-2。
Leaf1-2与Leaf1-1配置相同,具体步骤略。
(1) 配置Leaf1-1。
# 配置loopback0。
<Leaf1-1> system-view
[Leaf1-1] interface loopback 0
[Leaf1-1-LoopBack0] ip address 1.1.1.1 255.255.255.255
[Leaf1-1-LoopBack0] quit
[Leaf1-1] router-id 1.1.1.1
# 启动BGP实例default,指定该BGP实例的本地AS号为5001,并进入BGP实例视图。
# 配置全局Router ID为1.1.1.1。
[Leaf1-1] bgp 5001
[Leaf1-1-bgp-default] router-id 1.1.1.1
# 创建EBGP对等体组Spine。
[Leaf1-1-bgp-default] group Spine external
[Leaf1-1-bgp-default] peer Spine as-number 801
# 配置向对等体组Spine发布同一路由的时间间隔为0。
[Leaf1-1-bgp-default] peer Spine route-update-interval 0
# 将Spine设备添加为对等体组Spine中的对等体。
[Leaf1-1-bgp-default] peer 9.179.56.0 group Spine
[Leaf1-1-bgp-default] peer 9.179.56.2 group Spine
[Leaf1-1-bgp-default] peer 9.179.56.4 group Spine
[Leaf1-1-bgp-default] peer 9.179.56.6 group Spine
[Leaf1-1-bgp-default] peer 9.179.56.128 group Spine
[Leaf1-1-bgp-default] peer 9.179.56.130 group Spine
[Leaf1-1-bgp-default] peer 9.179.56.132 group Spine
[Leaf1-1-bgp-default] peer 9.179.56.134 group Spine
# 进入BGP IPv4单播地址族视图。
[Leaf1-1-bgp-default] address-family ipv4 unicast
# 配置进行BGP负载分担的路由条数为32。
[Leaf1-1-bgp-default-ipv4] balance 32
# 配置BGP路由的优先级,EBGP路由的优先级为10,IBGP路由的优先级为100,本地产生的BGP路由的优先级为100。
[Leaf1-1-bgp-default-ipv4] preference 10 100 100
# 允许本地路由器与对等体组Spine交换路由信息,发布本地业务网段路由9.179.64.0/26。
[Leaf1-1-bgp-default-ipv4] peer Spine enable
[Leaf1-1-bgp-default-ipv4] network 9.179.64.0 255.255.255.192
[Leaf1-1-bgp-default-ipv4] quit
[Leaf1-1-bgp-default] quit
(2) 配置Leaf1-2。
# 配置loopback0。
<Leaf1-2> system-view
[Leaf1-2] interface loopback 0
[Leaf1-2-LoopBack0] ip address 1.1.1.2 255.255.255.255
[Leaf1-2-LoopBack0] quit
[Leaf1-2] router-id 1.1.1.2
# 启动BGP实例default,指定该BGP实例的本地AS号为5001,并进入BGP实例视图。
# 配置全局Router ID为1.1.1.2。
[Leaf1-2] bgp 5001
[Leaf1-2-bgp-default] router-id 1.1.1.2
# 创建EBGP对等体组Spine。
[Leaf1-2-bgp-default] group Spine external
[Leaf1-2-bgp-default] peer Spine as-number 801
# 配置向对等体组Spine发布同一路由的时间间隔为0。
[Leaf1-2-bgp-default] peer Spine route-update-interval 0
# 将Spine设备添加为对等体组Spine中的对等体。
[Leaf1-2-bgp-default] peer 9.179.56.8 group Spine
[Leaf1-2-bgp-default] peer 9.179.56.10 group Spine
[Leaf1-2-bgp-default] peer 9.179.56.12 group Spine
[Leaf1-2-bgp-default] peer 9.179.56.14 group Spine
[Leaf1-2-bgp-default] peer 9.179.56.120 group Spine
[Leaf1-2-bgp-default] peer 9.179.56.122 group Spine
[Leaf1-2-bgp-default] peer 9.179.56.124 group Spine
[Leaf1-2-bgp-default] peer 9.179.56.126 group Spine
# 进入BGP IPv4单播地址族视图。
[Leaf1-2-bgp-default] address-family ipv4 unicast
# 配置进行BGP负载分担的路由条数为32。
[Leaf1-2-bgp-default-ipv4] balance 32
# 配置BGP路由的优先级,EBGP路由的优先级为10,IBGP路由的优先级为100,本地产生的BGP路由的优先级为100。
[Leaf1-2-bgp-default-ipv4] preference 10 100 100
# 允许本地路由器与对等体组Spine交换路由信息,发布本地业务网段路由9.179.64.0/26。
[Leaf1-2-bgp-default-ipv4] peer Spine enable
[Leaf1-2-bgp-default-ipv4] network 9.179.64.0 255.255.255.192
[Leaf1-2-bgp-default-ipv4] quit
[Leaf1-2-bgp-default] quit
(3) 配置Leaf 8-1。
# 配置loopback0。
<Leaf 8-1> system-view
[Leaf8-1] interface loopback 0
[Leaf8-1-LoopBack0] ip address 1.1.8.1 255.255.255.255
[Leaf8-1-LoopBack0] quit
[Leaf8-1] router-id 1.1.8.1
# 启动BGP实例default,指定该BGP实例的本地AS号为5008,并进入BGP实例视图。
# 配置全局Router ID为1.1.8.1。
[Leaf8-1] bgp 5008
[Leaf8-1-bgp-default] router-id 1.1.8.1
# 创建EBGP对等体组Spine。
[Leaf8-1-bgp-default] group Spine external
[Leaf8-1-bgp-default] peer Spine as-number 801
# 配置向对等体组Spine发布同一路由的时间间隔为0。
[Leaf8-1-bgp-default] peer Spine route-update-interval 0
# 将Spine设备添加为对等体组Spine中的对等体。
[Leaf8-1-bgp-default] peer 9.179.56.112 group Spine
[Leaf8-1-bgp-default] peer 9.179.56.114 group Spine
[Leaf8-1-bgp-default] peer 9.179.56.116 group Spine
[Leaf8-1-bgp-default] peer 9.179.56.118 group Spine
[Leaf8-1-bgp-default] peer 9.179.56.240 group Spine
[Leaf8-1-bgp-default] peer 9.179.56.242 group Spine
[Leaf8-1-bgp-default] peer 9.179.56.244 group Spine
[Leaf8-1-bgp-default] peer 9.179.56.246 group Spine
# 进入BGP IPv4单播地址族视图。
[Leaf8-1-bgp-default] address-family ipv4 unicast
# 配置进行BGP负载分担的路由条数为32。
[Leaf8-1-bgp-default-ipv4] balance 32
# 配置BGP路由的优先级,EBGP路由的优先级为10,IBGP路由的优先级为100,本地产生的BGP路由的优先级为100。
[Leaf8-1-bgp-default-ipv4] preference 10 100 100
# 允许本地路由器与对等体组Spine交换路由信息,发布本地业务网段路由9.179.65.192/26。
[Leaf8-1-bgp-default-ipv4] peer Spine enable
[Leaf8-1-bgp-default-ipv4] network 9.179.65.192 255.255.255.192
[Leaf8-1-bgp-default-ipv4] quit
[Leaf8-1-bgp-default] quit
(4) 配置Leaf 8-2
# 配置loopback0。
<Leaf 8-2> system-view
[Leaf8-2] interface loopback 0
[Leaf8-2-LoopBack0] ip address 1.1.8.2 255.255.255.255
[Leaf8-2-LoopBack0] quit
[Leaf8-2] router-id 1.1.8.2
# 启动BGP实例default,指定该BGP实例的本地AS号为5008,并进入BGP实例视图。
# 配置全局Router ID为1.1.8.2。
[Leaf8-2] bgp 5008
[Leaf8-2-bgp-default] router-id 1.1.8.2
# 创建EBGP对等体组Spine。
[Leaf8-2-bgp-default] group Spine external
[Leaf8-2-bgp-default] peer Spine as-number 801
# 配置向对等体组Spine发布同一路由的时间间隔为0。
[Leaf8-2-bgp-default] peer Spine route-update-interval 0
# 将Spine设备添加为对等体组Spine中的对等体。
[Leaf8-2-bgp-default] peer 9.179.56.120 group Spine
[Leaf8-2-bgp-default] peer 9.179.56.122 group Spine
[Leaf8-2-bgp-default] peer 9.179.56.124 group Spine
[Leaf8-2-bgp-default] peer 9.179.56.126 group Spine
[Leaf8-2-bgp-default] peer 9.179.56.248 group Spine
[Leaf8-2-bgp-default] peer 9.179.56.250 group Spine
[Leaf8-2-bgp-default] peer 9.179.56.252 group Spine
[Leaf8-2-bgp-default] peer 9.179.56.254 group Spine
# 进入BGP IPv4单播地址族视图。
[Leaf8-2-bgp-default] address-family ipv4 unicast
# 配置进行BGP负载分担的路由条数为32。
[Leaf8-2-bgp-default-ipv4] balance 32
# 配置BGP路由的优先级,EBGP路由的优先级为10,IBGP路由的优先级为100,本地产生的BGP路由的优先级为100。
[Leaf8-2-bgp-default-ipv4] preference 10 100 100
# 允许本地路由器与对等体组Spine交换路由信息,发布本地业务网段路由9.179.65.192/26。
[Leaf8-2-bgp-default-ipv4] peer Spine enable
[Leaf8-2-bgp-default-ipv4] network 9.179.65.192 255.255.255.192
[Leaf8-2-bgp-default-ipv4] quit
[Leaf8-2-bgp-default] quit
(5) 配置Spine 1。
# 配置loopback0。
<Spine1> system-view
[Spine1] interface loopback 0
[Spine1-LoopBack0] ip address 100.100.100.100 255.255.255.255
[Spine1-LoopBack0] quit
[Spine1] router-id 100.100.100.100
# 启动BGP实例default,指定该BGP实例的本地AS号为801,并进入BGP实例视图。
<Spine1> system-view
[Spine1] bgp 801
# 配置全局Router ID为100.100.100.100。
[Spine1-bgp-default] router-id 100.100.100.100
# 配置设备在重启后延迟300秒发布路由更新消息。
[Spine1-bgp-default] bgp update-delay on-startup 300
# 创建EBGP对等体组LEAF1、LEAF8。
[Spine1-bgp-default] group LEAF1 external
[Spine1-bgp-default] peer LEAF1 as-number 5001
[Spine1-bgp-default] group LEAF8 external
[Spine1-bgp-default] peer LEAF8 as-number 5008
# 配置向对等体组LEAF发布同一路由的时间间隔为0。
[Spine1-bgp-default] peer LEAF1 route-update-interval 0
[Spine1-bgp-default] peer LEAF8 route-update-interval 0
# 将Leaf设备添加为对等体组LEAF1中的对等体。
[Spine1-bgp-default] peer 9.179.56.1 group LEAF1
[Spine1-bgp-default] peer 9.179.56.3 group LEAF1
[Spine1-bgp-default] peer 9.179.56.5 group LEAF1
[Spine1-bgp-default] peer 9.179.56.7 group LEAF1
[Spine1-bgp-default] peer 9.179.56.9 group LEAF1
[Spine1-bgp-default] peer 9.179.56.11 group LEAF1
[Spine1-bgp-default] peer 9.179.56.13 group LEAF1
[Spine1-bgp-default] peer 9.179.56.15 group LEAF1
# 将Leaf设备添加为对等体组LEAF2中的对等体。
[Spine1-bgp-default] peer 9.179.56.111 group LEAF1
[Spine1-bgp-default] peer 9.179.56.113 group LEAF1
[Spine1-bgp-default] peer 9.179.56.115 group LEAF1
[Spine1-bgp-default] peer 9.179.56.117 group LEAF1
[Spine1-bgp-default] peer 9.179.56.119 group LEAF1
[Spine1-bgp-default] peer 9.179.56.121 group LEAF1
[Spine1-bgp-default] peer 9.179.56.123 group LEAF1
[Spine1-bgp-default] peer 9.179.56.125 group LEAF1
# 进入BGP IPv4单播地址族视图。
[Spine1-bgp-default] address-family ipv4 unicast
# 配置进行BGP负载分担的路由条数为32。
[Spine1-bgp-default-ipv4] balance 32
# 配置BGP路由的优先级,EBGP路由的优先级为10,IBGP路由的优先级为100,本地产生的BGP路由的优先级为100。
[Spine1-bgp-default-ipv4] preference 10 100 100
# 允许本地路由器与对等体组LEAF交换路由信息。
[Spine1-bgp-default-ipv4] peer LEAF1 enable
[Spine1-bgp-default-ipv4] peer LEAF8 enable
[Spine1-bgp-default-ipv4] quit
[Spine1-bgp-default] quit
(6) 配置Spine 2。
Spine 2的配置与Spine 1类似,环回口地址为100.100.100.101,具体配置略。
(1) 配置Leaf1-1
# 配置队列5和队列6最多可使用的共享区域的大小为100%。队列5为RDMA应用报文队列,队列6为CNP报文所在队列。
[Leaf1-1] buffer egress cell queue 5 shared ratio 100
[Leaf1-1] buffer egress cell queue 6 shared ratio 100
[Leaf1-1] buffer apply
# 在下行口TwoHundredGigE1/0/1~TwoHundredGigE1/0/16上配置队列5的WRED平均长度的下限为1500,平均长度的上限为3000,丢弃概率为20%,计算平均队列的指数为0,并为队列5开启ECN功能。开启接口的WFQ队列,并按照每次轮询可发送的报文的字节数进行计算,配置队列5具有较高调度权重60,队列6、7采用严格优先级调度。对队列6的报文进行流量整形。正常流速为100000000kbps,突发流量为8000000bytes。
[Leaf1-1] interface range twohundredgige 1/0/1 to twohundredgige 1/0/16
[Leaf1-1-if-range] qos wred queue 5 low-limit 1500 high-limit 3000 discard-probability 20
[Leaf1-1-if-range] qos wred queue 5 weighting-constant 0
[Leaf1-1-if-range] qos wred queue 5 ecn
[Leaf1-1-if-range] qos wfq byte-count
[Leaf1-1-if-range] qos wfq ef group 1 byte-count 60
[Leaf1-1-if-range] qos wfq cs6 group sp
[Leaf1-1-if-range] qos wfq cs7 group sp
[Leaf1-1-if-range] qos gts queue 6 cir 100000000 cbs 8000000
[Leaf1-1-if-range] quit
# 在Peer-Link互连口上配置队列5的WRED平均长度的下限为1500,平均长度的上限为3000,丢弃概率为20%,计算平均队列的指数为0,并为队列5开启ECN功能。开启接口的WFQ队列,并按照每次轮询可发送的报文的字节数进行计算,配置队列5具有较高调度权重60,队列6、7采用严格优先级调度。对队列6的报文进行流量整形。正常流速为100000000kbps,突发流量为8000000bytes。
[Leaf1-1] interface range twohundredgige 1/0/19 to twohundredgige 1/0/20
[Leaf1-1-if-range] qos wred queue 5 low-limit 1500 high-limit 3000 discard-probability 20
[Leaf1-1-if-range] qos wred queue 5 weighting-constant 0
[Leaf1-1-if-range] qos wred queue 5 ecn
[Leaf1-1-if-range] qos wfq byte-count
[Leaf1-1-if-range] qos wfq ef group 1 byte-count 60
[Leaf1-1-if-range] qos wfq cs6 group sp
[Leaf1-1-if-range] qos wfq cs7 group sp
[Leaf1-1-if-range] qos gts queue 6 cir 100000000 cbs 8000000
[Leaf1-1-if-range] quit
# 在上行口FourHundredGigE1/0/25~FourHundredGigE1/0/32上配置队列5的WRED平均长度的下限为2100,平均长度的上限为5000,丢弃概率为20%,计算平均队列的指数为0,并为队列5开启ECN功能。开启接口的WFQ队列,并按照每次轮询可发送的报文的字节数进行计算,配置队列5具有较高调度权重60,队列6、7采用严格优先级调度。对队列6的报文进行流量整形。正常流速为200000000kbps,突发流量为16000000bytes。
[Leaf1-1] interface range fourhundredgige 1/0/25 to fourhundredgige 1/0/32
[Leaf1-1-if-range] qos wred queue 5 low-limit 2100 high-limit 5000 discard-probability 20
[Leaf1-1-if-range] qos wred queue 5 weighting-constant 0
[Leaf1-1-if-range] qos wred queue 5 ecn
[Leaf1-1-if-range] qos wfq byte-count
[Leaf1-1-if-range] qos wfq ef group 1 byte-count 60
[Leaf1-1-if-range] qos wfq cs6 group sp
[Leaf1-1-if-range] qos wfq cs7 group sp
[Leaf1-1-if-range] qos gts queue 6 cir 200000000 cbs 16000000
[Leaf1-1-if-range] quit
![]()
对于S9825系列、S9855系列交换机,支持在接口视图配置WRED的各种参数,并开启WRED功能(qos wred queue命令)。端口WRED方式可以只配置RoCE队列,不同接口可以配置不同的参数,使用更为灵活。对于支持该功能的产品和版本,推荐采用端口WRED方式。
(2) 配置Leaf1-2/8-1/8-2。
Leaf1-2/8-1/8-2和Leaf1-1的配置相同,具体配置略。
(3) 配置Spine 1。
# 配置队列5和队列6最多可使用的共享区域的大小为100%。
[Spine1] buffer egress cell queue 5 shared ratio 100
[Spine1] buffer egress cell queue 6 shared ratio 100
[Spine1] buffer apply
# 在接口FourHundredGigE1/0/1~FourHundredGigE1/0/64上配置队列5的WRED平均长度的下限为2100,平均长度的上限为5000,丢弃概率为20%,计算平均队列的指数为0,并为队列5开启ECN功能。开启接口的WFQ队列,并按照每次轮询可发送的报文字节数进行计算。配置队列5具有较高调度权重60,队列6、7采用严格优先级调度。对队列6的报文进行流量整形。正常流速为200000000kbps,突发流量为16000000bytes。
[Spine1] interface range fourhundredgige 1/0/1 to fourhundredgige 1/0/64
[Spine1-if-range] qos wred queue 5 low-limit 2100 high-limit 5000 discard-probability 20
[Spine1-if-range] qos wred queue 5 weighting-constant 0
[Spine1-if-range] qos wred queue 5 ecn
[Spine1-if-range] qos wfq byte-count
[Spine1-if-range] qos wfq ef group 1 byte-count 60
[Spine1-if-range] qos wfq cs6 group sp
[Spine1-if-range] qos wfq cs7 group sp
[Spine1-if-range] qos gts queue 6 cir 200000000 cbs 16000000
[Spine1-if-range] quit
![]()
对于S9825系列、S9855系列交换机,支持在接口视图配置WRED的各种参数,并开启WRED功能(qos wred queue命令)。端口WRED方式可以只配置RoCE队列,不同接口可以配置不同的参数,使用更为灵活。对于支持该功能的产品和版本,推荐采用端口WRED方式。
(4) 配置Spine 2。
Spine 2的配置与Spine 1相同,具体配置略。
(1) 配置Leaf1-1。
# 配置Headroom最大可用的cell资源为26000(Headroom最大可用资源按照设备各个ITM所有接口配置的headroom总和计算,如S9855设备共1个ITM,24个200G口(每个200G口Headroom门限为750),8个400G口(每个400G口Headroom门限为1000),则应配置为24*750+8*1000=26000)。
[Leaf1-1] priority-flow-control poolID 0 headroom 26000
# 配置PFC死锁检测周期为10,精度为high。
[Leaf1-1] priority-flow-control deadlock cos 5 interval 10
[Leaf1-1] priority-flow-control deadlock precision high
# 在下行口TwoHundredGigE1/0/1~TwoHundredGigE1/0/16上配置接口信任DSCP优先级。开启接口的PFC功能,并对802.1p优先级5开启PFC功能。开启接口的PFC死锁检测功能。配置接口物理连接up状态抑制时间为2秒。
[Leaf1-1] interface range twohundredgige 1/0/1 to twohundredgige 1/0/16
[Leaf1-1-if-range] qos trust dscp
[Leaf1-1-if-range] priority-flow-control enable
[Leaf1-1-if-range] priority-flow-control no-drop dot1p 5
[Leaf1-1-if-range] priority-flow-control deadlock enable
[Leaf1-1-if-range] link-delay up 2
[Leaf1-1-if-range] quit
# 在上行口FourHundredGigE1/0/25~FourHundredGigE1/0/32上配置接口信任报文自带的DSCP优先级。开启接口的PFC功能,并对802.1p优先级5开启PFC功能。开启接口的PFC死锁检测功能。配置接口物理连接up状态抑制时间为2秒。
[Leaf1-1] interface range fourhundredgige 1/0/25 to fourhundredgige 1/0/32
[Leaf1-1-if-range] qos trust dscp
[Leaf1-1-if-range] priority-flow-control enable
[Leaf1-1-if-range] priority-flow-control no-drop dot1p 5
[Leaf1-1-if-range] priority-flow-control deadlock enable
[Leaf1-1-if-range] link-delay up 2
[Leaf1-1-if-range] quit
# 配下行接口TwoHundredGigE1/0/1~TwoHundredGigE1/0/16的PFC门限值。
[Leaf1-1] interface range twohundredgige 1/0/1 to twohundredgige 1/0/16
[Leaf1-1-if-range] priority-flow-control no-drop dot1p 5 pause-threshold ratio 5 headroom 750 pause-threshold-offset 12 reserved-buffer 16
[Leaf1-1-if-range] quit
# 在上行口FourHundredGigE1/0/25~FourHundredGigE1/0/32上配置PFC门限值。
[Leaf1-1] interface range fourhundredgige 1/0/25 to fourhundredgige 1/0/32
[Leaf1-1-if-range] priority-flow-control no-drop dot1p 5 pause-threshold ratio 5 headroom 1000 pause-threshold-offset 12 reserved-buffer 16
[Leaf1-1-if-range] quit
(2) 配置Leaf1-2/8-1/8-2。
Leaf1-2/8-1/8-2与Leaf1-1配置相同,具体步骤略。
(3) 配置Spine 1。
# 配置Headroom最大可用的cell资源为32000(Headroom最大可用资源按照设备各个ITM所有接口配置的headroom总和计算,如S9825设备共两个ITM,每个ITM有32个400G接口(每个400G口Headroom门限为1000),则应配置为32*1000=32000)。
[Spine1] priority-flow-control poolID 0 headroom 32000
# 配置PFC死锁检测周期为10,精度为high。
[Spine1] priority-flow-control deadlock cos 5 interval 10
[Spine1] priority-flow-control deadlock precision high
# 在接口FourHundredGigE1/0/1~FourHundredGigE1/0/64上配置接口信任报文自带的DSCP优先级,开启接口的PFC功能,并对802.1p优先级5开启PFC功能。开启接口的PFC死锁检测功能。配置接口物理连接up状态抑制时间为2秒。
[Spine1] interface range fourhundredgige 1/0/1 to fourhundredgige 1/0/64
[Spine1-if-range] qos trust dscp
[Spine1-if-range] priority-flow-control enable
[Spine1-if-range] priority-flow-control no-drop dot1p 5
[Spine1-if-range] priority-flow-control deadlock enable
[Spine1-if-range] link-delay up 2
# 在接口FourHundredGigE1/0/1~FourHundredGigE1/0/64上配置PFC门限值。
[Spine1-if-range] priority-flow-control dot1p 5 headroom 1000
[Spine1-if-range] priority-flow-control dot1p 5 reserved-buffer 16
[Spine1-if-range] priority-flow-control dot1p 5 ingress-buffer dynamic 5
[Spine1-if-range] priority-flow-control dot1p 5 ingress-threshold-offset 12
[Spine1-if-range] quit
(4) 配置Spine 2。
Spine 2的配置与Spine 1相同,具体配置略。
2台Spine设备、42台Leaf设备连接4台服务器进行下面验证。
验证方式一:
· 验证条件:同VLAN连接的服务器多对多打流,报文长度为9000字节。
· 验证结果:流量没有丢包,速率稳定;ECN全程生效。
验证方式二:
· 验证条件:不同VLAN连接的服务器两两互发流量,报文长度为9000字节。
· 验证结果:流量没有丢包,速率稳定;ECN全程生效,偶尔触发PFC,总体还是ECN优先生效。
综上所述,RDMA流量全程无丢包;流量速率波动正常;ECN优于PFC生效控制流量速率。
如图所示:
· 分布式存储场景后端网络当前推荐单层组网。
· 分布式存储场景后端网络一般要求同一个二层域,端口加入同一个VLAN。
· Leaf设备为S9855-24B8D。Leaf设备的成员设备之间运行M-LAG(Multichassis Link Aggregation,跨设备链路聚合),双活设备之间使用400G端口互联,为了保证可靠性横穿链路至少2*400G,Peer-link上不配置PFC。
· 服务器网卡采用多IP非bond模式,Leaf接入侧端口也无需跨设备bond。
· 用户侧的流量切换依赖于应用层感知和调度,网络侧不涉及。
现要求实现RDMA应用报文使用队列5进行无损传输。
![]()
本文以2台Leaf设备示例。实际应用中Leaf层部署2台S9855-24B8D设备(下行口使用24*200G)。
图5-7 数据中心分布式存储场景后端网络RDMA组网图
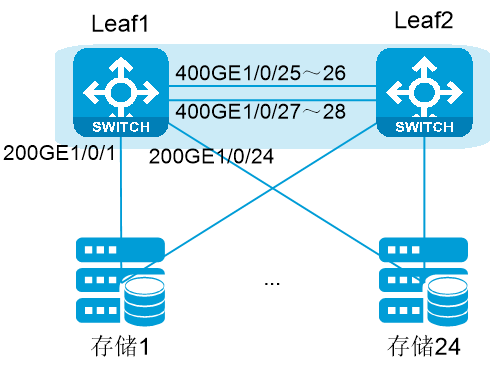
表5-8 接口IP地址规划
|
设备 |
接口 |
IP地址 |
设备 |
接口 |
IP地址 |
|
Leaf1 |
200GE1/0/1~24 |
Vlan 100 |
Leaf2 |
200GE1/0/1~24 |
Vlan 100 |
|
400GE1/0/25~26 |
KeepAlive成员口 |
400GE1/0/25~26 |
KeepAlive成员口 |
||
|
400GE1/0/27~28 |
Peer-Link成员口 |
400GE1/0/27~28 |
Peer-Link成员口 |
||
|
Vlan-int100 |
9.179.64.1/26 |
Vlan-int100 |
9.179.64.1/26 |
![]()
Leaf2端口编号规则与Leaf1一样。为图形简洁起见,图中不再一一标注。
Leaf设备配置M-LAG实现服务器双上行接入。
服务器网卡采用多IP非bond模式,Leaf接入侧端口也无需跨设备bond。
不涉及。
为实现RDMA应用报文的无损传输,我们需要部署PFC功能和ECN功能:
· PFC功能基于优先级队列对报文进行流量控制。RDMA报文携带802.1P优先级5,我们对802.1P优先级为5的报文开启PFC功能。
RDMA报文转发路径的所有端口都需要配置PFC功能,因此我们在Leaf设备互连的端口、Leaf设备连接服务器的端口均开启PFC功能。
· ECN功能提供端到端的拥塞控制。设备检测到拥塞后,对报文的ECN域进行标记。接收端收到ECN标记的报文后,向发送端发送拥塞通知报文,使发送端降低流量发送速率。如果配置静态ECN功能,则在本例中,我们在Leaf设备连接服务器的端口均开启ECN功能。ECN功能配置的high-limit值(queue queue-id [ drop-level drop-level ] low-limit low-limit high-limit high-limit [ discard-probability discard-prob ])需要小于PFC反压帧触发门限值,以使ECN功能先生效。
配置PFC功能时,必须配置接口信任报文自带的802.1p优先级或DSCP优先级(qos trust { dot1p | dscp }),并且转发路径上所有端口的802.1p优先级与本地优先级映射关系以及DSCP优先级与802.1p优先级映射关系必须一致,否则PFC功能将无法正常工作。对于本组网中的二层或三层接口,建议配置接口信任报文自带的DSCP优先级(qos trust dscp)。
对于接收到的以太网报文,设备将根据优先级信任模式和报文的802.1Q标签状态,设备将采用不同的方式为其标记调度优先级。当设备连接不同网络时,所有进入设备的报文,其外部优先级字段(包括DSCP和IP)都被映射为802.1p优先级,再根据802.1p优先级映射为内部优先级;设备根据内部优先级进行队列调度的QoS处理。
关于优先级映射的详细介绍,请参见产品配套的“ACL和QoS配置指导”中的“优先级映射”。
(1) 配置Leaf 1
# 配置M-LAG的系统地址为0001-0001-0001。在开启M-LAG功能的一组设备上,M-LAG的系统MAC地址需要配置一致。
<Leaf1> system-view
[Leaf1] m-lag system-mac 1-1-1
# 配置M-LAG的系统优先级为123。在开启M-LAG功能的一组设备上,M-LAG的系统优先级需要配置一致。
[Leaf1] m-lag system-priority 123
# 配置M-LAG的系统编号为1。在开启M-LAG功能的一组设备上,不同设备上配置的M-LAG系统编号不能相同。
[Leaf1] m-lag system-number 1
# 创建路由聚合接口1,并配置该接口为动态聚合模式,绑定vpn实例kpl,加入物理成员口FourHundredGigE 1/0/25、FourHundredGigE 1/0/26。
[Leaf1] ip vpn-instance kpl
[Leaf1-vpn-instance-kpl] quit
[Leaf1] interface route-aggregation 1
[Leaf1-Route-Aggregation1] link-aggregation mode dynamic
[Leaf1-Route-Aggregation1] ip binding vpn-instance kpl
[Leaf1-Route-Aggregation1] ip address 192.1.1.1 24
[Leaf1-Route-Aggregation1] quit
[Leaf1] interface range FourHundredGigE 1/0/25 FourHundredGigE 1/0/26
[Leaf1-if-range] port link-mode route
[Leaf1-if-range] port link-aggregation group 1
[Leaf1-if-range] quit
[Leaf1] m-lag keepalive ip destination 192.1.1.2 source 192.1.1.1 vpn-instance kpl
# 创建二层聚合接口1000,并配置该接口为动态聚合模式,并配置该接口为peer-link接口,将物理端口FourHundredGigE 1/0/27~28加入到聚合组1000中。
[Leaf1] interface bridge-aggregation 1000
[Leaf1-Bridge-Aggregation1000] link-aggregation mode dynamic
[Leaf1-Bridge-Aggregation1000] port m-lag peer-link 1
[Leaf1-Bridge-Aggregation1000] quit
[Leaf1] interface range FourHundredGigE 1/0/27 to FourHundredGigE 1/0/28
[Leaf1-if-range] port link-aggregation group 1000
[Leaf1-if-range] quit
(2) 配置Leaf 2
# 配置M-LAG的系统地址为0001-0001-0001。在开启M-LAG功能的一组设备上,M-LAG的系统MAC地址需要配置一致。
<Leaf2> system-view
[Leaf 2] m-lag system-mac 1-1-1
# 配置M-LAG的系统优先级为123。在开启M-LAG功能的一组设备上,M-LAG的系统优先级需要配置一致。
[Leaf 2] m-lag system-priority 123
# 配置M-LAG的系统编号为2。在开启M-LAG功能的一组设备上,不同设备上配置的M-LAG系统编号不能相同。
[Leaf 2] m-lag system-number 2
# 创建路由聚合接口1,并配置该接口为动态聚合模式,绑定vpn实例kpl,加入物理成员口FourHundredGigE 1/0/25、FourHundredGigE 1/0/26。
[Leaf 2] ip vpn-instance kpl
[Leaf2-vpn-instance-kpl] quit
[Leaf 2] interface route-aggregation 1
[Leaf2-Route-Aggregation1] link-aggregation mode dynamic
[Leaf2-Route-Aggregation1] ip binding vpn-instance kpl
[Leaf2-Route-Aggregation1] ip address 192.1.1.2 24
[Leaf2-Route-Aggregation1] quit
[Leaf 2] interface range FourHundredGigE 1/0/25 FourHundredGigE 1/0/26
[Leaf2-if-range] port link-mode route
[Leaf2-if-range] port link-aggregation group 1
[Leaf2-if-range] quit
[Leaf 2] m-lag keepalive ip destination 192.1.1.1 source 192.1.1.2 vpn-instance kpl
# 创建二层聚合接口1000,并配置该接口为动态聚合模式,并配置该接口为peer-link接口,将物理端口FourHundredGigE 1/0/27~28加入到聚合组1000中。
[Leaf 2] interface bridge-aggregation 1000
[Leaf2-Bridge-Aggregation1000] link-aggregation mode dynamic
[Leaf2-Bridge-Aggregation1000] port m-lag peer-link 1
[Leaf2-Bridge-Aggregation1000] quit
[Leaf 2] interface range FourHundredGigE 1/0/27 to FourHundredGigE 1/0/28
[Leaf2-if-range] port link-aggregation group 1000
[Leaf2-if-range] quit
(1) 配置Leaf 1
# 创建VLAN 100,并配置IP地址及MAC地址,配置接入存储服务器的端口加入VLAN 100。
[Leaf1] vlan 100
[Leaf1] interface vlan-interface 100
[Leaf1-Vlan-interface100] ip address 9.179.64.1 26
[Leaf1-Vlan-interface100] mac-address 0000-5e00-0001
[Leaf1] interface range TwoHundredGigE 1/0/1 to TwoHundredGigE 1/0/24
[Leaf1-if-range] port access vlan 100
[Leaf1-if-range] quit
(2) 配置Leaf 2
Leaf 2与Leaf 1配置相同,具体步骤略。
(1) 配置Leaf 1
# 配置队列5和队列6最多可使用的共享区域的大小为100%。队列5为RDMA应用报文队列,队列6为CNP报文所在队列。
[Leaf1] buffer egress cell queue 5 shared ratio 100
[Leaf1] buffer egress cell queue 6 shared ratio 100
[Leaf1] buffer apply
# 在下行口TwoHundredGigE1/0/1~TwoHundredGigE1/0/24上配置队列5的WRED平均长度的下限为1500,平均长度的上限为3000,丢弃概率为20%,计算平均队列的指数为0,并为队列5开启ECN功能。开启接口的WFQ队列,并按照每次轮询可发送的报文的字节数进行计算,配置队列5具有较高调度权重60,队列6、7采用严格优先级调度。对队列6的报文进行流量整形。正常流速为100000000kbps,突发流量为8000000bytes。
[Leaf1] interface range twohundredgige 1/0/1 to twohundredgige 1/0/24
[Leaf1-if-range] qos wred queue 5 low-limit 1500 high-limit 3000 discard-probability 20
[Leaf1-if-range] qos wred queue 5 weighting-constant 0
[Leaf1-if-range] qos wred queue 5 ecn
[Leaf1-if-range] qos wfq byte-count
[Leaf1-if-range] qos wfq ef group 1 byte-count 60
[Leaf1-if-range] qos wfq cs6 group sp
[Leaf1-if-range] qos wfq cs7 group sp
[Leaf1-if-range] qos gts queue 6 cir 100000000 cbs 8000000
[Leaf1-if-range] quit
# 在Peer-Link口FourHundredGigE1/0/27~FourHundredGigE1/0/28上配置队列5的WRED平均长度的下限为2100,平均长度的上限为5000,丢弃概率为20%,计算平均队列的指数为0,并为队列5开启ECN功能。开启接口的WFQ队列,并按照每次轮询可发送的报文的字节数进行计算,配置队列5具有较高调度权重60,队列6、7采用严格优先级调度。对队列6的报文进行流量整形。正常流速为200000000kbps,突发流量为16000000bytes。
[Leaf1] interface range fourhundredgige 1/0/27 to fourhundredgige 1/0/28
[Leaf1-if-range] qos wred queue 5 low-limit 2100 high-limit 5000 discard-probability 20
[Leaf1-if-range] qos wred queue 5 weighting-constant 0
[Leaf1-if-range] qos wred queue 5 ecn
[Leaf1-if-range] qos wfq byte-count
[Leaf1-if-range] qos wfq ef group 1 byte-count 60
[Leaf1-if-range] qos wfq cs6 group sp
[Leaf1-if-range] qos wfq cs7 group sp
[Leaf1-if-range] qos gts queue 6 cir 200000000 cbs 16000000
[Leaf1-if-range] quit
![]()
对于S9825系列、S9855系列交换机,支持在接口视图配置WRED的各种参数,并开启WRED功能(qos wred queue命令)。端口WRED方式可以只配置RoCE队列,不同接口可以配置不同的参数,使用更为灵活。对于支持该功能的产品和版本,推荐采用端口WRED方式。
(2) 配置Leaf 2
Leaf 2和Leaf 1的配置相同,具体配置略。
(1) 配置Leaf 1
# 配置Headroom最大可用的cell资源为26000(Headroom最大可用资源按照设备各个ITM所有接口配置的headroom总和计算,如S9855设备共1个ITM,24个200G口(每个200G口Headroom门限为750),8个400G口(每个400G口Headroom门限为1000),则应配置为24*750+8*1000=26000)。
[Leaf1] priority-flow-control poolID 0 headroom 26000
# 配置PFC死锁检测周期为10,精度为high。
[Leaf1] priority-flow-control deadlock cos 5 interval 10
[Leaf1] priority-flow-control deadlock precision high
# 在下行口TwoHundredGigE1/0/1~TwoHundredGigE1/0/24上配置接口信任DSCP优先级。开启接口的PFC功能,并对802.1p优先级5开启PFC功能。开启接口的PFC死锁检测功能。配置接口物理连接up状态抑制时间为2秒。
[Leaf1] interface range twohundredgige 1/0/1 to twohundredgige 1/0/24
[Leaf1-if-range] qos trust dscp
[Leaf1-if-range] priority-flow-control enable
[Leaf1-if-range] priority-flow-control no-drop dot1p 5
[Leaf1-if-range] priority-flow-control deadlock enable
[Leaf1-if-range] link-delay up 2
# 在下行口TwoHundredGigE1/0/1~TwoHundredGigE1/0/24上配置PFC门限值。
[Leaf1-if-range] priority-flow-control no-drop dot1p 5 pause-threshold ratio 5 headroom 750 pause-threshold-offset 12 reserved-buffer 16
[Leaf1-if-range] quit
(2) 配置Leaf 2
Leaf 2与Leaf 1配置相同,具体步骤略。
2台Leaf设备连接2台服务器进行下面验证。
验证方式一:
· 验证条件:同VLAN连接的服务器多对多打流,报文长度为9000字节。
· 验证结果:流量没有丢包,速率稳定;ECN全程生效。
验证方式二:
· 验证条件:同VLAN连接的服务器两两互发流量,报文长度为9000字节。
· 验证结果:流量没有丢包,速率稳定;ECN全程生效,有多次触发PFC,总体还是ECN优先生效。
综上所述,RDMA流量全程无丢包;流量速率波动正常;ECN优于PFC生效控制流量速率。
通常情况下,建议参考最佳实践/配置指导书组网,并采用PFC和ECN的推荐配置值。推荐值在一般的组网环境下是效果较好的参数组合,一般不需要调整。PFC和ECN的推荐值详见推荐值章节中的表格。
有些情况下,由于组网需求或网络中的设备、服务器存在特殊性,需要进一步调整参数时,请参考参数调整章节中的表格。
![]()
拆分的端口以拆分后的端口速率为准;插入低速光模块时,以低速光模块速率为准。
表6-1 S12500G-AF/S12500CR/S6850-G系列PFC门限推荐值
|
接口类型(下) |
Headroom缓存门限(cell) |
反压帧触发门限(cell) |
反压帧停止门限与触发门限间的偏移量(cell) |
PFC预留门限(cell) |
|
10G |
2000 |
3500 |
51 |
30 |
|
25G |
2000 |
3500 |
51 |
30 |
|
100G |
3000 |
4000 |
51 |
30 |
对于ECN功能,RoCE队列推荐使用表6-2的配置值,其他队列可按需配置较大的平均长度下限值和平均长度上限值。
表6-2 S12500G-AF/S12500CR/S6850-G系列ECN各门限推荐值
|
ECN门限(右) 接口类型(下) |
队列平均长度的下限 (单位为cell) |
队列平均长度的上限 (单位为cell) |
丢弃概率 |
|
10G |
500 |
1200 |
20 |
|
25G |
500 |
1200 |
20 |
|
100G |
600 |
2000 |
20 |
![]()
拆分的端口以拆分后的端口速率为准。
对于S9825&S9855设备,开启指定802.1p优先级的PFC功能后,设备会为PFC的各种门限设置一个缺省值,具体请参考表6-3此缺省值在一般的组网环境下是效果较好的参数组合,一般不建议调整。
表6-3 S9825&S9855 PFC门限缺省值和推荐值
|
PFC门限(右) 接口类型(下) |
Headroom缓存门限(cell) |
动态反压帧触发门限(%) |
反压帧停止门限与触发门限间的偏移量(cell) |
PFC预留门限(cell) |
|
100GE |
491 |
5 |
12 |
16 |
|
200GE |
750 |
5 |
12 |
16 |
|
400GE |
1000 |
5 |
12 |
16 |
对于ECN功能,RoCE队列推荐使用表6-4的配置值,其他队列可按需配置较大的平均长度下限值和平均长度上限值。
表6-4 S9825&S9855ECN各门限推荐值
|
PFC门限(右) 接口类型(下) |
队列平均长度的下限 (单位为cell) |
队列平均长度的上限 (单位为cell) |
丢弃概率 |
计算平均队列长度的指数 |
|
100GE |
1000 |
2000 |
20 |
0 |
|
200GE |
1500 |
3000 |
20 |
0 |
|
400GE |
2100 |
5000 |
20 |
0 |
确认服务器网卡是否支持和启用了PFC和ECN功能,并查看服务器的RoCE队列报文是否携带ECN标志位。
本文以Mellanox ConnectX-6 Lx网卡的配置作为示例。
需要注意的是:网卡配置在服务器重启和网卡重启后会失效,重启服务器或重启网卡后需要重新配置,建议将网卡配置写到服务器启动配置中,防止重启失效。
![]()
本节仅供参考,RDMA网卡的配置方式请以网卡及其适配服务器的资料为准。
|
项目 |
信息 |
|
网卡型号 |
Ethernet controller: Mellanox Technologies MT2894 Family [ConnectX-6 Lx] |
|
网卡驱动版本 |
MLNX_OFED_LINUX-5.4-3.2.7.2.3-rhel8.4-x86_64 |
|
网卡固件版本 |
driver: mlx5_core version: 5.4-3.2.7.2.3 firmware-version: 26.31.2006 (MT_0000000531) |
· 执行mst start命令开启MST(Mellanox Software Tools)服务。
· 执行mst status查看Mellanox设备状态信息。
· (可选)执行show_gids命令查看网卡名称、GID值、IP地址。
执行mlnx_qos -i ifname --trust dscp命令配置接口信任报文的DSCP优先级,ifname为网卡接口名称。
另外需要注意,网卡上设置的报文的DSCP值需要与设备上RoCE报文的DSCP优先级对应,即设备上开启PFC和ECN功能的802.1p优先级映射的DSCP优先级等于网卡发出报文的DSCP优先级。(不同的报文使用不同的QoS优先级,例如VLAN报文使用802.1p,IP报文使用DSCP。当二层报文从被转化为三层报文时,二层报文的802.1p优先级会被映射为IP报文使用的DSCP优先级,当三层报文被转化为二层报文时,IP报文使用的DSCP优先级会被映射为二层报文的802.1p优先级。关于优先级映射的详细介绍和缺省情况,请参见产品配套的QoS配置手册中的“优先级映射”)
步骤如下:
(1) 使用ethtool -i ifname bus-info命令查看接口的bus-info值。例如查看ens1f0接口的bus-info值执行ethtool -i ens1f0 bus-info,查询到ens1f0接口的bus-info为0000:86:00.0。
(2) 进入设置DSCP优先级的路径cd /sys/kernel/debug/mlx5/0000:86:00.0/cc_params
(3) 执行echo priority_value > np_cnp_dscp命令设置CNP报文的DSCP优先级,例如设置CNP报文的DSCP优先级为48执行echo 48 > np_cnp_dscp。
(4) 执行cat np_cnp_dscp命令查看CNP报文优先级是否修改成功。
执行mlnx_qos -i ifname -–pfc 0,1,2,3,4,5,6,7命令开启RoCE队列的PFC功能。ifname为网卡接口名称。0,1,2,3,4,5,6,7对应位置的值设置为0表示数值代表的优先级不开启PFC,设置为1表示数值代表的优先级开启PFC。
例如,开启接口ens1f0 802.1P优先级为5的报文的PFC命令为mlnx_qos -i ens1f0 --pfc 0,0,0,0,0,1,0,0。
执行mlnx_qos -i ifname命令可以查看接口PFC功能开启情况。值为1表示该优先级的报文开启PFC。
执行如下命令开启指定优先级报文的ECN功能:
· echo 1 > /sys/class/net/ifname/ecn/roce_np/enable/priority_value
· echo 1 > /sys/class/net/ifname/ecn/roce_rp/enable/priority_value
例如开启接口ens1f0优先级为5的报文的ECN功能执行:
· echo 1 > /sys/class/net/ens1f0/ecn/roce_np/enable/5
· echo 1 > /sys/class/net/ens1f0/ecn/roce_rp/enable/5
执行下面命令查看ECN是否开启成功,返回1表示开启成功,返回为0表示没有开启。
· cat /sys/class/net/ifname/ecn/roce_np/enable/priority_value
· cat /sys/class/net/ifname/ecn/roce_rp/enable/priority_value
在进行参数调整的过程中,配置如下PFC、QoS、数据缓冲区相关命令时可能会导致端口流量中断,请谨慎使用,或在专业人士指导下调整。
· buffer egress cell queue shared(配置本命令本身不丢包,执行buffer apply应用配置时可能导致丢包)
· buffer apply
· qos wred apply
· qos wrr weight
· qos wrr group weight
· qos wfq byte-count
· qos wfq queue-id group { 1 | 2 } byte-count
· priority-flow-control no-drop dot1p
· priority-flow-control dot1p headroom
· priority-flow-control dot1p ingress-buffer dynamic
· priority-flow-control dot1p ingress-buffer static
· priority-flow-control dot1p ingress-threshold-offset
· priority-flow-control dot1p reserved-buffer
# 查看接口HundredGigE2/0/1丢弃报文的信息。
<Sysname> display packet-drop interface HundredGigE 2/0/1
HundredGigE2/0/1:
Packets dropped due to full GBP or insufficient bandwidth: 0
Packets dropped due to Fast Filter Processor (FFP): 0
Packets dropped due to STP non-forwarding state: 0
Packets of ECN marked: 0
(1) 若出现insufficient bandwidth类型的丢包,但没有ECN marked计数,请首先检查此接口出现丢包的队列是否为预期无损队列。例如:
<Sysname> display qos queue-statistics interface HundredGigE 2/0/1 outbound
Interface: HundredGigE2/0/1
Direction: outbound
Forwarded: 0 packets, 0 bytes
Dropped: 0 packets, 0 bytes
...
Queue 5
Forwarded: 123 packets, 0 bytes, 0 pps, 0 bps
Dropped: 88 packets, 0 bytes
Current queue length: 123 packets
¡ 如果丢包队列和计数增长队列并非预期的无损队列,请检查流量入口的优先级信任模式是否正确:
<Sysname> display current-configuration interface HundredGigE 2/0/2
#
interface HundredGigE2/0/2
port link-mode bridge
qos trust dscp
#
¡ 如果流量入口的信任模式正确,请检查设备的qos map-table映射表是否正确。比如:
<Sysname> display qos map-table dscp-lp
MAP-TABLE NAME: dscp-lp TYPE: pre-define
IMPORT : EXPORT
0 : 0
1 : 0
...
¡ 如果流量仍不在预期的无损队列,请通过抓包确认网卡发送报文的DSCP/802.1p优先级是否正确。
(2) 如果丢包计数增长的队列是预期的无损队列,请检查对应接口的对应队列是否配置了WRED参数。例如:
<Sysname> display qos wred interface HundredGigE 2/0/1
Interface: HundredGigE2/0/1
Current WRED configuration:
QID gmin gmax gpro ymin ymax ypro rmin rmax rpro
--------------------------------------------------------------------------------
5 600 2000 20 600 2000 20 600 2000 20
(3) 如果此接口已经配置了WRED参数,请尝试在全局使能ECN功能。例如:
<sysname> system-view
[Sysname] qos wred ecn enable
注意:Ai-ECN配置与全局ECN配置互斥,配置方式请以产品或方案资料为准。
(4) 如果此时仍有insufficient bandwidth类型的丢包,需要检查队列出方向最大共享区域占用比是否配置为100%和是否执行了buffer apply命令。例如:
# 配置队列5在cell资源中的最大共享缓存占用比为100%并应用配置。
<sysname> system-view
[Sysname] buffer egress cell queue 5 shared ratio 100
[Sysname] buffer apply
(5) 如果此时insufficient bandwidth类型的丢包计数没有停止增长,且仍没有ECN marked计数,则需要通过抓包查看服务器发送的RoCE队列报文ECN标志位是否正确(01或10)。若不正确,请排查服务器网卡是否支持并启用了ECN功能。
(6) 如果此时insufficient bandwidth类型的丢包计数没有停止增长,但已有ECN marked计数,需要检查流量入口是否使能了PFC功能。例如:
<Sysname> display current-configuration interface HundredGigE 2/0/1
interface HundredGigE2/0/1
port link-mode bridge
priority-flow-control dot1p 5 ingress-buffer static 2000
priority-flow-control enable
priority-flow-control no-drop dot1p 5
(1) 如果ECN marked计数增长,但网络上仍存在丢包,请检查接口的PFC参数配置,建议调整为推荐参数。例如:
<Sysname> display current-configuration interface HundredGigE 2/0/1
interface HundredGigE2/0/1
port link-mode bridge
priority-flow-control dot1p 5 ingress-buffer static 2000
priority-flow-control enable
priority-flow-control no-drop dot1p 5
qos trust dscp
qos wred queue 5 drop-level 0 low-limit 600 high-limit 2000 discard-probability 20
qos wred queue 5 drop-level 1 low-limit 600 high-limit 2000 discard-probability 20
qos wred queue 5 drop-level 2 low-limit 600 high-limit 2000 discard-probability 20
(2) 如仍有丢包,可以检查当前设备、互连设备的PFC帧收发状态是否正确。例如:
<sysname> display priority-flow-control interface
Conf -- Configured mode Ne -- Negotiated mode P -- Priority
Interface Conf Ne Dot1pList P Recv Sent Inpps Outpps
HGE2/0/1 On On 5
HGE2/0/2 Off Off
(3) 如PFC帧有收发计数,可以增加流量入口端口Headroom缓存门限值的大小,直到不再出现丢包。例如:
# 配置Headroom缓存门限为4500。
<sysname> system-view
[Sysname] interface HundredGigE2/0/1
[Sysname-HundredGigE2/0/1] priority-flow-control dot1p 5 headroom 4500
(4) 如果Headroom调整至最大值仍然丢包,请排查服务器网卡是否支持并启用了PFC功能。
请联系产品的技术支持。
为了满足时延需求,在不丢包的情况下,可以调整ECN和PFC的部分参数,进而降低时延。调整时延会影响吞吐,可以认为的原则是:在拥塞网络环境下,占用的buffer越小,时延越低,吞吐量较小;占用的buffer越大,时延越大,吞吐量较大。请根据具体组网需求平衡时延和吞吐的关系。
不拥塞网络环境下,PFC和ECN等功能不生效。触发ECN、PFC后,报文转发降速。调整的原则是尽量在低buffer占用,不丢包的情况下触发ECN和PFC。建议优先调整ECN。
另外需要注意的是,参数调整还需要考虑服务器网卡的支持情况,包括网卡对PFC、ECN报文的响应机制,是否有PFC、ECN相关的特殊能力。例如有些网卡支持自降速功能(时延大的情况自动降速)。此时如果我们想要加大吞吐,但是调整后加大了时延,服务器自降速了,反而起到了和预期相反的效果。建议调整前先查阅服务器的相关资料,了解服务器网卡PFC、ECN功能的支持情况和相关功能,并在调整过程中实际验证调整是否合适。
可以调整WRED表中各队列的如下参数,控制时延与吞吐量:
· Low-limit(队列平均长度的下限)和high-limit(队列平均长度的上限):通过调低low-limit和high-limit值,可以更快的触发ECN标记,使时延更低,但可能会影响吞吐量。
· discard-probability(丢弃概率):在使能了ECN后,代表的是标记概率,该值越大,表示在上下限门限之间被标记的报文数越多。建议保持推荐值,仅在完成其他调整项后仍然无效的情况下再尝试调整。可以按照当前值20%的幅度进行调整。
配置举例:
# 配置队列5的WRED参数:队列平均长度的下限为800,队列平均长度的上限为1800。
<Sysname> system-view
[Sysname] interface HundredGigE 2/0/1
[Sysname-HundredGigE2/0/1] qos wred queue 5 low-limit 800 high-limit 1800
PFC是ECN后的一层屏障,保证设备不丢包。PFC一般不被触发,对时延影响不大,并且PFC门限调整过低会影响吞吐量,所以一般不建议调整。
但如果想进一步降低时延,可以尝试调整ingress-buffer参数(反压帧触发门限)。
![]()
需要注意的是,在设备有流量收发的情况下调整PFC参数可能会引起丢包。
(1) 减小ingress-buffer门限值,建议跟随WRED的high-limit门限进行调整(按当前值10%的幅度减小),但要保证该门限值大于WRED的high-limit门限值,保证设备优先触发ECN功能。
# 配置动态反压帧触发门限为3600(cell)。
<sysname> system-view
[Sysname] interface HundredGigE 2/0/1
[Sysname- HundredGigE 2/0/1] priority-flow-control dot1p 5 ingress-buffer static 3600
(2) 调整完成后,可以通过命令行多次查看接口的PFC信息,尽量保证设备上PFC的收发数量较少,即不触发或偶尔触发PFC。如果多次查看发现存在PFC报文收发,则表示ingress-buffer值配置过低,建议回调。
# 显示接口的PFC信息。
<Sysname> display priority-flow-control interface
Conf -- Configured mode Ne -- Negotiated mode P -- Priority
Interface Conf Ne Dot1pList P Recv Sent Inpps Outpps
HGE1/0/25 Auto On 0,2-3,5-6 0 178 43 12 15
在进行参数调整的过程中,配置如下PFC、QoS、数据缓冲区相关命令时会导致端口流量中断。
· buffer apply
· buffer egress cell queue shared(配置本命令本身不丢包,执行buffer apply应用配置时丢包)
· qos wrr weight
· qos wrr group weight
· qos wfq byte-count
· qos wfq queue-id group { 1 | 2 } byte-count
· priority-flow-control no-drop dot1p
· priority-flow-control dot1p headroom
· priority-flow-control dot1p ingress-buffer dynamic
· priority-flow-control dot1p ingress-buffer static
· priority-flow-control dot1p ingress-threshold-offset
· priority-flow-control dot1p reserved-buffer
查看接口HundredGigE1/0/25丢弃报文的信息。
<Sysname> display packet-drop interface hundredgige 1/0/25
HundredGigE1/0/25:
Packets dropped due to Fast Filter Processor (FFP): 0
Packets dropped due to Egress Filter Processor (EFP): : 0
Packets dropped due to STP non-forwarding state: 0
Packets dropped due to insufficient data buffer. Input dropped: 0 Output dropped: 0
Packets of ECN marked: 0
Packets of WRED droped: 0
(1) 若出现Input dropped类型的丢包,可以增加端口Headroom缓存门限值的大小,建议按照当前配置值的倍数进行调整,直到不再出现Input dropped类型的丢包。例如:
# 配置Headroom缓存门限为982。
<sysname> system-view
[Sysname] interface hundredgige 1/0/25
[Sysname-HundredGigE1/0/25] priority-flow-control dot1p 5 headroom 982
如果调整至最大值仍然丢包,请排查服务器网卡是否支持和启用PFC功能。
(2) 若出现Output dropped类型的丢包,需要检查队列出方向最大共享区域占用比是否配置为100%和是否执行了buffer apply命令。例如:
# 配置队列5在cell资源中的最大共享缓存占用比为100%并应用配置。
<sysname> system-view
[Sysname] buffer egress cell queue 5 shared ratio 100
[Sysname] buffer apply
如果出方向队列配置为100%后仍然有Output dropped类型的丢包,则可能存在组网或配置问题,请排查组网和配置问题或联系技术支持。
(1) 若出现WRED droped丢包,请查看RoCE队列的ECN功能是否已开启。
<Sysname> display qos wred table
Table name: 1
Table type: Queue based WRED
QID gmin gmax gprob ymin ymax yprob rmin rmax rprob exponent ECN
----------------------------------------------------------------------------
0 100 1000 10 100 1000 10 100 1000 10 9 N
1 100 1000 10 100 1000 10 100 1000 10 9 N
2 100 1000 10 100 1000 10 100 1000 10 9 N
3 100 1000 10 100 1000 10 100 1000 10 9 N
4 100 1000 10 100 1000 10 100 1000 10 9 N
5 100 1000 10 100 1000 10 100 1000 10 9 N
6 100 1000 10 100 1000 10 100 1000 10 9 N
7 100 1000 10 100 1000 10 100 1000 10 9 N
(2) 若RoCE队列的ECN功能未开启(显示信息中ECN字段显示为N),则需要开启RoCE队列的ECN功能。
<Sysname> system-view
[Sysname] interface hundredgige 1/0/25
[Sysname-HundredGigE1/0/25] qos wred queue 5 ecn
(3) 若RoCE队列的ECN功能开启后WRED类型的丢包继续增加,则需要查看服务器的RoCE队列报文是否携带ECN标志位。若未携带,请排查服务器网卡是否启用了PFC和ECN功能。
(4) 如果仍然存在丢包,请联系技术支持。
为了满足时延需求,在不丢包的情况下,可以调整ECN和PFC的部分参数,进而降低时延。调整时延会影响吞吐,可以认为的原则是:在拥塞网络环境下,占用的buffer越小,时延越低,吞吐量较小;占用的buffer越大,时延越大,吞吐量较大。请根据具体组网需求平衡时延和吞吐的关系。
不拥塞网络环境下,PFC和ECN等功能不生效。触发ECN、PFC后,报文转发降速。调整的原则是尽量在低buffer占用,不丢包的情况下触发ECN和PFC。建议优先调整ECN。
另外需要注意的是,参数调整还需要考虑服务器网卡的支持情况,包括网卡对PFC、ECN报文的响应机制,是否有PFC、ECN相关的特殊能力。例如有些网卡支持自降速功能(时延大的情况自动降速)。此时如果我们想要加大吞吐,但是调整后加大了时延,服务器自降速了,反而起到了和预期相反的效果。建议调整前先查阅服务器的相关资料,了解服务器网卡PFC、ECN功能的支持情况和相关功能,并在调整过程中实际验证调整是否合适。
可以调整WRED表中各队列的如下参数,控制时延与吞吐量:
· Low-limit(队列平均长度的下限)和high-limit(队列平均长度的上限):通过调低low-limit和high-limit值,可以更快的触发ECN标记,使时延更低,但可能会影响吞吐量。
· Weighting-constan(计算平均队列长度的指数):表示的是队列深度的计算方式,为0表示实时队列深度,对ECN的标记会更灵敏。平均队列长度的指数越大,计算平均队列长度时对队列的实时变化越不敏感。建议保持推荐值。仅在完成其他调整项后仍然无效的情况下再尝试调整。
· discard-probability(丢弃概率):在使能了ECN后,代表的是标记概率,该值越大,表示在上下限门限之间被标记的报文数越多。建议保持推荐值,仅在完成其他调整项后仍然无效的情况下再尝试调整。可以按照当前值20%的幅度进行调整。
配置举例:
# 配置队列5的WRED参数:队列平均长度的下限为800,队列平均长度的上限为1800。
<Sysname> system-view
[Sysname] qos wred queue table queue-table1
[Sysname-wred-table-queue-table1] queue 5 drop-level 0 low-limit 800 high-limit 1800
[Sysname-wred-table-queue-table1] queue 5 drop-level 1 low-limit 800 high-limit 1800
[Sysname-wred-table-queue-table1] queue 5 drop-level 2 low-limit 800 high-limit 1800
PFC是ECN后的一层屏障,保证设备不丢包。PFC一般不被触发,对时延影响不大,并且PFC门限调整过低会影响吞吐量,所以一般不建议调整。
但如果想进一步降低时延,可以尝试调整ingress-buffer参数(反压帧触发门限)。
![]()
需要注意的是,在设备有流量收发的情况下调整PFC门限会引起丢包。
(1) 减小ingress-buffer门限值,建议跟随WRED的high-limit门限进行调整(按当前值10%的幅度减小),但要保证该门限值大于WRED的high-limit门限值,保证设备优先触发ECN功能。
# 配置动态反压帧触发门限为4。
<sysname> system-view
[Sysname] interface hundredgige 1/0/25
[Sysname-HundredGigE1/0/25] priority-flow-control dot1p 5 ingress-buffer dynamic 4
(2) 调整完成后,可以通过命令行多次查看接口的PFC信息,尽量保证设备上PFC的收发数量较少,即不触发或偶尔触发PFC。如果多次查看发现存在PFC报文收发,则表示ingress-buffer值配置过低,建议回调。
# 显示接口的PFC信息。
<Sysname> display priority-flow-control interface
Conf -- Configured mode Ne -- Negotiated mode P -- Priority
Interface Conf Ne Dot1pList P Recv Sent Inpps Outpps
HGE1/0/25 Auto On 0,2-3,5-6 0 178 43 12 15
推荐使用AD-DC实现AI网络全程监控。AD-DC算网融合方案结合AI算法,大规模网络部署时间减少80%,智能选路最大化实现全网负载均衡降低30%网络延迟,整体提高50%模型训练率。
针对AI网络,AD-DC可实现如下功能:
· 训前巡检
网络、光模块、网卡、GPU主机健康状态全息感知。
· 训中跟踪
流量路径、拥塞控制、链路HASH情况实时监控。
· 训后分析
光链路、HASH不均告警、调优对比分析实现故障复盘。
无损网络SeerFabric无损网络方案为分布式存储、高性能计算等RoCEv2分布式应用提供“无损传输、低时延、高吞吐”的网络环境,满足分布式应用的高性能需求。
· RoCE自动化:自动化部署RoCE网络,简化上线部署时间。
· RoCE可视:拓扑可视、流量路径可视、时延可视、吞吐可视、拥塞可视。直观展示网络拓扑,叠加展示流量相关信息。业务流量拓扑直观可视,结合INT分析叠加展示时延精确信息
· RoCE分析:PFC死锁、风暴告警等异常状态查询,丢包原因、时间、内容等分析定位。
· RoCE调优:动态闭环调优。AI调优算法,调整ECN水线等保证无损传输和高吞吐。数据建模,仿真,预测。故障预测,故障分析闭环调优
图7-1 AD-DC支持为RoCE网络提供自动化、可视等丰富的功能

数据中心AI网络存在如下痛点
· 参数网规模大,连线复杂,部署工作量巨大,极易出错。
· 需要人工了解AI训练组网特点,并规划服务器和交换机配置,难度大,人力成本高。
· 环境调测需要进行连线检查、互通和性能测试,调测周期需要数天以上。
基于AD-DC,H3C的AIDC网络支持自动化部署,支持校验:
· 自动化部署:算网调度联动,控制器与分析器、主机Agent联动,感知网络与计算节点内部拓扑,自动化完成大规模参数网中设备和服务器的配置,减少人工投入70%,部署时间周级缩短到天级,实现全自动化生命周期管理,支持多租户隔离。
· 校验:部署完成后,支持参数网、算网拓扑展示,网络配置及连线校验,支持集合通信基础性能测试,在AI训练前,为客户完成全面测试。
图7-2 AD-DC功能架构
参数网自动化配置步骤如下:
(1) 意图采集:AD-DC自动采集多轨网络设备和服务器内GPU卡数目。
(2) 组网推荐:根据意图生成参数组网拓扑及配置,支持修改。
(3) 设备选择:选择Fabric内需要配置的设备
(4) 配置下发:自动发现设备下接入的服务器,并检查连线是否正确
(5) 结果展示:配置下发后,展示配置结果。
AD-DC支持丰富的开局验证测试功能:
· 性能测试功能:基于mpi的bench mark测试工具,用于提供全网连通性测试,测量时延及链路带宽承载情况。
· 用户可以根据需要选择相应的算子进行网络互通行测试,测试结果展示进行过的性能测试的历史记录。
· 流量测试工具:提供用于多个业务网卡进行一打一、多打一等典型场景下的性能测试工具,用于测量链路时延、流量带宽等。
· 用户可以根据需要选择相应的参数进行网络互通行测试,测试结果展示测试性能指标历史记录。并可以提供丰富的对比测试数据。
AD-DC提供端到端的整网分析、拥塞分析及AI ECN调优能力,涵盖交换机、服务器、网卡、GPU主机全栈数据采集,实现管理+可视+分析一站式解决方案。
AD-DC支持采集网络中的数据,对服务器数据、应用数据、网络状态、存储状态进行分析,配合INT功能分析流量时延信息,并且支持使用AI算法分析应用需求,智能调度ICT资源。
图7-3 AD-DC支持丰富的无损特性管理和运维能力
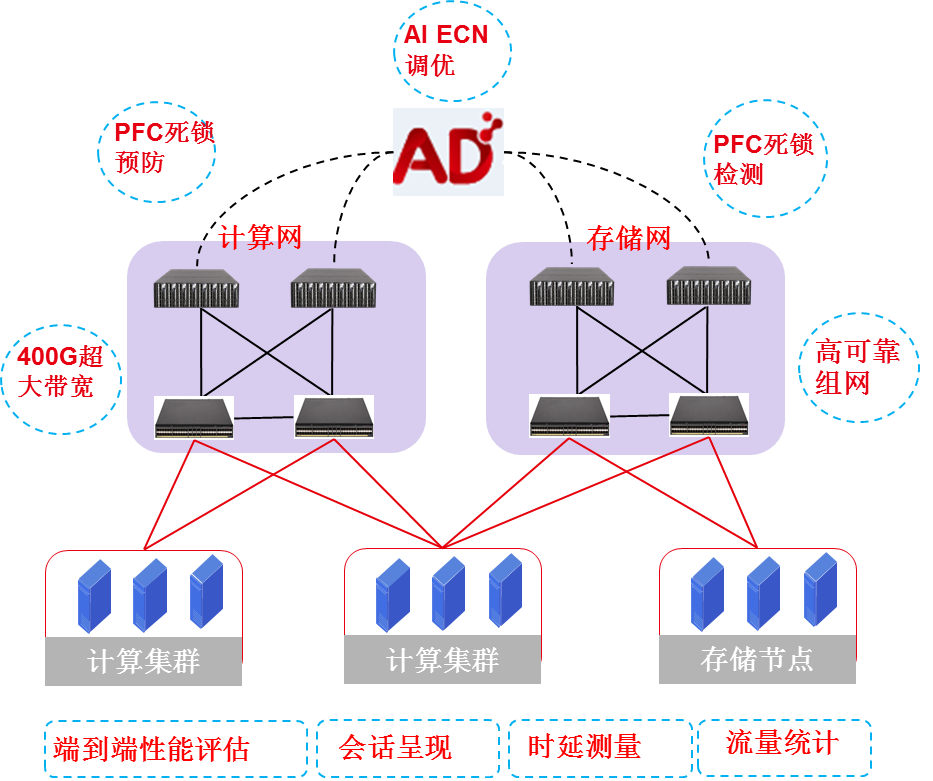
AD-DC支持RoCE网络的拓扑可视、业务可视以及流量状态可视:
· 拓扑可视:含网络、计算、存储端点整网拓扑及业务流量路径拓扑呈现。
· 业务可视:端到端业务流统计及流路径呈现,活跃会话识别及呈现。
· 状态可视:缓存可视、ECN、PFC帧统计及丢包可视。
多维度故障检测方案,可基于整网、设备、服务器维度自动检测连线故障,异常组网告警可视。
以设备维度展示参数网异常连线、错误配置(同一台设备下,一个服务器接入的GPU编号与其他服务器不同)。
图7-4 查看设备异常
以服务器维度展示参数网异常连线、错误配置(一个服务器多个GPU接入到同一个交换机下面)。
图7-5 查看服务器异常
基于gRPC、NETCONF等技术对物理网络层指标进行采集,实现设备、接口、队列、表项、光模块等指标的全面收集和监控,实时检测全网物理设备运行状态及时发现物理设备故障、物理资源状态异常等问题,并通过对表项资源及光模块等指标的预测,及时发现潜在风险。
图7-6 AD-DC支持RoCE流分析
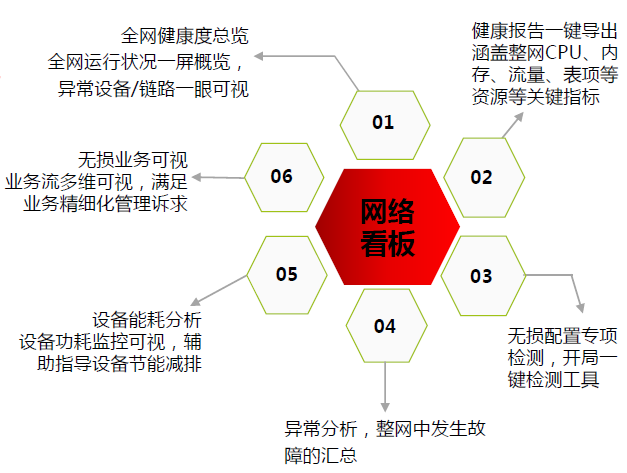
AD-DC通过对GPU服务器及网卡全栈数据的采集和统一处理整合,提供从服务器端到网络侧的综合数据分析能力。支持网络设备、GPU服务器、业务三个维度:
· 网络设备维度:支持对RoCE交换机设备指标进行分析。
图7-7 AD-DC支持分析RoCE交换机设备指标
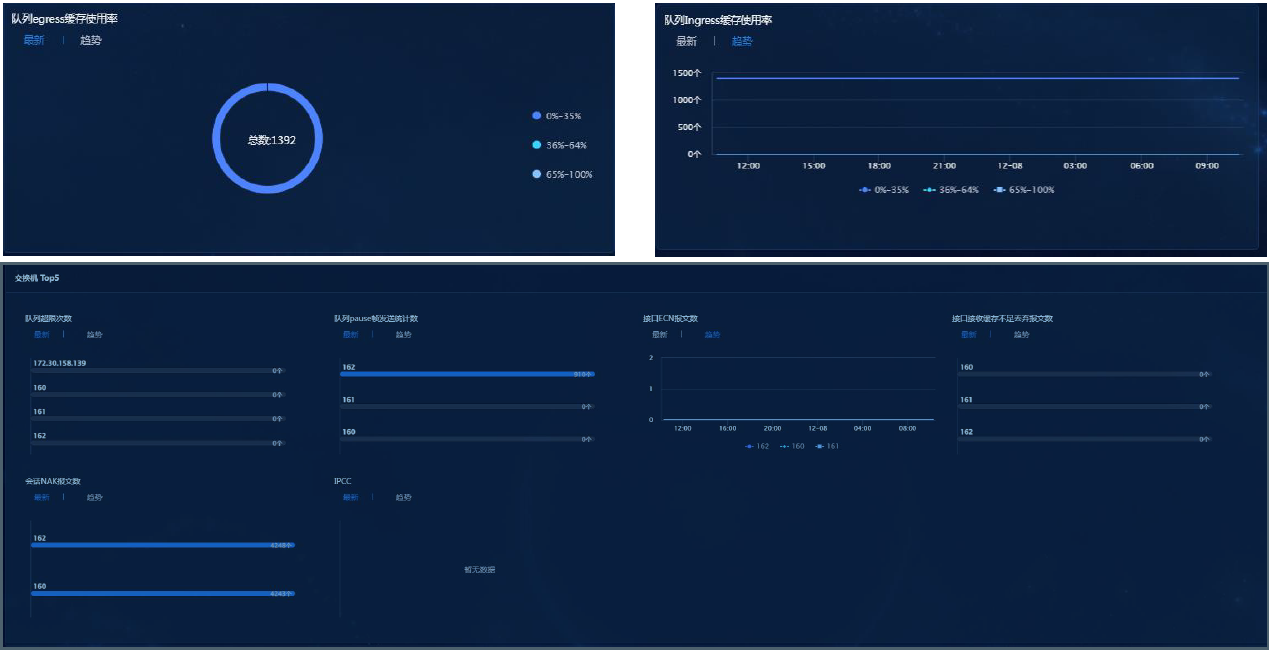
· GPU服务器维度:支持检查GPU硬件信息、查看上线失败告警。
图7-8 分析GPU服务器指标
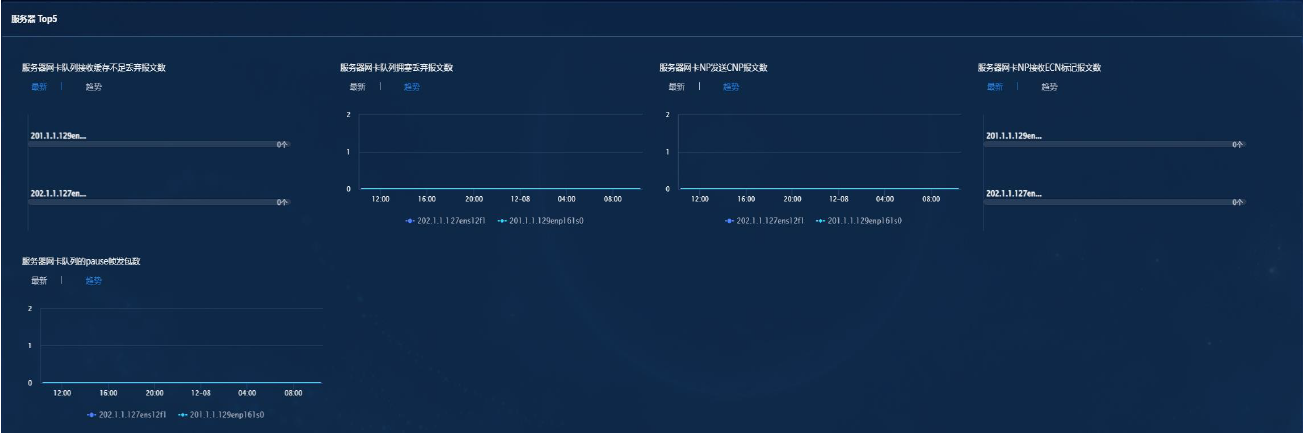
· 业务维度:支持对业务流路径和业务会话进行分析。
H3C支持AD-DC LBN方案:支持通过控制器自动识别连接服务器下行口,批量自动部署整网LBN,简化部署复杂度;支持通过分析器展示设备LBN的实际分担效果,支持对设备LBN分担效果进行分析。
图7-9 AD-DC支持批量自动部署整网LBN
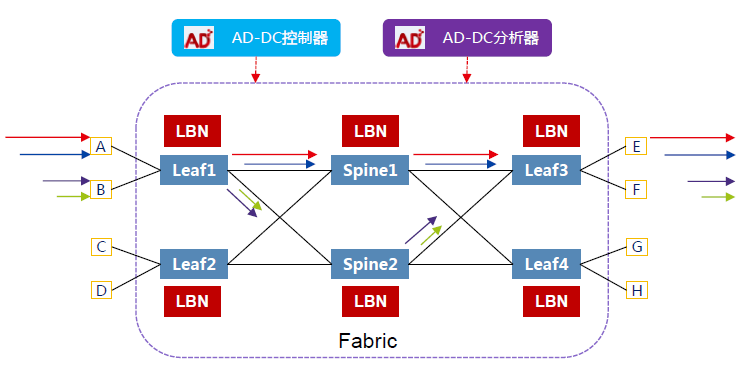
推荐光模块及线缆情况如下:
图8-1 推荐光模块及线缆
|
产品 |
光模块类型 |
推荐光模块 |
推荐线缆(AOC光缆,CAB/DAC电缆) |
|
S9825-64D S9855-48CD8D S9855-24B8D |
QSFP-DD |
400G QDDZR 80KM 400G QDD LR8/LR4 10KM 400G QDD FR4 2KM 400G QDD SR8 100M 400G QDD DR4 500M 400G QDD SR4 100M |
400G OSFP112-QSFPDD AOC 20/50M 400G QSFPDD-2*QSFP56一分二AOC 5/7/10/20/30/50M 400G QDD-4*QSFP56一分四 AOC 5/7/10/20M 400G QDD-QDD AOC 5/7/10/20/30/50M 400G 一分二 DAC 3m 400G 一分四 DAC 3m 400G 一对一 CAB 2m |
|
S9855-24B8D |
QSFP56 |
200G QSFP56 SR4 100M 200G QSFP56 FR4 2KM |
200G QSFP56-QSFP56 AOC 5/7/10/20M 200G QSFP56-2*QSFP56 一分二AOC 5/7/10/20/30/50M 200G 一对一 DAC 1/2/3M 200G 一分二 DAC 1/2/3M |
|
S9827-128DH |
QSFP112 |
400G QSFP112 VR4 50M 400G Q112 FR4 2KM 400G Q112 DR4 500KM |
400G OSFP112-Q112 AOC (SM/MM) 10/20/30/50M 400G Q112-Q112 AOC (SM/MM) 10/20/30/50M 400G Q112-2*Q112 一分二AOC (SM/MM) 10/20/30/50M 400G 一对一DAC 2M |
表8-1 200G/400G 端口拆分和降速方案
|
产品 |
原始端口形态 |
方式 |
200G端口 |
模块和线缆 |
100G端口 |
模块和线缆 |
|
S9825-64D |
64*400G QSFP-DD |
拆分 |
400G QSFP-DD支持拆分到2个200G QSFP56,最大支持128*200G |
QSFPDD-400G-SR8-MM850 QSFPDD-400G-2QSFP56-200G-AOC-20m |
400G QSFP-DD支持拆分到4个100G QSFP56或100G QSFP28,最大支持256*100G |
QSFPDD-400G-DR4-SM1310(可拆分到100G QSFP28端口) QSFP-100G-DR1-SM1310 QSFPDD-400G-4QSFP56-100G-AOC-20m(拆分到100G Q56端口) |
|
降速 |
400G QSFP-DD支持降速到1个200G QSFP56,最大支持64*200G |
QSFP56-200G-SR4-MM850 QSFP56-200G-D-AOC-20M |
400G QSFP-DD支持降速到1个100G QSFP28,最大支持64*100G |
QSFP-100G-SR4-MM850 QSFP-100G-D-AOC-20M |
||
|
S9827-128DH |
128*400G QSFP112 |
拆分 |
400G QSFP112支持拆分到2个200G Q112,最大支持256*200G |
QSFP112-400G-2QSFP112-200G-AOC-10/20/30/50m(M3) |
400G QSFP112支持拆分到4个100G QSFP28,最大支持512*100G(Q2) |
QSFP112-400G-DR4-SM1310(可拆分到100G QSFP28端口) QSFP-100G-DR1-SM1310 |
|
降速 |
400G QSFP-DD支持降速到1个200G QSFP56,最大支持128*200G |
QSFP56-200G-SR4-MM850(Q2) QSFP56-200G-D-AOC-20M(Q2) |
400G QSFP112支持降速到1个100G QSFP28,最大支持128*100G(Q2) |
QSFP-100G-SR4-MM850 QSFP-100G-D-AOC-20M |
||
|
S9855-24B8D |
24*200G QSFP56+8*400G QSFP-DD |
拆分 |
400G QSFP-DD支持拆分到2个200G QSFP56,最大支持40*200G |
QSFPDD-400G-SR8-MM850 QSFP56-200G-FR4-WDM1300 QSFPDD-400G-2QSFP56-200G-AOC-20m |
400G QSFP-DD支持拆分到4个100G QSFP56,200G QSFP56支持拆分到2个100G QSFP56最大支持64*100G QSFP28 |
QSFPDD-400G-4QSFP56-100G-AOC-20m(Q2) QSFP56-200G-2QSFP56-100G-AOC-20m |
|
降速 |
400G QSFP-DD支持降速到1个200G QSFP56,最大支持32*200G |
QSFP56-200G-SR4-MM850 QSFP56-200G-FR4-WDM1300 QSFP56-200G-D-AOC-20M |
400G QSFP-DD支持降速到1个100G QSFP28,200G QSFP56支持降速到一个100G QSFP28最大支持32*100G QSFP28 |
QSFP-100G-SR4-MM850 QSFP-100G-D-AOC-20M |
||
|
S9820-8C |
32*400G QSFP-DD |
拆分 |
400G QSFP-DD支持拆分到2个200G QSFP56,最大支持64*200G |
QSFPDD-400G-SR8-MM850 QSFPDD-400G-2QSFP56-200G-AOC-20m |
无需拆分,现有100G子卡可满足 |
- |
|
降速 |
400G QSFP-DD支持降速到1个200G QSFP56,最大支持32*200G |
QSFP56-200G-SR4-MM850 QSFP56-200G-D-AOC-20M |
无需降速,现有100G子卡可满足 |
- |
||
|
S9855-40B |
40*200G QSFP56 |
拆分 |
- |
- |
200G QSFP56支持拆分到2个100G QSFP56最大支持80*100G QSFP28(M3) |
QSFP56-200G-2QSFP56-100G-AOC-20m |
|
降速 |
- |
- |
200G QSFP56支持降速到一个100G QSFP28最大支持40*100G QSFP28(M3) |
QSFP-100G-SR4-MM850 QSFP-100G-D-AOC-20M |
||
|
S9825-128B |
128*200G QSFP56 |
拆分 |
- |
- |
200G QSFP56支持拆分到2个100G QSFP56最大支持256*100G QSFP28(Q2) |
QSFP56-200G-2QSFP56-100G-AOC-20m |
|
降速 |
- |
- |
200G QSFP56支持降速到一个100G QSFP28最大支持128*100G QSFP28(Q2) |
QSFP-100G-SR4-MM850 QSFP-100G-D-AOC-20M |
建议客户使用DSP光模块,或经过H3C验证测试的CDR光模块。
建议客户使用DSP光模块,或经过H3C验证测试的CDR光模块。
机房新建、改造之后,需要做严格的粉尘清除。
建议将网卡固件升级到最新版本。
建议将网卡固件升级到最新版本。
推荐的RoCE参数一般能适应大部分项目场景,若发现有丢包记录,需要原厂专家微调参数。
我们希望流量能较为均匀的分配到等价路由的多条路径或者聚合的多个成员端口转发,如果出现流量集中到1条或者其中几条路径转发,其他路径分配到很少的流量或者没有流量,即发生了负载分担不均。负载分担不均时,一是影响链路利用率,二是负载大的链路可能会导致业务异常。
优先调整本地ECMP或聚合HASH;本地调整无效时,调整上级设备的ECMP HASH算法,同时注意对下级设备的HASH影响。
建议按如下步骤调整:
(1) 排除HASH极化问题。HASH极化的处理建议请参考HASH极化。
(2) 调整哈希因子:总体原则为分析流量变化的因子,将HASH因子配置为变化丰富的项目,例如转发报文的MAC地址变化,而设置的负载分担方式为source-ip,则无法负载分担。另外分析流量从多个端口进入的还是从单个端口进来的,如果是从多个端口进入,可以增加ingress port作为HASH因子。
(3) 调整HASH算法。
(4) 调整Seed值。
(5) 调整Shift值。
(6) 调整成员端口数量,建议成员口总数为2的N次方。
HASH因子、HASH算法、Seed值、Shift值的配置方法请参考表10-1。
在负载分担不均时,可以通过调整HASH算法、seed值、shift值调整HASH计算结果。不同型号的产品支持情况有差异,具体的支持情况轻易设备实际情况为准。
表10-1 HASH负载分担调整命令
|
调整项目 |
ECMP HASH |
聚合HASH |
|
HASH因子 |
ip load-sharing mode |
link-aggregation global load-sharing mode(系统视图) link-aggregation load-sharing mode(接口视图) |
|
HASH算法 |
ip load-sharing mode per-flow algorithm |
link-aggregation global load-sharing algorithm |
|
Seed 当网络中存在多个厂商设备时,建议不同厂商配置为一致 |
ip load-sharing mode per-flow algorithm algorithm-number seed seed-number |
link-aggregation global load-sharing seed |
|
Shift 当网络中存在多个厂商设备时,建议不同厂商配置为一致 |
ip load-sharing mode per-flow algorithm algorithm-number shift shift-number |
link-aggregation global load-sharing offset |
HASH极化是指流量进行2次或2次以上HASH后出现的HASH不均匀的情况。如下情况中可能出现HASH极化:
· 第一级设备进行ECMP HASH,第二级再设备进行ECMP HASH;
· 第一级设备进行ECMP HASH,第二级进行聚合HASH;
· 同一级设备,ECMP路径的其中一条或多条路径的出接口是聚合接口,流量先进行ECMP HASH,再进行聚合HASH。
如图10-1所示,SW1接收了2条流量,根据设备的负载分担配置可以将流量均匀的HASH到2个出接口。流量1(绿色标识)到达SW2后,如果SW2计算负载分担的方式和SW1一致或相似,可能出现流量仅HASH到部分接口,另外一部分接口完全HASH不到流量或流量很少的情况。SW3的情况类似。
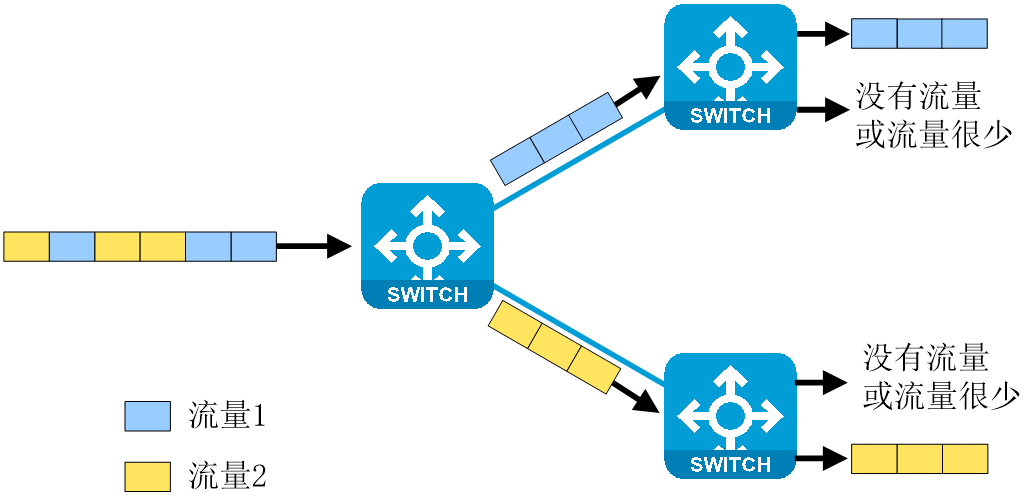
(1) 多级设备组网中,相邻级别设备避免采用HASH算法相同和相似的设备。
(2) 多级设备组网中,第一次HASH和第2次HASH配置不同的HASH算法/HASH因子。例如第一级设备采用算法1,第二级设备采用算法4;第一级设备基于源IP负载分担,第二级设备基于目的IP负载分担。
(3) 第1次HASH和第2次HASH的出接口数目互质。
例如:第1级设备进行聚合HASH,存在2条物理出接口,第2级设备进行ECMP HASH,存在3条物理出接口,2和3互质。
跨IRF成员设备ECMP或聚合的转发流程如图10-2所示。ECMP或聚合采用本地优先转发时,本地设备出接口间可以负载均匀,不同设备间成员口负载不均匀。ECMP或聚合关闭本地优先转发时,流量可在所有成员设备的出接口间负载均匀。但是由于部分报文会经过IRF链路再转发,会增加IRF物理链路负担。
数据中心交换机的ECMP和聚合本地优先转发功能缺省处于开启状态。
ECMP和聚合本地优先转发功能配置命令如下,需要时可以调整配置。
· ip load-sharing local-first enable(系统视图)
· link-aggregation load-sharing mode local-first(系统视图)
图10-2 跨IRF成员设备ECMP或聚合负载分担转发流程
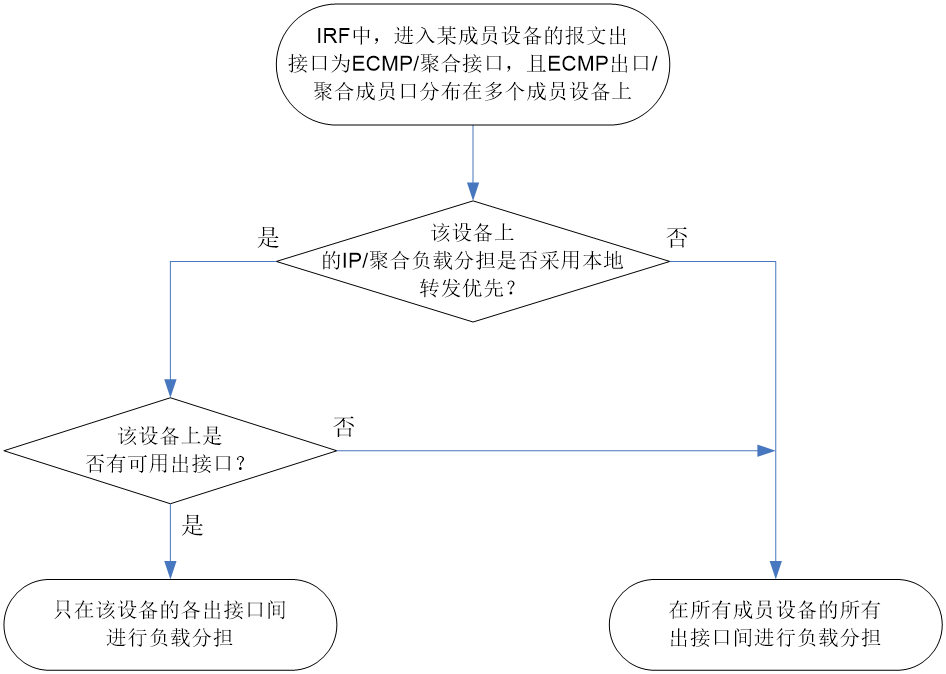
增加ECMP等价路径数目,或者聚合成员端口数量也可以改变负载分担结果。增加接口数量时,建议接口总数目为2的N次方。2的N次方个出口与报文发送周期的时隙更匹配,可以使负载分担更均匀。
本功能的支持情况请以设备的实际情况为准。
聚合弹性负载分担和等价路由增强功能类似,用于实现在聚合成员链路增加或减少时,尽量少的切换链路上的流量,只有部分流量进行链路切换。
例如,有一个聚合组中包含3条成员链路,根据聚合负载分担进行数据转发,其中一条链路故障无法转发数据时:
· 未配置弹性负载分担情况下另外两条链路会重新分配流量。
· 配置了弹性负载分担,另外两条链路上之前分配的流量不会发生变化,只是将故障链路上的流量大致均匀地分配到这两条链路上,这样对业务造成的影响较小。
当故障链路恢复后,会从这两条链路卸载一部分流量到故障恢复的这条链路上,各链路的流量分配和故障前流量分配也不会完全一致。
采用弹性负载分担后,如果链路没有增加或减少,则根据聚合缺省的负载分担方式对流量进行负载分担。
聚合弹性负载分担配置命令为:link-aggregation load-sharing mode resilient(聚合接口视图)。
开启对称HASH功能后,同一条数据流的往返报文将负载分担到同一条路径。
在某些场景下,例如交换机旁挂两台Firewall对流量进行安全防护,交换机HASH流量给两台Firewall,两台Firewall各自为自己负责的流量(占总流量的一半)建立了session;返程流量到达交换机时将被再次HASH分发,如若返程HASH分发与去程HASH分发不一致(不对称),则Firewall上会重复建立session,不仅浪费了Firewall的资源,而且对流量的安全防护做得不够准确。在该场景下,需要启用“对称HASH”以保证双向流量走相同的链路。
图10-3 交换机旁挂防火墙上行流量和下行流量对称HASH(一)
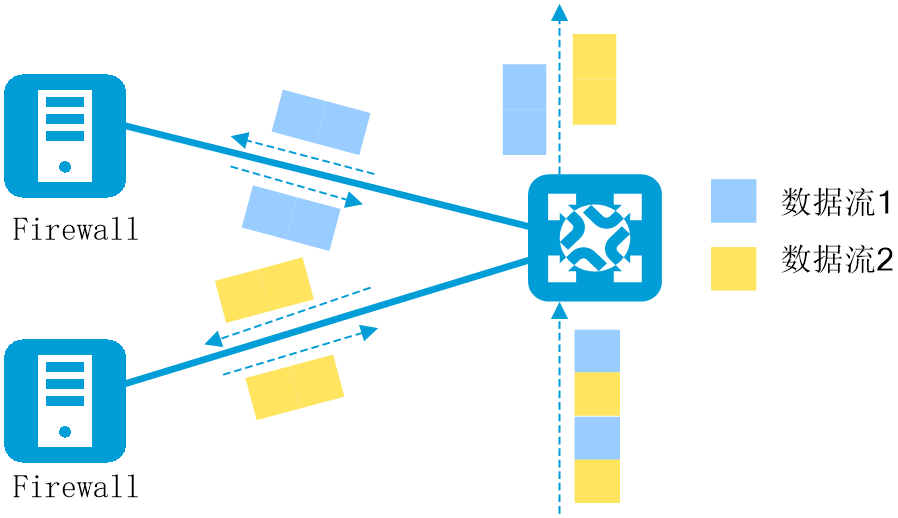
图10-4 交换机旁挂防火墙上行流量和下行流量对称HASH(二)
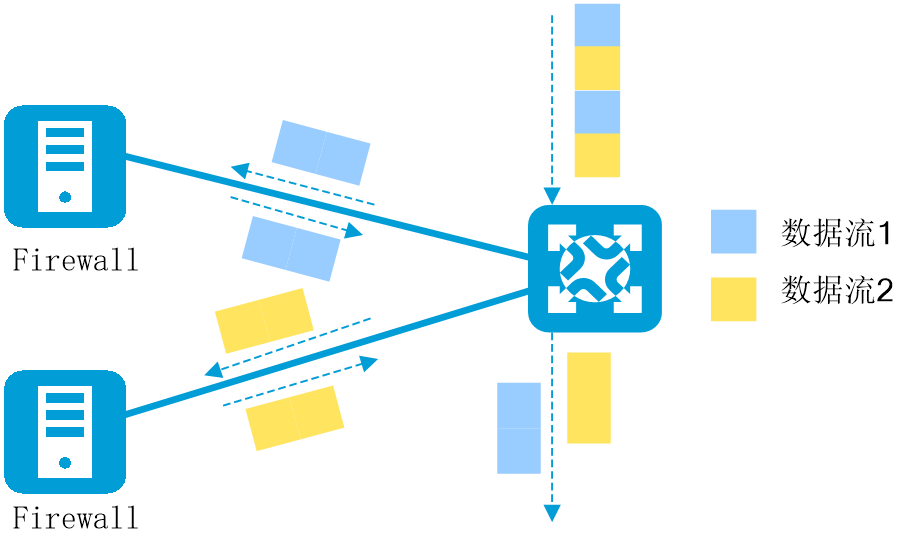
对称HASH的配置命令为ip load-sharing symmetric enable(系统视图)。
光模块用于光信号的传输,传输媒质为光纤。光纤传输方式损耗低,传输距离远,在长距离传输方面具有很强的优势。光模块又叫做光收发一体模块,简称为光模块英文名称叫Transceiver即Transmitter+Receiver。
H3C设备支持多种封装类型的光模块,如QSFP-DD、QSFP28、CFP、CFP2、CXP、QSFP+、SFP28、SFP+和SFP等。
以SFP封装光模块为例,主要包含光发射组件(TOSA)、光接收组件(ROSA)、电路板(PCBA)、光纤接口和外壳等。
光信号和电信号转化过程如下:
· 在发送方向,PCBA上的驱动芯片驱动激光器芯片发光,将从交换机、路由器等网络设备上接收的数据信息调制到特定波长的光上传输出去,实现电光转换;
· 在接收方向,对端传输过来光信号经过光探测器产生变化的电流信号,再经过跨阻放大器TIA转化成包含数据信息的电压信号,处理后发给后端PHY/MAC芯片,完成光电转换。
光模块位于物理层,不同类型光模块的物理层架构类似,以下以400G光模块为例进行介绍。
图11-2中架构图(1)是以太网IEEE802.3中定义的400G以太网物理层的架构,架构图(2)和架构图(3)分别对应400G光模块无PHY芯片和有PHY芯片物理层架构。
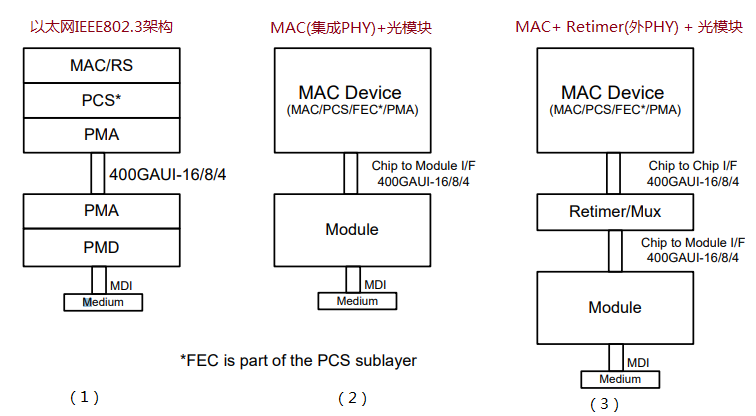
通过上图可知:光模块工作在物理层中的PMD子层,同时包含PMA层的部分功能(部分光模块只有PMD子层),不涉及到PCS层的编解码。也就是说光模块不会选择性的收发报文或消息,只负责传输比特流,并不关注发的比特是“0”还是“1”。
光模块有可插拔光模块和不可插拔光模块,本手册主要介绍的是可插拔光模块。
可插拔光模块有多种分类方法,最常见的是按照封装或速率类型分类,100G及以上速率光模块和线缆如表11-1所示。
表11-1 光模块和线缆类型
|
光模块及线缆类型 |
接口类型 |
传输速率 |
|
|
QSFP-DD模块 |
QSFP-DD光模块 |
LC接口 |
400Gbps |
|
QSFP-DD光模块 |
MPO接口 |
400Gbps |
|
|
QSFP-DD电缆 |
- |
400Gbps |
|
|
QSFP56模块 |
QSFP56光模块 |
MPO接口 |
200Gbps |
|
QSFP56光模块 |
LC接口 |
200Gbps |
|
|
QSFP56电缆 |
- |
200Gbps |
|
|
QSFP56 to QSFP56电缆 |
200Gbps |
||
|
QSFP56光缆 |
200Gbps |
||
|
QSFP28模块 |
QSFP28光模块 |
MPO或LC接口 |
100/50Gbps |
|
QSFP28 BIDI光模块 |
LC接口 |
100Gbps |
|
|
QSFP28电缆 |
- |
||
|
QSFP28光缆 |
|||
|
CFP模块 |
100G CFP光模块 |
LC接口 |
100Gbps |
|
40G CFP光模块 |
40Gbps |
||
|
CFP2模块 |
CFP2光模块 |
MPO接口或LC接口 |
100Gbps |
|
CXP模块 |
CXP光模块 |
MPO接口 |
100Gbps |
|
CXP光缆 |
- |
||
按照传输距离可细分规格或类型:一般短距在500m以内的光模块,多为多模光模块;长距在10km~40km之间或超长距在40km以上的光模块,为单模光模块。
更多H3C光模块的详细信息,请见参见《H3C光模块手册》。
光模块的诊断功能是工程与技术人员维护光链路正常运行最重要的维护手段。
光模块常见诊断项目包括:温度、电压、发送偏置电流、发送光功率与接收光功率。
|
诊断项 |
详细描述 |
正常工作范围 |
偏差 |
备注 |
|
Temperature |
模块外壳温度 |
商温模块:0~70℃ 工温模块:-40~85℃ |
±3℃ |
- |
|
Voltage |
模块电源电压 |
3.135~3.465V |
±3% |
由单板二次电源提供 |
|
TX Bias |
发送偏置电流 |
由激光器芯片决定 |
±10% |
驱动激光器发光 |
|
TX Power |
发送光功率 |
不同模块不一样,具体见《H3C光模块手册》 |
±3dB |
仅在正常工作范围内确保准确性 |
|
RX Power |
接收光功率 |
不同模块不一样,具体见《H3C光模块手册》 |
±3dB |
仅在正常工作范围内确保准确性 |
· Temperature:光模块壳温,单位为℃。商业温度光模块规格温度为0~70℃,工业温度光模块规格温度为-40~85℃;光模块只有工作在温度规格范围内才能保证数据传输的可靠性,诊断温度是否正常需要结合环境温度判断。
· Voltage:光模块供电电压,一般为3.3V±5%,由单板二次电源提供。
· TX Bias电流:驱动激光器发光的电流,单位为mA。不同类型的激光器电流大小不同。采用VCSEL激光器的多模光模块的TX Bias电流一般在10mA以下,而单模光模块一般相对较大。
· TX Power:光模块发送光功率,单位为dBm。正常工作状态下非常稳定,出现如下情况,基本可以确认模块硬件故障:
¡ 温度稳定状态下发生偏差±3dB以上的变化。
¡ 无发光时TX Bias电流正常。
· RX Power:光模块接收光功率,单位为dBm。在模块正常接收功率范围内准确性较好,偏差小于±3dB。当RX Power过高或者过低、RX LOS在告警状态下,使用display transceiver diagnosis命令读取的的功率数据可能不准确。
接收光功率过低通常可以排查如下问题:
¡ 对端光模块发送问题,如光模块存在故障,光口有异物等。
¡ 中间光链路问题,如光纤传输距离过长,光纤质量差。
¡ 本端光模块接收问题,如光模块存在故障,光口有异物等。
接收光功率过高常见于传输距离在10km以上的光模块。通常可以传输链路中增加光衰来解决。如增加足够光衰或拔掉光纤依然有告警,则模块可能已损坏。
目前大多数光模块都支持光模块的诊断功能,但也有例外。如电缆、电口光模块,这些光模块内部没有光器件,所以不支持光功率查看;早期由于技术原因,部分有源光缆(AOC)、QSFP-40G-BIDI-SR-MM850光模块也不支持。
告警是指当光模块内部芯片检测到不同程度的异常、或是模块状态发生重大改变时,自动产生警告信息,用来预测风险或标识故障的功能。告警有两种上报方式:
· 硬件:通过中断或专用硬件管脚上报,如SFP系列光模块的RX LOS和TX FAULT、QSFP系列光模块的IntL。
· 软件:模块自动产生告警,并更新符合MSA标准定义的寄存器取值,告警寄存器记录的是当前或历史时刻发生的异常。实际应用中需要主机通过管理接口轮询对应地址的寄存器告警标志位,以获取具体的告警内容,并及时保存时间戳。
告警类型主要包含诊断相关告警和故障告警:
· 诊断相关告警:诊断相关告警是指模块根据表11-2中的5个诊断功能,结合模块出厂设定的阈值进行判断产生的告警。这类告警一般通过软件的方式上报,包含warning和alarm两个级别。Warning是较轻的告警,不是一定会产生故障,以预警为主;而alarm则是较严重的告警,大概率无法保证链路长期稳定的工作。基于历史策略方面原因,目前H3C软件绝大部分版本中只支持alarm级别的告警,仅少数版本支持warning级别的告警。由于这类告警依赖于诊断,因此不支持诊断功能的模块也不会产生此类告警。
· 故障告警(模块内部感知到明确故障时产生的告警),主要包括:
¡ 40G光模块新增了TX LOS告警,表示光模块没有收到设备发出的电信号。
¡ 25G及100G以上的光模块新增了TX&RX LOL(Loss of lock)/CDR unlock告警功能。TX LOL表示光模块无法从设备发出的电信号中恢复出时钟,RX LOL表示无法从接收的光信号中恢复出时钟。
当查询到上述故障类告警时,链路一般都存在严重的故障,可能伴随有CRC或者端口UP/DOWN震荡,甚至无法Link UP。
不同封装类型光模块的故障告警功能一般性支持情况如下所示,指定传输距离的光模块具体支持哪些告警建议向技术人员单独进行确认。
表11-3 光模块故障告警
|
模块类型 |
接口速率 |
DDM相关告警 |
故障告警 |
备注 |
|
SFP/ESFP |
GE及以下 |
支持 |
TXFAULT/RXLOS |
- |
|
SFP+ |
10G |
支持 |
TXFAULT/RXLOS |
- |
|
SFP28 |
25G |
支持 |
TXFAULT/RXLOS CDR unlock(仅软件) |
- |
|
QSFP+ |
40G |
支持 |
TXFAULT TXLOS RXLOS |
仅支持软件方式告警 早期模块不支持TX POWER相关告警 |
|
QSFP28 |
100G |
支持 |
TXFAULT TXLOS RXLOS TXLOL RXLOL |
仅支持软件方式告警 LOL等同于CDR UNLOCK |
|
CFP/CFP2 |
100G |
支持 |
TXFAULT TXLOS RXLOS TXLOL RXLOL |
实际字符略有差异 硬件支持可编程告警 |
|
QSFP-DD |
400G |
支持 |
TXFAULT TXLOS RXLOS TXLOL RXLOL |
仅支持软件方式告警 |
包含光模块信息、项目信息、故障信息以及现场所做的一系列定位操作,收集的信息越充分,对分析定位的帮助越大。
主要包括故障链路两端光模块的条码、类型、诊断、告警以及寄存器信息。同时还可以收集光模块照片,用于辅助判断光模块真伪。
![]()
以下命令在不同设备上的支持情况可能不同,具体以设备实际支持情况为准。
通用光模块信息收集命令如表11-4所示。
|
操作 |
命令 |
备注 |
|
显示可插拔接口模块的主要特征参数 |
display transceiver interface interface-type interface-number |
- |
|
显示可插拔接口模块的电子标签信息 |
display transceiver manuinfo interface interface-type interface-number |
- |
|
显示可插拔光模块的数字诊断参数的当前测量值 |
display transceiver diagnosis interface interface-type interface-number |
温度读数允许误差为±3°C;光功率读数允许误差为±3dB |
|
显示可插拔接口模块的当前故障告警信息 |
display transceiver alarm interface interface-type interface-number |
此命令行记录的是历史告警信息,而不是实时状态;由于主机软件底层不停轮询告警和诊断用于更新网管MIB信息,而该操作会导致故障记录被自动清除,因此该命令行显示结果只有在故障状态持续存在时是准确的 此命令行需要快速连续读2遍以上,第一遍为无效结果需要被读清 |
|
显示光模块的详细信息(适用于Comware V7及以上版本) |
display transceiver information interface interface-type interface-number |
probe视图下执行 |
|
显示光模块的详细信息(适用于Comware V5及以下版本) |
display transceiver interface interface-type interface-number |
hidecmd视图执行 |
|
显示可插拔光模块软件内部的核心数据结构的信息 |
display transceiver moduleinfo interface interface-type interface-number |
本命令适用于Comware V7及以上版本,需要在probe视图下执行 |
对于QSFP+/QSFP28系列光模块,可在probe视图下执行如下命令收集寄存器信息。
表11-5 收集QSFP+/QSFP28系列光模块寄存器信息相关命令
|
操作 |
命令 |
备注 |
|
显示指定接口光模块上内部寄存器的索引号为0、起始地址为0、长度为128的寄存器区域的内容 |
display hardware internal transceiver register interface interface-type interface-number device 0 address 0 length 128 |
Probe视图下执行 此命令行需要快速连续读2遍以上,第一遍为无效结果需要被读清 |
|
显示指定接口光模块上内部寄存器的索引号为0、起始地址为80、长度为128的寄存器区域的内容 |
display hardware internal transceiver register interface interface-type interface-number device 0 address 80 length 128 |
Probe视图下执行 |
|
显示指定接口光模块上内部寄存器的索引号为3、起始地址为80、长度为128的寄存器区域的内容 |
display hardware internal transceiver register interface interface-type interface-number device 3 address 80 length 128 |
Probe视图下执行 |
对于SFP/SFP+/SFP28系列光模块,可在probe视图下执行如下命令收集寄存器信息。
表11-6 收集SFP/SFP+/SFP28系列光模块寄存器信息
|
操作 |
命令 |
备注 |
|
显示指定接口光模块上内部寄存器的索引号为a0、起始地址为0、长度为128的寄存器区域的内容 |
display hardware internal transceiver register interface interface-type interface-number device a0 address 0 length 128 |
Probe视图下执行 |
|
显示指定接口光模块上内部寄存器的索引号为a2、起始地址为0、长度为128的寄存器区域的内容 |
display hardware internal transceiver register interface interface-type interface-number device a2 address 0 length 128 |
Probe视图下执行 此命令行需要快速连续读2遍以上,第一遍为无效结果需要被读清 |
对于CFP/CFP2系列光模块,可在probe视图下执行如下命令收集寄存器信息。
表11-7 收集CFP/CFP2系列光模块寄存器信息
|
操作 |
命令 |
备注 |
|
显示指定接口光模块上内部寄存器的索引号为0、起始地址为8000、长度为128的寄存器区域的内容 |
display hardware internal transceiver register interface interface-type interface-number device 0 address 8000 length 128 |
Probe视图下执行 |
|
显示指定接口光模块上内部寄存器的索引号为0、起始地址为a000、长度为128的寄存器区域的内容 |
display hardware internal transceiver register interface interface-type interface-number device 0 address a0000 length 128 |
Probe视图下执行 此命令行需要快速连续读2遍以上,第一遍为无效结果需要被读清 |
|
显示指定接口光模块上内部寄存器的索引号为0、起始地址为a200、长度为128的寄存器区域的内容 |
display hardware internal transceiver register interface interface-type interface-number device 0 address a200 length 128 |
Probe视图下执行 此命令行需要快速连续读2遍以上,第一遍为无效结果需要被读清 |
|
显示指定接口光模块上内部寄存器的索引号为0、起始地址为a280、长度为128的寄存器区域的内容 |
display hardware internal transceiver register interface interface-type interface-number device 0 address a280 length 128 |
Probe视图下执行 |
|
显示指定接口光模块上内部寄存器的索引号为0、起始地址为a280、长度为128的寄存器区域的内容 |
display hardware internal transceiver register interface interface-type interface-number device 0 address a400 length 128 |
Probe视图下执行 此命令行需要快速连续读2遍以上,第一遍为无效结果需要被读清 |
对于QSFP-DD系列光模块,可执行如下命令收集信息。
表11-8 收集QSFP-DD系列光模块寄存器信息
|
操作 |
命令 |
备注 |
|
显示可插拔400G光模块的当前运行参数 |
display transceiver active-control interface interface-type interface-number |
Probe视图下执行 |
|
显示可插拔400G光模块支持的能力 |
display transceiver advertising interface interface-type interface-number |
Probe视图下执行 |
|
显示可插拔400G光模块支持的应用及相关信息 |
display transceiver application interface interface-type interface-number |
Probe视图下执行 |
|
显示可插拔400G光模块的状态信息 |
display transceiver status interface interface-type interface-number |
Probe视图下执行 正常工作时模块状态应当为ModuleReady,数据通道状态为Activated |
|
显示指定接口光模块上内部寄存器的索引号为0、起始地址为0、长度为128的寄存器区域的内容 |
display hardware internal transceiver register interface interface-type interface-number device 0 address 0 length 128 |
Probe视图下执行 此命令行需要快速连续读2遍以上,第一遍为无效结果需要被读清 |
|
显示指定接口光模块上内部寄存器的索引号为2、起始地址为0、长度为128的寄存器区域的内容 |
display hardware internal transceiver register interface interface-type interface-number device 2 address 80 length 128 |
Probe视图下执行 |
|
显示指定接口光模块上内部寄存器的索引号为10、起始地址为80、长度为128的寄存器区域的内容 |
display hardware internal transceiver register interface interface-type interface-number device 10 address 80 length 128 |
Probe视图下执行 |
|
显示指定接口光模块上内部寄存器的索引号为11、起始地址为80、长度为128的寄存器区域的内容 |
display hardware internal transceiver register interface interface-type interface-number device 11 address 80 length 128 |
Probe视图下执行 此命令行需要快速连续读2遍以上,第一遍为无效结果需要被读清 |
项目相关信息主要包括:
· 用户采购同型号光模块数量、实际上线使用数量、模块上线运行时间。
· 两端光模块分别插在什么设备上、中间链路是哪种光纤类型/相距多远、是否有传输设备等。
· 设备使用地点、机房建设情况,以判断是否存在高低温及潮湿环境或工业污染情况。
故障信息主要包括:
· 现象:端口CRC、端口不UP、端口UP/DOWN震荡、模块识别错误、模块信息无法读取等。
· 范围:同型号模块/端口/链路全部还是部分故障。
· 状态及频率:当前故障是否已消失/多久发生一次。
建议依次做一些基本的定位操作再申请备件更换,包括但不限于:
· 在不改变故障端口/模块工作状态前提下(即不对端口进行任何操作,也不插拔光模块),寻找额外的同型号光模块与故障端口/模块对接,用于确认故障发生在哪一侧。
· 使用短光纤外部环回,即直接将光模块的TX和RX光纤接口连接。如果故障消失,表示本端口工作正常。注意仅限传输距离在10km以下的光模块,超长距光模块严禁使用短光纤直接进行外部环回,否则可能会烧毁接收端器件。
· 端口内部环回功能排除后端芯片工作异常。配置内部环回后,故障消失,表示后端芯片工作正常。
· shutdown/undo shutdown端口/插拔光模块。
· 完整的交叉验证:问题端口更换同型号光模块,有问题的光模块放到其他端口验证。
· 使用清洁工具或其他专业仪器对光模块及光纤端面进行清洁。
其他信息的收集没有严格的条例,重点关注规律性的现象,比如:
· 光模块故障率的批次性差异。
· 端口故障有无设备相关性。
· 故障发生前,设备否有软件版本变更、光纤链路是否有进行过调整。
· 客户是否有部署链路监测系统记录光模块的诊断信息,并观察到参数的明显变化。
有时真相就隐藏在一些微小的线索当中,只要抓住,往往能够大幅提高分析定位的效率。
· 光模块与设备是否适配?
参考各产品光模块适配表。
· 客户光纤类型与模块类型是否匹配?
10G以上速率多模光模块建议使用水绿色的OM3多模光纤,如使用橙色的OM1多模光纤长度不得超过30m。
多模光模块不得使用亮黄色的单模光纤。
· 客户光纤极性是否正确?
极性用来保证模块发出的信号经过传输到达另一只模块的接收端,错误时两侧模块一般均无收光。
多芯MTP/MPO系统推荐使用B型(交叉)方法。
· 传输距离在40km以上的光模块是否存在短光纤对接?
使用40km以上光模块进行外环或短光纤对接会导致接收端烧毁,故障现象一般是恒定出现接收光功率过高,拔掉光纤也无法恢复。
· 一端模块发送波长与另一端模块接收波长是否匹配?
波长不匹配也可能导致收光异常的现象,尤其是采用BIDI和WDM技术的单模光模块。
· 两侧端口的配置(速率、双工模式、FEC)是否一致?
当不同厂家设备端口对接无法UP、端口外环或对接测试正常UP时应重点排查端口配置是否一致。
用户侧光口故障分析的前提条件是假定光模块已与H3C设备做过充分的适配测试。如果没有做过适配,则一切问题皆有可能。未与H3C设备进行过适配的光模块,主要是指客户自行采购的第三方光模块。下面是光模块一些常见问题的分析方法。
第三方光模块是指非H3C生产销售的光模块。这些模块方案设计千差万别,实际应用中可能与H3C设备存在一些兼容性问题。常见的问题有:模块不识别、寄存器无法访问、高速信号参数失配。
· 模块不识别
display transceiver interface显示信息中,Transceiver Type显示UNKNOWN_SFP_PLUS或者UNKNOWN_QSFP_PLUS等类似信息。这类问题一般在非MSA标准定义的特殊光模块类型,如AOC、ZR、BIDI、CWDM、DWDM等光模块上比较常见。原因一般是由于没有明确的行业标准规定,光模块厂家按照自己的理解进行设计,导致存在寄存器设置与H3C软件识别流程不匹配的情况。H3C销售的光模块寄存器是经过特殊定制的、与H3C软件识别流程相匹配的,所以不存在识别问题。
· 寄存器无法访问
设备通过SCL/SDA总线读写光模块寄存器,当上下拉电阻设置不合适、模块与设备的总线频率或时序不一致、或者遇到部分协议规定范围外的总线操作时,就可能出现光模块寄存器无法访问的故障现象。而光模块一般都无法自动恢复,可能需要手动插拔故障才能消除,严重时也可能会导致设备宕机。
· 高速信号参数失配
高速信号是用来传输数据业务的。相对SCL/SDA这样的低速管理信号,参数适配更为复杂。事实上H3C认证通过的大部分光模块都或多或少进行过一些信号调整,以确保在高低温等不同条件下都能够充分适配H3C绝大多数主机或板卡。而第三方光模块往往是一套默认的出厂参数,适配性肯定不如H3C光模块。即使前期做过一些小规模的测试,但很难覆盖到不同个体间的差异性,不能排除会存在部分模块与某些特定端口、甚至特定设备无法兼容的情况。
光模块命令行常见异常显示日志信息:
· The transceiver is absent
表示端口没有检测到模块插入,即光模块不在位。出现该日志后,可通过插进光模块来尝试解决,若光模块插进后,仍然存在问题,可能是光模块与端口之间的物理连接发生了故障,比如金手指接触不良。
· Transceiver info I/O error或Reading information from the transceiver failed
光模块与端口间的管理接口故障。此时光模块寄存器信息一般都不可访问,需要通过交叉验证分析原因。
![]()
交叉验证,即将异常光模块和接口与正常相同型号光模块和接口交叉互换,来判断具体是光模块故障还是设备接口故障。
· Transceiver info checksum error
Checksum error是光模块某些只读寄存器的值存在校验和错误,一般不影响业务。导致该问题有以下两种可能性:
¡ 光模块的只读寄存器被永久的改写了。
¡ 插入光模块时,软件没有读到正确的值。此种情况一般只需要在光模块稳定工作后重新读一下寄存器信息即可做出准确判断。
· The transceiver does not support this function.
表示不支持查看制造信息或诊断信息。导致出现该问题的可能性有两种:
¡ 光模块本身不支持,是正常现象。这些模块包括:
- 第三方光模块(设备软件未安装第三方光模块license)
- 电缆及少数光模块,具体型号请向H3C技术支持人员确认。
¡ 光模块某些寄存器信息被改写,被软件识别为第三方光模块或伪模块。这种情况建议将光模块返回H3C售后进行分析。
· 诊断电压异常
光模块正常工作的电压范围一般为3.135~3.465V之间。如果显示工作电压轻微超出正常工作电压时,可能与主板二次电源有关,可通过查看相邻物理端口的光模块电压是否存在相同现象判断。当显示工作电压超出正常工作电压较多时,说明电压诊断已经不准了,通常可以判断为光模块故障。
![]()
如果电压真的过低或过高,光模块内部器件工作异常,是无法读到任何诊断数据的。
# 显示接口GigabitEthernet1/0/1上插入的可插拔光模块的数字诊断参数的当前测量值。
<Sysname> display transceiver diagnosis interface gigabitethernet 1/0/1
GigabitEthernet1/0/1 transceiver diagnostic information:
Current diagnostic parameters:
Temp(°C) Voltage(V) Bias(mA) RX power(dBm) TX power(dBm)
36 3.31 6.13 -35.64 -5.19
Alarm thresholds:
Temp(℃) Voltage(V) Bias(mA) RX power(dBM) TX power(dBM)
High 50 3.55 1.44 -10.00 5.00
Low 30 3.01 1.01 -30.00 0.00
· 诊断温度异常。
光模块诊断温度与其被使用的环境温度有关。由于光模块功耗及设备散热设计差异,一般来说光模块的诊断温度会比环境温度高5~25℃。如果出现现实应用中不可能的温度值,一般是光模块故障。
· 发送偏置电流、光功率诊断数值超出告警范围。
发送偏置电流、发送光功率和接收光功率三项参数没有固定的正常工作范围,不同型号有所不同。
发送偏置电流与发送光功率都用于对发送端器件的监控。正常工作时光模块的发送光功率大小主要与温度有关,温度恒定时发光功率一般不会有较大变化,因此如果发光功率明显降低则说明光模块可能已经发生一定程度的失效。发送偏置电流与发送光功率线性相关,因此如果发现发光功率正常而发送偏置电流超出范围也可以判定为光模块故障。TX Bias明显的异常值一般<3mA,关光时除外。
· 接收光功率诊断数值超出告警范围。
接收光功率理论上等于对端发光功率减去链路损耗,收光超出范围可能是对端光模块发送故障、链路故障或者本端光模块接收故障,经验上以对端发送故障相对概率较高。对于多通道LC接口的光模块,由于共享同一条链路,如果链路故障,一般所有通道都会收光异常;如果是模块故障,一般只有少数通道收光异常。
· 诊断光功率显示-36.96dBm或-40dBm。
-36.96dBm或-40dBm一般被认为是无光,只要光模块支持光功率诊断功能,正常应用中不会出现这样的数值。
如果发光是该数值,要确认是否存在“关光”的条件,包括端口是否shutdown、模块是否进入“低功耗”、“故障”或“静噪”(单板无电信号输出时模块不发光)状态。
如果收光是该数值,并不一定是完全“无光”:当接收光功率低于某个值时,已经远远超出了光器件接收能力,此时寄存器只能按照一个最小值及-36.96dBm或-40dBm显示;当接收光功率高于某个值时,也可能会触发保护机制将光器件“关断”,此时光器件也无法再接收,这种情况常见于40km以上光模块。
· 40G和100G多通道光模块通道间光功率差异过大。
40G速率以上的光模块大多包含多路光,一般来说H3C光模块每一路的收发光功率会在出厂时自动调校好,不同的通道间相差一般不会很大,这个差值没有固定的标准,不同类型光模块要求具体值也不一样。
如果发现不同通道间的发光功率差值超过3dB以上,可能存在一定的器件失效风险,请收集模块的条码及诊断信息后向H3C技术人员确认。
对于不同通道间的接收光功率差值超过3dB的情况,要具体问题具体分析。对端模块发送故障、光纤异常或者本端接收侧故障都是有可能的。
· 存在任何告警信息。
端口正常UP过程中不应该产生任何的告警信息,如发现光模块存在告警应及时排查两侧设备、模块以及链路中可能存在的问题,尽可能将所有的告警消除。尤其要重视high alarm等告警类型,像温度、电压、接收光功率过高告警可能导致模块永久性损坏。
光模块的所有信息基本上都是从寄存器原始数据中解析得到的。综上所述,异常情况主要包括如下几种类型:
· 寄存器接口硬件故障导致寄存器不可读。
硬件故障最常见的现象是诊断、告警及寄存器信息不可读,如display transceiver diagnosis interface和display transceiver alarm interface命令行返回Transceiver info I/O error或Reading information from the transceiver failed。这种情况下只要通过交叉验证就可以判断是端口还是模块故障。
对于display transceiver interface、display transceiver manuinfo interface、display transceiver information interface、display transceiver moduleinfo interface命令行,仍然可能在接口故障时正常显示,原因是这部分信息并不是实时读取,而是在模块插入时缓存的,只有在检测到模块插拔时才会清除或更新缓存。
· 软件问题导致读取的原始数据不正确或解析处理错误。
软件包括网络设备软件与光模块固件:
¡ 网络设备软件主要是把从寄存器中读到的原始数据“翻译”成与光模块相关的参数信息,比如波长、发送接收光功率等。当设备软件访问光模块的时机/方式不正确、或“翻译”的方法有误时,很容易得到错误的数据,此时升级设备软件就能解决问题。错误的设备软件操作还可能导致光模块寄存器数值被永久性的改写,如出现日志Transceiver info checksum error或提示“NOT sold by H3C”就可能属于这种情况。
¡ 光模块本身并不是纯硬件,大部分光模块都是有固件运行。当固件存在运行错误时,就可能出现像上面电压、温度、光功率等值明显不符合逻辑的现象。一般来说,此类问题发生的概率非常低,而且都是在长时间运行后出现,手动插拔一下故障现象就会消失。由于绝大多数光模块本身不支持在线升级,如果用户无法接受,也可以按照硬件故障的方式进行更换。
链路“闪断”问题一般是指端口在正常工作中出现的瞬时DOWN掉后马上又恢复正常UP的事件。之所以单独说明是由于客户现场这类问题的复现往往有较大的随机性,并且介入定位时故障现象大概率已经消失,一般无法及时抓取或保存故障时刻的光模块和端口状态快照,给问题分析定位带来了很大的困难。模块相关分析除了11.7 故障相关信息的收集提到的故障信息收集方法外,建议在系统侧对光模块和端口进行持续的参数及状态监控:
· 监控包含故障发生时刻前后的光模块诊断数据,重点观察光功率是否有明显的变化;
· 监控光模块告警记录,确认告警产生的时间与“闪断”时间是否一致;
如果用户没有条件进行上述操作,请联系H3C技术支持工程师进行定位处理。
光模块最大传输距离是在满足特定光纤衰减系数以及一定数量的接头衰减条件下计算出来的相对值。不同光纤的衰减系数、接头衰减均存在差异。如果客户用的是低损光纤,那么使用传输距离为10km的光模块有可能传输距离达到20km。反之如果客户使用的光纤质量较差,那么使用传输距离为10km的光模块有可能都无法达到10km传输距离。
我们可通过如下2个公式来评估光模块能否使用:
光纤链路衰减 = 光纤衰减 + 所有接头衰减
· 光纤衰减 = 光纤长度*光纤衰减系数。以太网IEEE802.3标准定义如下:多模光纤在850nm波长附近的衰减系数为3.5dB/km;G.652单模光纤在1310nm波长附近的衰减系数为0.4~0.5dB/km,一般取0.45dB/km;G.652单模光纤在1550nm波长附近的衰减系数一般取0.25dB/km。建议客户向供应商确认光纤衰减系数。
常见光纤光衰参考值如下所示:
¡ 100m OM3/OM4光纤在850nm波长附近参考光衰值为1dB左右。
¡ 10km单模光纤在1310nm波长附近参考光衰为4.5dB左右。
¡ 40km单模光纤在1550nm波长附近参考光衰为8~11dB 。在1310nm波长附近的参考光衰为18dB。
· 接头衰减,接头包含光纤连接器、冷(机械)接点和熔接点三种类型。单模光纤连接器一般按照0.5dB每个计算,多模光纤连接器最大不应当超过0.75dB,其他接头应当小于0.5dB。
![]()
以上只是理论计算,具体以实际为准。工程上可以使用光时域反射计(OTDR)准确测量跨段及接头的数量、衰减和反射情况。
光模块功率预算 = 对端光模块发送光功率 – 本端光模块最小接收光功率(接收灵敏度)
只有当光模块功率预算 – 光纤链路衰减 > 功率代价时,传输才是可靠的。功率代价是指光模块为克服一定程度的链路损伤需要额外付出的功率,工程上也称之为裕量,一般按照3dB计算。
光纤及光模块端面对脏污非常敏感,纤芯及纤芯周边大面积的脏污不仅会导致插入损耗的增加,也会引起较大的反射产生回波损耗。图11-3是干净与各种不同类型脏污下光纤连接器端面的对比。

光纤与光模块端面主要有干、湿两种清洁方法,建议两种方法结合使用:
· 干法最为常用且效率较高,但可能产生静电而吸附细小的颗粒物或毛发纤维。
· 湿法是使用酒精等溶剂,对附着力较强的固态物质或油脂清洁效果更好。
端面清洁包含多种工具,适合现场小规模清洁的主要包括清洁纸、清洁布、棉签、清洁笔、清洁盒、压缩气体清洁剂等。
图11-4 光模块清洁工具

清洁纸、清洁布、清洁盒可以用来清洁光纤端面。
图11-5 光纤端面清洁(一)
图11-6 光纤端面清洁(一)

清洁笔不仅可以清洁光纤,也可以清洁光模块,下图是使用MPO/MTP清洁笔清洁光纤及模块端面的示例,LC型光纤和光模块与此类似。
图11-7 光模块清洁(一)

图11-8 光模块清洁(二)

部分光模块由于成本原因去掉了插芯,使用端面检测仪可以直接看到光芯片,如图11-9所示。

对于去掉插芯的光模块,当内端面脏污,清洁笔的作用就非常有限了,推荐使用压缩气体清洁剂,或借助更专用的端面清洗系统进行清洁。
光模块发送光功率经过光纤传输衰减后的实际光功率在对端光模块的正常接收光功率范围之内是能够对接的必要条件之一。外环或者短光纤对接时光纤的衰减基本可以忽略,因此只要光模块的最大发送光功率小于等于最大接收光功率,就可以满足对接要求。
不一定,绝大多数错误检测都是在接收端进行的。报文从发送端发出,经过传输路径,最后到接收端,整条路径上任意一个位置异常都可能导致接收端检测到错误。因此,不论是CRC错误还是Local Fault,甚至是光模块上报的RX LOS,都无法指明故障位置所在。
CRC错误是MAC层对接收到的报文进行CRC算法校验后发现错误报文的计数。Local Fault是RS子层检测到接收的数据中包含特定格式的序列,用来指示对端发送到本端接收方向存在的故障。
当光模块故障时,可能产生CRC错误,也可能产生Local fault(即端口UP/DOWN震荡或者端口不UP)。端口CRC错误与Local Fault都表示通信中的不可靠链接,但都不是直接对光模块传输的信号或数据进行检测得到的结果,因此也不能说明故障与本端光模块直接相关。
H3C光模块制造信息(包含条码、生产日期等)是按照H3C企业标准定义的,在MSA通用标准外的其他存储区域通过加密算法二次写入的电子标签信息。而友商仅能按照MSA通用标准读取通用信息,两个信息的格式定义、存储地址都不相同,软件版本中没有解密算法是无法解析出有效信息的。
千兆电口光模块内部没有空间存放H3C制造信息,读不到是正常的。
对于40G和100G光模块,display transceiver diagnosis命令行显示的是每个光通道的光功率,单位是dBm。工程上通常使用光功率计来测量链路中各个位置的光功率大小,单位可以自由选择dBm或者mW。
由于40G和100G长距光模块通过波分复用技术将波长为1310nm附近的4路光合并到一根光纤里传播,因此直接用光功率计测试的结果是4个光通道的总功率,光模块总功率等于所有通道的光功率算数和。计算光模块总功率前,需要将功率由计量单位dBM转化为mW,然后再进行求和。
dBm与mW之间的转换公式为:![]() 。
。
如果各个通道的光功率相差不大,那么总功率(dBm)≈每个通道的光功率(dBm)+6。
100G短距光模块,多采用MPO接口,主要配合如下三种光纤连接器使用,如图11-10。
图11-10 MPO连接器

类型一光纤连接器可容纳2排、共计24根纤芯,主要配合100GBASE-SR10光模块使用,常见的封装形式有CXP/CFP/CFP2。
类型二光纤连接器可容纳1排12根纤芯,类型三光纤连接器可容纳1排8根纤芯,两者间的差异只是在中间位置是否有4根额外的纤芯。QSFP光模块内部光纤连接器不使用中间4芯,所以类型二和类型三都可以应用于QSFP封装类型的光模块,类型三比类型二节约33%的纤芯。













